16강. 갱신은 효율적으로
- SQL 은 질의. 즉, 검색에 초점이 맞춰진 언어
- 검색에 비해 갱신은 상대적으로 비효율적이고 성능이 떨어지는 경향
예제
- 같은 keycol 필드 가짐
- 현재 레코드보다 작은 seq 필드 가짐
- val 필드가 NULL이 아님
NULL 인 곳을 채우기
- 입력 횟수를 줄이고자 null 값을 넣어 생략하는 경우 존재
- 하지만, null 값이 있는 경우 기능 구현에 여러 애로사항이 생길 수 있으므로 채워주는 것이 좋음
update omittbl
set val =
(select val
from omittbl ot1
where ot1.keycol = omittbl.keycol
and ot1.seq = (select max(seq) -- 현재 레코드보다 작은 seq 중에 최고 seq를 구함
from omittbl ot2
where ot2.keycol = omittbl.keycol
and ot2.seq < omittbl.seq
and ot2.val is not null))
where val is null;
- 데이터량이 적을 때는 테이블 seq scan 수행
- 데이터량 늘어나면 기본 키 인덱스 활용 가능
- 반복계보다 높은 성능 향상성
NULL 로 채우기
update omittbl
set val = case when val
= (select val
from omittbl o1
where o1.keycol = omittbl.keycol
and o1.seq = (select max(seq)
from omittbl o2
where o2.keycol = omittbl.keycol
and o2.seq < omittbl.seq))
then null
else val end;- 서브쿼리가 스칼라 서브쿼리(하나의 값을 리턴하는 쿼리)이기 때문에 가능
27강. 레코드에서 필드로의 갱신
- 2개 테이블 사용 → 한쪽 테이블 정보 편집 + 다른 테이블로 복사 : update
1. 필드를 하나씩 갱신
- 한 과목씩 갱신하는 SQL
- 3개의 상관 서브쿼리 실행 필요 → 성능 좋지 않음
- 갱신하고 싶은 과목이 늘어날 때마다 상관 서브쿼리 양이 늘어남.
update scorecols
set score_en = (select score from scorerows sr
where sr.student_id = scorecols.student_id and subject = 'en'),
score_nl = (select score from scorerows sr
where sr.student_id = scorescols.student_id and subject = 'kr'),
score_mt = (select score from scorerows sr
where sr.student_id = scorescols.student_id and subject = 'mt');2. 다중 필드 할당 (Multi Fields Assignment)
- 여러 필드 리스트화해 한 번에 갱신
- 서브쿼리 한 번에 처리 가능
- 성능, 가독성, 확장성 향상
- scorerows 테이블에 대해서 한 번만 접근
- index unique scan → index range scan
- max 함수 정렬
- 하지만 효율적인 트레이드오프
다중 필드 할당
- 세 개의 필드를 리스트 형식으로 지정
- 리스트 전체를 하나의 조작 단위로 수행
스칼라 서브쿼리
- 각 점수에 max 함수 적용
- 집약해야 하나의 값만 리턴하는 스칼라 서브쿼리가 됨
update scorecols
set (score_en, score_nl, score_mt)
= (select max(case when subject = 'en' then score else null end) as score_en,
max(case when subject = 'kr' then score else null end) as score_nl,
max(case when subject = 'mt' then score else null end) as score_mt
from scorerows sr
where sr.student_id = scorecols.student_id);NOT NULL 제약이 걸려있는 경우
- UPDATE 구문 사용
-
처음부터 테이블 사이에 일치하지 않는 레코드가 존재한 경우
- 레코드 갱신 대상 제외
-
학생은 존재하지만 과목이 없는 경우
- 레코드는 존재하지만 필요한 필드가 없는 경우
- COALESCE 함수로 null을 0으로 변경해서 대응
- 주어진 매개변수 중 좌측부터 Null 이 아닌 값 리턴
- 모두 Null 이면 우측 기본값 리턴update scorecols set = (score_en, score_nl, score_mt) = (select coalesce(max(case when subject = 'en' then score else null end), 0) as score_en, coalesce(max(case when subject = 'kr' then score else null end), 0) as score_kr, coalesce(max(case when subject = 'mt' then score else null end), 0) as score_mt from scorerows sr where st.student_id = scorecols.student_id where exists (select * from scorerows where student_id = scorecols.student_id);
-
- MERGE 구문 사용
-
update 때는 두 장소에 분산되어 있던 결합 조건을 on 구로 한 번에 끝낼 수 있음
-
테이블 풀 스캔 1회 + 정렬 1회
- 갱신 필드 늘어나도 변경 없음
- 성능 악화 염려 없음merge into scorecols using (select student_id, coalesce(max(case when subject = 'en' then score else null end), 0) as score_en, coalesce(max(case when subject = 'kr' then score else null end), 0) as score_kr, coalesce(max(case when subject = 'mt' then socre else null end), 0) as score_mt from scorerows group by student_id) sr on scorecols.student_id = sr.student_id when matched then update set scorecols.score_en = sr.score_en, scorecols.score_kr = sr.score_kr, scorecols.score_mt = sr.score_mt;
-
28강. 필드에서 레코드로 변경
- 테이블에 대한 접근은 한 번뿐
- 기본 키 인덱스 사용
- 정렬, 해시 X
update scorerows
set score = (select case scorerows.subject
when 'en' then score_en,
when 'kr' then score_kr,
when 'mt' then score_mt
else null
end
from scorecols
where student_id = scorerows.student_id);29강. 같은 테이블의 다른 레코드로 갱신
- 같은 테이블 내부의 다른 레코드 정보 바탕으로 연산 결과 갱신하는 경우
- trend : 이전 종가, 현재 종가 비교해서 증감 여부 표시
- 각 종목 첫 거래 날은 Null
1. 상관 서브쿼리 사용
- sign 함수
- 매개변수 숫자가 양수(1), 음수(-1), 0(0) 리턴하는 부호 조사 함수
insert into stock
select brand, sale_date, price,
case sign(price -
(select price
from stock s1
where brand = stock.brand
and sale_date =
(select max(sale_date)
from stocks
where brand = stocks.brand
and sale_date < stocks.sale_date)))
when -1 then '↓'
when 0 then '↑'
when 1 then '→'
else null
end
from stocks2. 윈도우 함수 사용
- 실행계획 좋아짐
- 테이블 풀 스캔 1회로 감소
insert into stock
select brand, sale_date, price,
case sign(price -
max(price) over (partition by brand
order by sale_date
rows between 1 preceding and 1 preceding))
when -1 then '↓'
when 0 then '↑'
when 1 then '→'
else null
end
from stocks3. insert select 와 update 중 무엇?
insert select
- 일반적으로 update 에 비해 성능 우세 → 고속 처리 가능
- MySQL 처럼 갱신 SQL에서 자기 참조 불허하는 데이터베이스에서도 사용 가능
update
- 같은 크기, 구조 가진 데이터를 두 개 만들어야 함
- 저장소 용량 아까움 → 근데 요즘은 싸져서 괜찮을지도?
30강. 갱신이 초래하는 트레이드오프
- Orders : 주문 하나에 대응하는 테이블
- OrderReceipts : 주문 제품 하나에 대응하는 테이블
- 주문일과 상품 배송예정일 차이를 구해 3일 이상이면 주문자에게 알림 기능
1. SQL 사용하는 방법
- 주문일 - 배송 예정일 관계를 SQL 로 찾기
- 결합 or 집약 사용할 가능성 높음
- 실행계획 변동 위험
-- 주문일 배송 예정일 차이
select o.order_i, o.order_name, orc.del_date - o.order_date as diff_days
from orders o
inner join orderreceipts orc on o.order_id = orc.order_id
where orc.del_date - o.order_date >= 3;
-- 주문번호 별 최대 지연일
select o.order_id, max(o.order_name), max(orc.del_date - o.order_date) as max_diff_days
from orders o
inner join receipts orc on o.order_id = orc.order_id
where orc.del_date - o.order_date >= 3
group by o.order_id;2. 모델 갱신 사용하는 방법
- SQL 에 의지하지 않고 해결하는 방법
- 배송 지연될 가능성 있는 주문 레코드에 플래그 필드를 orders 테이블에 추가
- 검색 쿼리는 해당 필드만을 가지고 가능
- 문제 해결 수단은 코딩 말고도 다양
- 망치라는 도구 가진 사람은 모든 게 다 못으로 보임
31강 모델 갱신의 주의점
1. 높아지는 갱신비용
- 검색 부하 → 갱신 부하
- 배송 지연 플래그 필드에 값 추가 행정 필요
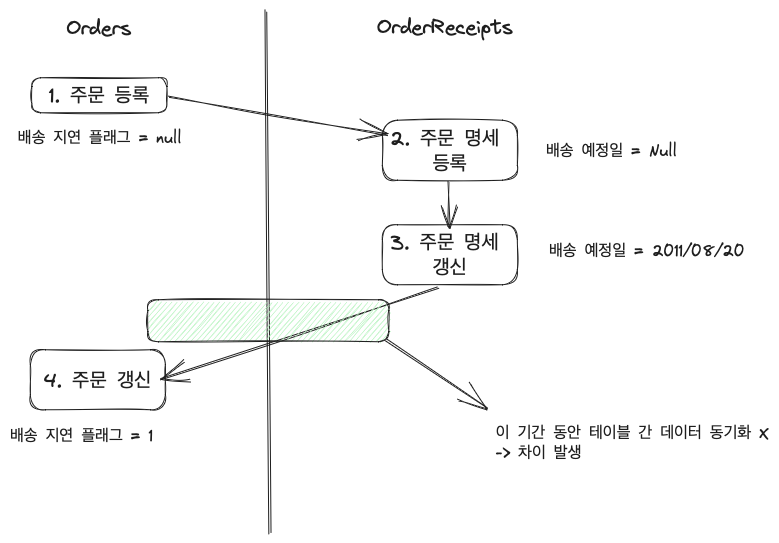
2. 갱신까지의 시간 랙 (Time Rag) 발생
- 데이터 실시간성 문제 발생
- orders 테이블의 배송 지연 플래그 필드와 receipts 테이블의 배송 예정일 필드가 실시간으로 동기화 되고 있지 않아 차이 발생
- 배치 갱신을 한다면 실시간성 문제는 더 붉어짐
- 성능과 실시간성 사이의 트레이드오프
3. 모델 갱신비용 발생
- RDB 데이터 모델 갱신은 대대적 수정 필요
- 모델링을 사전에 빡세게 생각해두지 않으면 나중에 큰 후회하는 핫 스팟
32강. 시야 협착 : 관련 문제
- SQL 구문 말고, 모델 갱신을 사용하면 쉽게 해결되는 문제는 생각보다 많음
- SQL 중급자가 자주하는 실수ㄱ
33강. 데이터 모델을 지배하는 자가 시스템을 지배한다.
- 현명한 데이터 구조 + 멍청한 코드 > 멍청한 데이터 구조 + 현명한 코드
- 테이블 만으로 모든 것을 명백하게 이해할 수 있기 때문에 모델링이 중요
정리
다중 필드 할당,서브 쿼리,case 식,merge 구문등 다양한 방식으로 SQL 갱신 구문 효율적으로 쓰자- SQL 코딩 말고
모델 갱신도 염두해두자. - 모델은 나중에 변경하려면 아주 힘드니, 처음에 잘 생각해두자.

개발하고 말테야