🎯 사건의 발단
멀티모듈을 적용해봤다.
적용한 이유는 부끄다만 솔직히 말하면 그냥 써보고 싶어서 적용해봤다.
'해보면서 체감을 해보자' 라는 생각이었다.
하지만 멀티모듈을 적용하면서 이런저런 애로사항을 겪어보고 내린 결론은 관심사 분리다.
특히 이번 플젝에서 포인트 관련 로직을 별도 모듈로 분리시키면서 그 장점을 확인할 수 있었다.
서순
- 레이어드 아키텍쳐의 형태를 한 멀티모듈
- 의존 역전을 통한 클린 아키텍쳐 형태의 멀티모듈
- 모듈의 의존성 관리
- 관심사를 분리하기 위한 멀티모듈
멀티모듈을 적용하면서 위와 같은 순서로 적용해봤다.
이번 포스팅에서는 위 서순에 맞춰 경험담을 풀면서 결론적으로 멀티모듈의 장점과 적용법을 톺아보고자 한다.
🔍 톺아보기
1. 레이어드 아키텍쳐의 형태를 한 멀티모듈
레이어드 아키텍쳐란
일단 먼저 레이어드 아키텍쳐가 뭔지부터 간단히 알아보자.
Layered Architecture
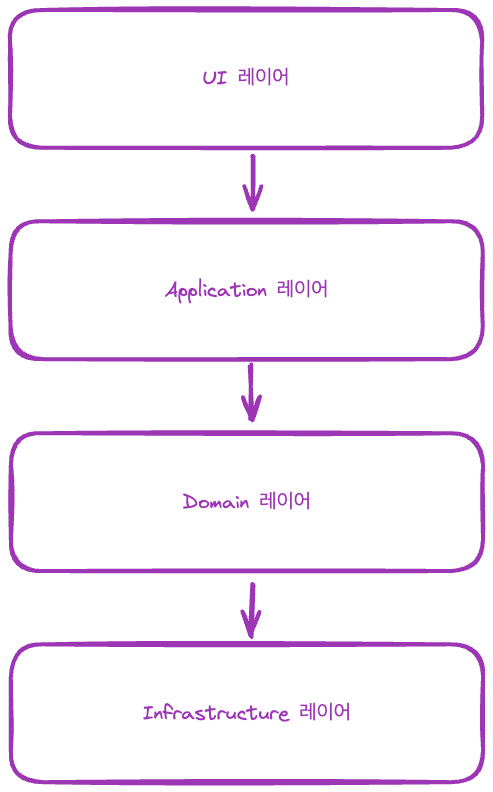
레이어드 아키텍처는 시스템을 계층(레이어)으로 나누어 설계하는 구조다.
일반적으로 (UI, Application, Domain, Infrastructure) 4개의 주요 레이어로 구성된다.
각 레이어 별로 성격과 역할이 명확히 구분되므로 상위 레이어가 하위 레이어를 의존하는 방식으로 구현한다.
일반적으로 가벼운 CRUD 서비스를 만든다면 가장 쉽게 적용할 수 있는 아키텍쳐다.
의존 방향이 일관되므로 이해하기도 쉽고, 구현하기도 쉽다.
다만, 후술할 클린 아키텍쳐에 비해 갖는 상대적인 단점이 있다.
바로 서비스 기능에 밀접한 관련이 있는 도메인에 집중하기가 어렵다는 점이다.
왜 멀티모듈로 하려고 했니?
멀티모듈을 맨 처음 적용하고자 할때 봤던 포스팅이었나 유튜브에서 이런 이야기를 했다.
멀티모듈은 의존성을 명확하게 하고자 함이다. - 신원미상의 개발자 -
gradle 이 뭔지도 잘 모르고, 의존성이 뭔지도 잘 모르는 나는 이 이야기를 라이브러리 의존성에 대한 이야기로 봤다.
그래서 인프라 레이어에서는 JPA, Database, JDBC 같이 영속성과 관련된 라이브러리만 의존하고,
어플리케이션 레이어에서는 web 라이브러리에 대해서만 의존성을 갖도록 하면 좋겠다는 생각을 했다.
그래서 레이어드 아키텍쳐를 멀티모듈을 통해서 적용하고자 했다.
결론부터 말하자면 이러한 방식으로는 목적 달성이 어려웠다.
이유는 아래와 같다.
- 프로그램 전반에 걸쳐서 사용되는 enum 같은 공용 클래스를 어떻게 활용할 것인지
- 트랜잭션 범위에 대한 설정을 어떻게 할 것인지
- 점차 비대해져 가는 프로그램을 나누고자 할 때 어떻게 해야할 것인지
1번 이유
공용 클래스를 관리하는 것이 어려웠다.
내가 개발 중인 독립출판 서비스에서는 해당 도서의 카테고리에 대한 enum 클래스인 Category 클래스가 있다.
문제는 이 클래스가 DB 저장을 위해 인프라 레이에서도 활용되고, api에서 활용되어 어플리케이션 레이어에서도 활용된다는 점이 있었다.
하지만 레이어드 아키텍쳐는 상위 레이어가 인접한 하위 레이어만 의존해야한다.
따라서 enum 클래스가 어느 한 레이어에서만 존재한다면 다른 레이어에서는 활용할 수 없다는 문제가 있었다.
2번 이유
기능은 대부분 도메인 레이어에 있다.
이런저런 기능 중 하나라도 잘못된다면 없던일로 돌려야 한다는 트랜잭션의 원자성을 위해서라도 나는 도메인 로직에 트랜잭션이 필요했다.
하지만 JPA 의 @Transactional 을 활용할 수 없다.
도메인 모듈에서는 JPA 관련된 라이브러리 의존성이 없기 때문.
3번 이유
이게 가장 큰 이유였다.
기능이 늘어갈수록 도메인 로직은 점차 비대해져 간다.
내가 작성한 코드임에도 점차 알아볼 수 없는 지경에 닿았다.
레이어드 아키텍쳐를 기반으로 한 멀티모듈은 레이어 수 이외에 확장성이 없다.
사실상 멀티모듈을 적용한 근간 자체가 흔들리는 일인 것이다.
위와 같은 이유로 레이어드 아키텍쳐 형태를 띈 멀티모듈은 그리 만족스럽지는 않았다.
2. 의존 역전을 통한 클린 아키텍쳐 형태의 멀티모듈
위에서 도메인 관련하여 애로사항이 있었다.
이를 해결하기 위해서는 도메인 레이어가 인프라 레이어를 의존하는 방향에서 벗어날 필요가 있었다.
그래야 도메인의 볼륨이 작아지고, 최대한 의존이 없이 가벼운 상태여야 도메인이 비대해졌을때 나누기가 용이하기 때문.
클린 아키텍쳐란
그럼 클린 아키텍쳐가 뭐냐?
이거다.
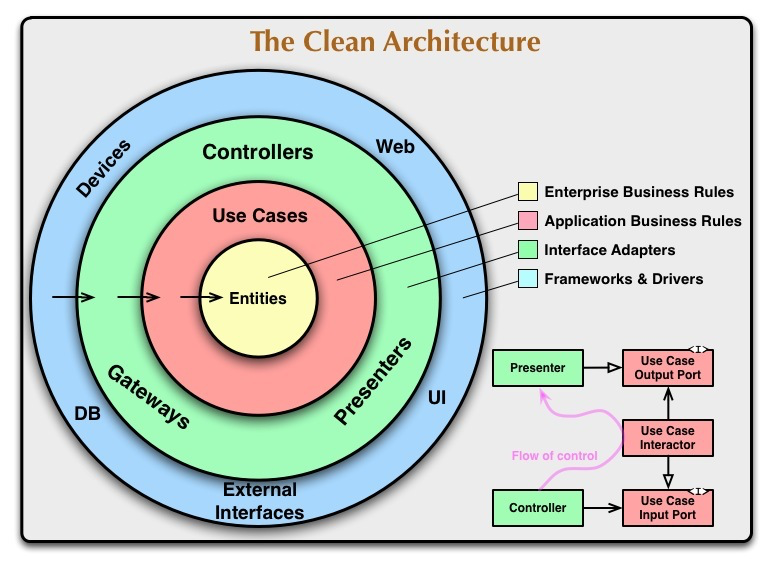
그림만 보고는 이해가 쉽지 않을텐데, 설명을 들어도 마찬가지다.
쉽게 설명하면 한 마디로 설명이 가능하다.
도메인이 어디에도 의존하지 않는 구조.
Enterprise 비즈니스 규칙은 우리가 흔히 사용하는 엔티티를 말한다.
서비스에서 다루고자 하는 가장 기본적인 클래스를 말한다.
기획 단계 이후로 수정이 거의 발생하지 않는 아주 핵심인 부분을 말한다.
도서 엔티티에서 도서 아이디, 책 제목, 책 정보와 같이 다루고자 하는 핵심인 것이다.
Application 비즈니스 규칙이 도메인을 뜯한다.
Use Cases 라고 나온것처럼 실제로 엔티티를 서비스에서 활용하는 여러 케이스를 다루는 것을 말한다.
기능을 구현하는 부분이라고 보면 된다.
따라서 기획 단계 이후에도 종종 수정이 발생할 수 있다.
내가 집중하고자 하는 부분이 여기에 해당한다.
나머지 인터페이스 어뎁터나 프레임워크, 드라이버와 같은 부분 위에서 설명한 어플리케이션 레이어, 인프라 레이어와 맥을 같이 한다.
HTTP 를 활용해서 클라이언트와 소통하고자 하는 경우에 컨트롤러 클래스를 만들어 content-type 을 설정하거나 url을 파싱하거나 하는 부분을 말한다.
또한, JDBC를 활용해서 디비에 저장하는 것도 여기에 해당한다.
스프링 프레임워크에 종속되는 부분도 여기에 해당한다.
따라서 도메인(어플리케이션 비즈니스 규칙)에서는 스프링도 모르고, 디비도 모르고, 프로토콜도 모르는 상태가 된다.
도메인이 아--주 가볍고, 아--주 확장하기 쉬운 구조가 된다는 것.
그래서 멀티모듈로 어떻게 함?
그림으로 설명하겠다.
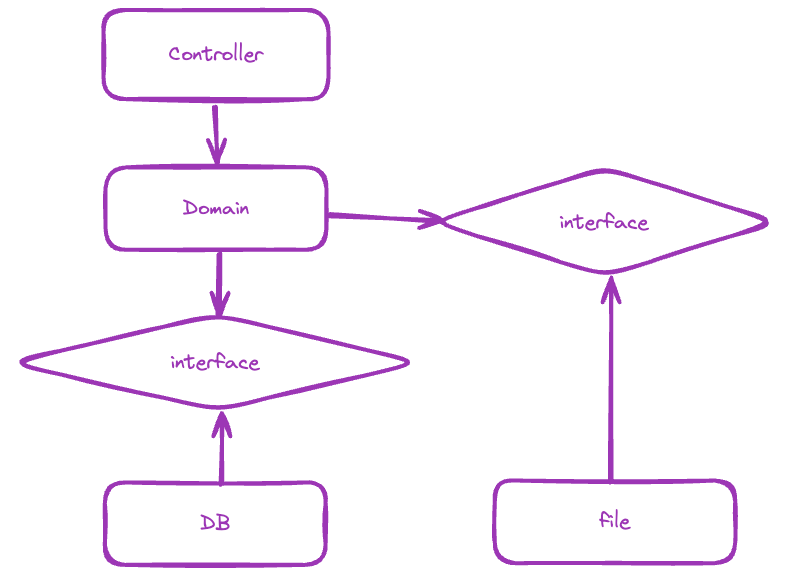
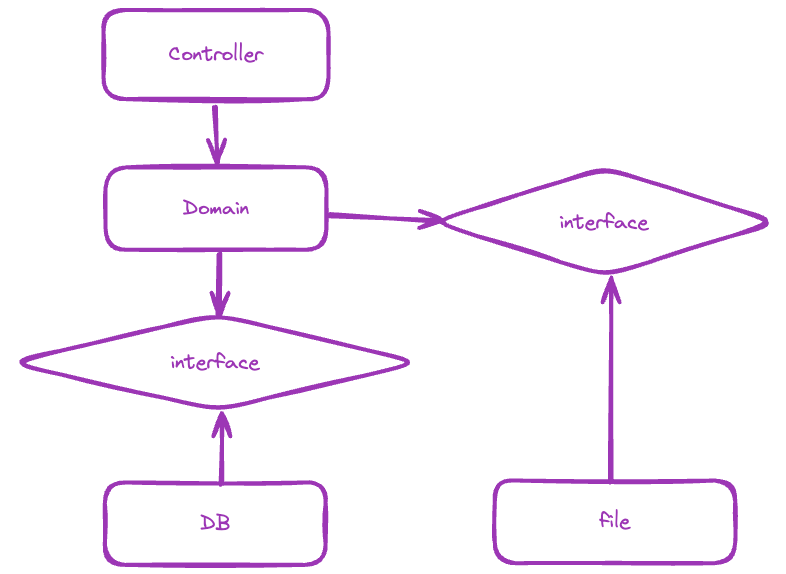
이런 방식으로 아키텍쳐를 구축했다.
위의 근본 그림과는 조금 다르지만 핵심은 같다.
프레임워크, 프로토콜과 관련된 의존은 Controller 에.
DB는 Repository 에.
File또한 별도 Repository 에 둔다.
그리고 도메인과의 중간 다리에 인터페이스를 둔다.
Repository에서는 그 인터페이스를 구현한다.
이렇게하면 의존의 역전이 발생하고, 도메인이 인프라 레이어를 의존해야 하는 기존 레이어드 아키텍쳐의 의존 방향이 깨지게 된다.
결과적으로 도메인은 다른 어떠한 것도 의존하지 않게 된다.
인터페이스를 의존하는게 아니다. interface 는 그저 어뎁터의 역할만 하는 것이지 로직을 포함하는 것이 아니므로 상관없다.
사실 상관없다고 생각하는 거다. 확실한건 아님.
api 모듈에 컨트롤러를, domain 모듈에 도메인을, storage 모듈에 레포지토리를 둔다면
이전 구조보다 훨씬 확장성 있는 구조가 가능할 것이라고 생각했고,
이를 강제하기 위한 수단으로 멀티모듈을 채용했다.
결과적으로 클린 아키텍쳐에 가까운 구조를 만들어낼 수 있었고, 다른 문제를 고려하지 않고 기능에만 집중해서 구현할 수 있게 되었다.
기능 추가마다 도메인에서 고민할 거리가 확실하게 구분되었기 때문에 상당히 만족스러웠다.
다만, @Transactional 이나, Pageable 과 같이 스프링 프레임워크가 제공하는 편리한 기능을 포기하지 못해서 완전한 클린 아키텍쳐 달성은 하지 못했다.
그래도 이정도 트레이드 오프는 괜찮지 않을까 싶어 넘어가기로 했다.
바퀴를 다시 발명하지 말라는 말도 있으니깐.
3. 모듈의 의존성 관리
잘 나눠놨으나, 문제는 의존성 관리였다.
라이브러리 의존성이야 뭐 필요한 것을 잘 나눠서 넣어주면 될 일이었다.
하지만, 모듈 간의 의존성을 무지성으로 implementation 으로 설정한 것은 뭔가 문제가 있어보였다.
또한, 모듈 간의 계층구조가 있는 경우에 같은 build.gradle 코드가 중복되는 경우도 심심찮게 발생했다.
build.gradle 파일은 어떻게 해야하나
찾아보니, subproject 나 allproject 와 같은 gradle 문법이 있었다.
이를 통해서 계층적으로 의존성을 관리하니 수정할 부분이 줄어들고, 어떻게 서로에게 영향을 주는지 파악할 수 있었다.
예를 들어서,
나는 storage 모듈 하위에 db-storage, file-storage 모듈을 두었다.
이름처럼 db-storage 는 DB 관련 의존만 있으면 되고, file 은 AWS 관련 설정만 있으면 된다. (나는 파일 관리에 AWS S3 를 쓴다.)
하지만 두 모듈 모두, 공용 enum 클래스를 활용하므로 공통으로 의존하는 부분이 발생한다.
이럴때 이렇게 build.gradle 을 작성할 수 있다.
// storage 모듈
plugins {
id 'java-test-fixtures'
}
subprojects {
apply plugin: 'java-test-fixtures'
dependencies {
// Module
compileOnly(project(':library-domain'))
implementation(project(':library-object'))
// Test
testImplementation(project(':library-domain'))
}
}// db-storage 모듈
dependencies {
// Test
testImplementation(testFixtures(project(':library-domain')))
testImplementation "org.testcontainers:mysql:1.19.8"
// Flyway
implementation 'org.flywaydb:flyway-mysql:10.15.2'
// JPA
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
// MySQL
runtimeOnly 'com.mysql:mysql-connector-j'
// Hypersistence Utils
implementation 'io.hypersistence:hypersistence-utils-hibernate-63:3.8.1'
// Jackson
implementation 'com.fasterxml.jackson.core:jackson-databind'
// QueryDSL
implementation 'com.querydsl:querydsl-jpa:5.1.0:jakarta'
annotationProcessor 'com.querydsl:querydsl-apt:5.1.0:jakarta'
annotationProcessor "jakarta.annotation:jakarta.annotation-api"
annotationProcessor "jakarta.persistence:jakarta.persistence-api"
}// file-storage 모듈
dependencies {
// Test
testImplementation(testFixtures(project(':library-object')))
// AWS S3
implementation(platform('software.amazon.awssdk:bom:2.26.12'))
implementation('commons-io:commons-io:2.16.1')
implementation('software.amazon.awssdk:aws-core:2.25.30')
implementation('software.amazon.awssdk:sdk-core:2.26.14')
implementation('software.amazon.awssdk:sts:2.26.12')
implementation('software.amazon.awssdk:s3:2.25.27')
testImplementation('org.testcontainers:localstack')
}이렇게 관리가 가능했다.
의존 레벨 설정은 어떻게 해야하나
의존 레벨은 여러가지가 있다.
여기서는 groovy 문법 build.gradle 기준으로 설명한다. 코들린 아니다.
- api
- 라이브러리를 사용하는 다른 모듈에서도 이 의존성을 사용할 수 있게 합니다. 즉, 이 의존성이 공개되어 모듈 간에 공유됩니다. - implementation
- 현재 모듈 내에서만 사용되며, 외부로 공개되지 않습니다. 내부 구현에 필요한 의존성을 정의할 때 사용합니다. - compileOnly
- 컴파일 시에만 필요한 의존성을 정의합니다. 런타임에는 필요하지 않습니다. - runtimeOnly
- 런타임 시에만 필요한 의존성을 정의합니다. 컴파일 시에는 필요하지 않습니다.
이렇게 의존성 레벨을 필요에 맞게 설정할 수 있다.
컴파일 시에만 필요한 모듈을 구태여 Implementation 으로 의존성을 설정하여 괜시리 무겁게 다닐 필요가 없다는 말이다.
위에서 내가 구축한 아키텍쳐를 보면 db, file 과 같은 Repository 는 인터페이스를 구현하기만 한다.
따라서 domain 모듈에 있는 interface 만 알면된다.
런타임에는 굳이 알 필요가 없다는 말이다.
그래서 위의 build.gradle 파일을 보면
compileOnly(project(':library-domain')) 이렇게 설정한 것을 볼 수 있다.
하지만, 컴파일과 런타임 모두에서 필요한 공용 클래스가 있는 library-object 모듈은 implementation 으로 설정했다.
Controller 클래스가 정의되어있는 api 모듈은 domain 모듈을 implementation 으로 설정했다.
왜냐면 모든 요청이 controller 를 통해 도메인에 전달되게 되므로, api 모듈 입장에서는 domain 모듈이 컴파일과 런타임 모두에서 필요하기 때문이다.
4. 관심사를 분리하기 위한 멀티모듈
멀티모듈의 목적은 무엇인가
고백하자면, 위와 같이 아키텍쳐를 구축하기 위한 멀티모듈은 그닥 권장되는 방식이 아니라고 한다.
실력쟁이 개발자 유튜버가 그렇게 이야기했다.
이유는 다음과 같다.
- 멀티모듈의 목적은 중복되는 코드를 줄여 수정이 용이한 상태로 만드는것
- 관심사를 분리하여 개발 생산성을 확보하는 것
- 의존성을 명확하게 설정하여, 캡슐화를 수행하는 것
위의 방식으로도 다음 이유를 어느정도 만족시킬 수 있는 것은 사실이지만, 근본 목적이 아키텍쳐 적용에 있으면 안 된다는 것이다.
쉽게 말해서
"아. 클린 아키텍쳐 마려우니까 멀티모듈 해야지~" : ❌
"아. 특정 로직만 따로 관리하고 싶으니까 멀티모듈 해야지~" : 👍
이거란 말씀.
그래서 어케함?
내 프로젝트에서 포인트 관련된 로직이 있다.
포인트 관련 기능은 다음과 같다.
- 포인트 지급 / 차감
- 포인트 일일 지급한도 확인/갱신
포인트 관련 기능이 필요한 시점은 다음과 같다.
- 도서 등록 시
- 서평 등록 시
- 서평 삭제 시
- 서평픽 등록 시
- 서평픽 취소 시
- 출석 이벤트 참여 시
하지만 포인트 관련된 기능이 기존 도메인에 포함되어 있다면, 도메인에서는 포인트 관련된 시점과 그 기능에 대해서 빠삭하게 이해하고 있어야 하는 상태로 개발을 해야한다.
문제는 이렇게 하니까 기존 코드에서 수정할 부분이 너무 많아지고, 코드 작성자인 나조차도 코드 이해가 쉽지 않다는 문제가 발생했다.
이 문제를 해결하기 위해서 포인트 관련한 로직을 분리하여 멀티모듈을 적용했다.
코드 보고 오실게요
- 기존 코드
@Transactional
public ReviewPick register(long loginId, long reviewId) {
Member member = memberRepository.read(loginId);
Review review = reviewRepository.read(reviewId);
if (dailyPointLimitRepository.isCreditable(loginId)) {
dailyPointLimitRepository.save(loginId, dailyPointLimitRepository.find(loginId) + 1);
pointRepository.creditPoints(member.memberId(), REVIEW_PICK_GIVER_POINT);
pointRepository.creditPoints(review.member().memberId(), REVIEW_PICK_RECEIVER_POINT);
}
return reviewPickRepository.create(new ReviewPick(null, member, review));
}- 변경 후 코드
// 서평픽 서비스
@Transactional
public ReviewPick register(long loginId, long reviewId) {
Member picker = memberRepository.read(loginId);
Review review = reviewRepository.read(reviewId);
pointService.creditPointForReviewPick(picker.memberId(), review.member().memberId());
return reviewPickRepository.create(new ReviewPick(null, picker, review));
}
// 포인트 서비스
@Override
@Transactional
public void creditPointForReviewPick(long pickerMemberId, long receiverMemberId) {
if (dailyPointLimitRepository.isCreditable(pickerMemberId)) {
dailyPointLimitRepository.save(
pickerMemberId, dailyPointLimitRepository.find(pickerMemberId) + 1);
pointRepository.creditPoints(pickerMemberId, REVIEW_PICK_PICKER_POINT);
pointRepository.creditPoints(receiverMemberId, REVIEW_PICK_RECEIVER_POINT);
}
}기존 서평픽 관련 서비스에서는 포인트와 관련한 세부사항을 알지 못하게 되었다.
그저 서평픽을 등록한 경우에는 암튼 모르겠고, 포인트를 지급하라고 요청하기만 하면 된다.
포인트 서비스는 요청을 받고, 해당 유저가 포인트를 받을만한지 확인해서 포인트를 지급한다.
포인트 관련한 세부사항을 여기서 해결하게 된 것이다.
만약에 서평픽 등록 시 포인트 지급에 문제가 발생했다면,
기존 코드에서는 서평픽 등록 메소드에서 포인트 관련한 코드를 보고 이해하고 수정해야했지만,
수정된 코드에서는 아묻따 포인트 서비스에서 뭐가 잘못됐는지 확인하면 된다는 것.
이렇게 관심사에 따라서 책임을 확실히 분리하고 변경이 용이한 코드로 만들어두니, 개발하기 편해졌다.
🔑 결론
멀티모듈을 바라보는 관점이 바뀌어감에 따라, 시도하는 방향과 결과가 많이 달라졌다.
결과적으로 기능 추가에 열려있는 확장성 있는 구조를 만들어낼 수 있는 초석을 닦았다는 점이 아주 기분조타.
심지어 글로만 보고 장점만 취득한 것이 아니라, 실제로 이것저것 삽질해보면서 체감한 장점이라 더욱 기분 조오타
멀티모듈 때문에 잠못들던 지난 몇주가 참 아깝고, 고마운 시간이었다.
