🎯 목적
- 학원 공공데이터에서
원하는 데이터만 추출하여 서버에 저장- 경기, 서울 학원 현황 공공데이터 (CSV 파일) 파싱
- 이점
- 스터데이
원 서버 과부하 방지 - 서버 별
역할 분리
- 스터데이
- 법정동 데이터 추출해 서버 저장
- 법정동 위경도와 함께
regions테이블에 저장
- 법정동 위경도와 함께
🔗 Github 링크
📚 기술스택
- Java 17
- Spring Boot 3.1.5
- Docker
- MySQL 8
- Library
- Spring Data JPA
- Lombok
- WebFlux
- Gson
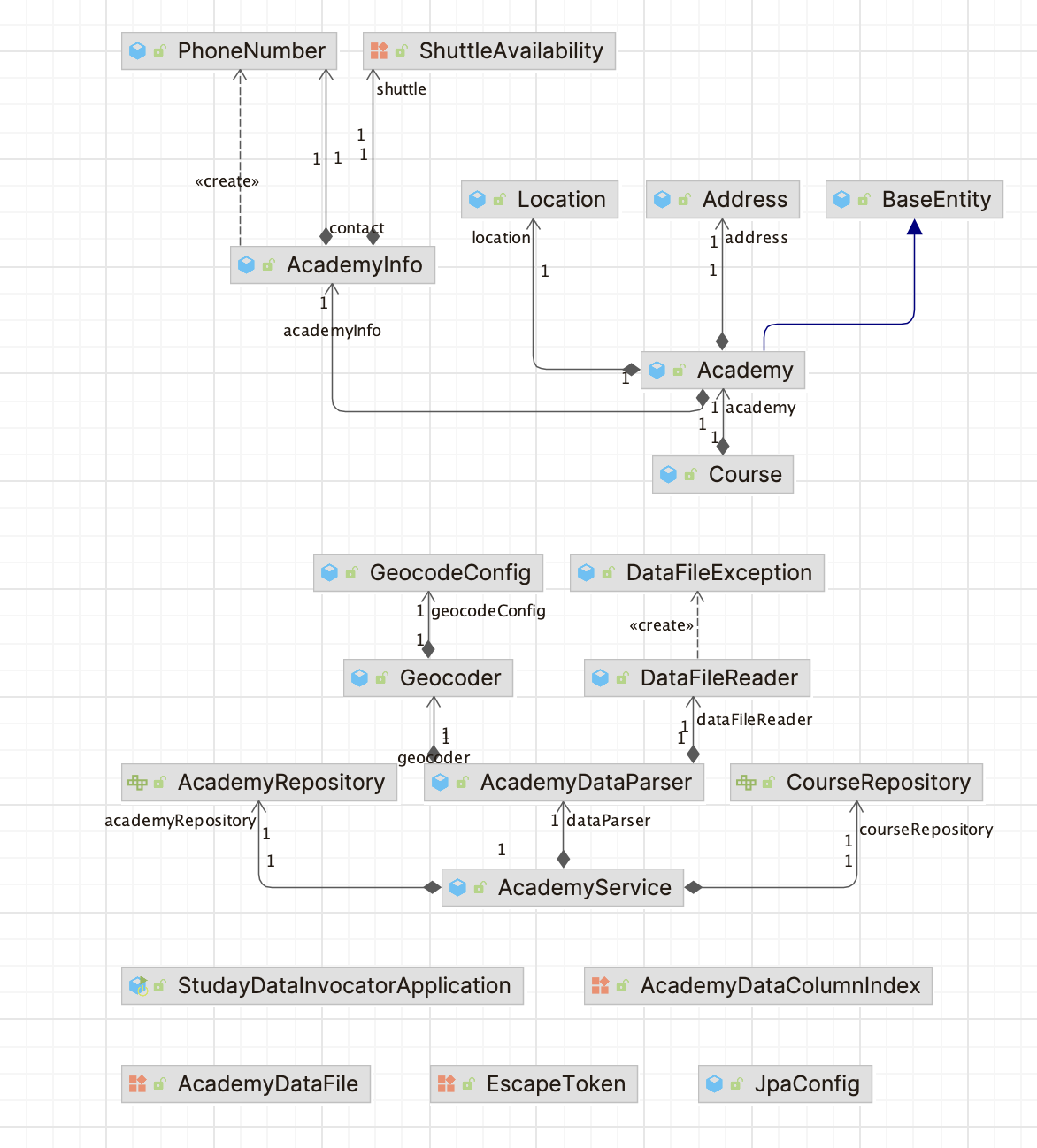
🏛️ 구조
학원 데이터 파싱
DataFileReader- 데이터 파일 (CSV) 파일 읽기
AcademyDataParser- 원하는 데이터 컬럼 추출
- 주소 정보로 위경도 정보 변환
- 데이터를 학원 정보 + 수업 정보로 분리
Geocoder- 네이버 지오코드 활용 (외부 API 호출)
V1: RestTemplate 방식 구현(제거)- V2: WebClient 방식 구현
- WebFlux 라이브러리 활용
- Json 응답을 Map 으로 변환
- Gson 라이브러리 활용
- 공공데이터 주소값 → 위경도 변환
- 네이버 지오코드 활용 (외부 API 호출)
법정동 데이터 파싱
RegionDataParser- 공공데이터
Open API활용- WebClient 사용 시 URL 자동 인코딩 되는 현상 방지하고자,
URLStringBuilder,DefaultBuilderFactory클래스 활용
- WebClient 사용 시 URL 자동 인코딩 되는 현상 방지하고자,
- 행정동 데이터를 법정동 데이터로 변환
- 행정동 숫자 데이터를 제거
- 구 단위 주소가 누락된 건에 대해서 같은 주소로 판단하도록
equals and hashCode구현- 경기도 용인시 수지구 성복동 = 경기도 용인시 성복동
- 외부 API 호출 횟수 감소 위해 중복된 주소를 Set 자료형으로 중복 제거하여 위경도 변환 요청
- 공공데이터
Geocoder- 네이버 지오코드 활용 (외부 API 호출)
- 법정동 주소 → 위경도 변환
- Json 응답에 맞는 DTO를 만들어 매핑되도록 구현
- 네이버 지오코드 활용 (외부 API 호출)
🦽 사용법
- 아래 공공데이터 링크에서 엑셀 파일을 다운로드 받는다.
- 해당 엑셀 파일을
CSV 파일로 내보내기 한다.- CSV 파일 내 모든 쉼표(,)를 슬래시(/) 로 변환 (cmd + R)
- 프로젝트 루트에 있는
docs/data폴더에 CSV 파일을 이동시킨다. StudayDataInvocatorApplicationTests테스트를 실행한다.- DB 내용을 확인한다.
🫵 주요 기능
주소 정규화
- 학원 데이터
경기도 성남시 중랑구 서구로6번길 4 / 3층 일부 (하서원동)- 위 주소를 검색 필터에 필요한 컬럼 3개와 원본 주소로 분리
- full_address :
경기도 성남시 중랑구 서구로6번길 4 / 3층 일부 (하서원동) - sido :
경기도 - sigungu :
성남시 - upmyeondong :
중랑구
- full_address :
- 법정동 데이터
경기도 용인시 수지구 성복동- 시도 / 시군구 / 읍면동 3개 컬럼으로 구분 (네이버 지도 데이터 참조)
- sido :
경기도 - sigungu :
용인시 수지구 - upmyeondong :
성복동
- sido :
- 행정동 데이터를 법정동 데이터로 변환
- 주소 변경이 빈번하지 않은 법정동 데이터 활용
신당1/2/3동과 같은 행정동 데이터를신당동과 같은 법정동 데이터로 변환
- 중복 주소 데이터 제거
용인시 성복동 → 용인시 수지구 성복동처럼 구체적인 주소로 DB에 저장- 주소 VO 생성하여 주소값을 포함하는 경우 같은 주소 객체로 판단하도록
equals and hashCode구현 - open api 응답으로 들어온 주소 데이터를 Set 자료형을 활용해 중복 제거
- 구제적인 주소를 선택하기 위해 Set 자료형을 필드로 갖는
일급 컬렉션으로 관리
- 구제적인 주소를 선택하기 위해 Set 자료형을 필드로 갖는
주소 위경도 변환
경기도 성남시 중랑구 서구로6번길 4 / 3층 일부 (하서원동)- 위 주로를 네이버 Geocode 서비스 활용해 위경도로 변환
- 중복된 주소인 경우 호출 횟수 감소로 비용 절감 위해 캐싱 적용
- 호출 직전 Java Map 자료구조 활용해
in-memory 캐싱적용
- 호출 직전 Java Map 자료구조 활용해
- 주소 데이터가 다른 주소 데이터의 부분집합일 때 (다른 주소의 모든 정보에 포함되는 정보일 때) 같은 주소로 판단
데이터 파일 파싱
- CSV 파일을 대상으로 문자열 파싱
- 공공데이터 제공 파일 형식이 엑셀 파일이기 때문에 CSV 파일로 처리 대상 정함
- 공공데이터 컬럼 확장성 고려
- 공공데이터에서 제공하는 모든 컬럼을 enum 항목으로 만들어 필요 데이터 사양 변경 시 유연한 변경 지향
Open API 활용
- 공공데이터 Open API 활용
- WebClient 사용시 URL이 자동으로 인코딩되는 현상
- 오픈 API 사용시 Bad Request 응답 발생하는 문제 해결
- URLStringBuilder, DefaultBuilderFactory 클래스 활용해 자동 인코딩 방어
- WebClient 사용시 URL이 자동으로 인코딩되는 현상
- 응답 데이터에 맞는 DTO 구현하여 응답 Json 이 ObjectMapper 를 통해 자동으로 프로젝트에서 활용 가능한 데이터로 변환
파싱 데이터 DB 저장
- Spring Boot JPA 활용
- JDBC 직접 활용, MyBatis 보다 개발 비용이 좋다고 판단해 사용
- Academy 엔티티 + Course 엔티티 분리
- 수업에 대해 중복된 학원 데이터 중복 제거를 통한 테이블 크기 감소 목적
- 중복 데이터 제거로 데이터 정규화
- 상대적으로 작아진 테이블로 인한 쿼리 최적화
🤖 시도점
- 캐싱
데이터 특성 고려- 같은 주소가 모여있는 클러스터링 특성 고려
- 한 번 구한 주소는 다음 데이터에서도 활용될 가능성이 높음
- 추후 배치 처리할 때 배치 묶음에서 캐싱 효용 기대 가능
서비스 특성 고려- 모든 데이터를 네이버 API 를 활용해 요청하기엔 비용 문제 심각
- API 호출을 최대한 억제해야 할 필요성
인 메모리 방식 고려- DB 캐싱 방식은 추후 배치 처리에서 캐싱 효용이 낮아질 것
- 인 메모리 방식으로 배치 처리 내에서 캐싱 효용을 확보하는 것이 더 큰 이점 있을 것
- 법정동 데이터 정규화
- 행정동 데이터를 법정동 데이터로 변환
- 누락된 주소 데이터를 구체적인 주소 데이터로 변환하여 DB 저장
- 자료구조와 일급컬렉션을 활용하여 문제 해결
- 외부 API 호출
- RestTemplate 방식
- 이전에 Java 진영에서 자주 활용되던 방식
- 쉬운 사용법으로 간단하게 주소 → 위경도 변환 결과 확인하는 용도로 구현
- 동기/비동기 방식을 선택할 수 없이 동기 방식이기에 WebClient 방식 추가 구현
- WebClient
- WebFlux 라이브러리 활용해 구현 가능
- 이점
- 동기/비동기 선택 가능
- 높은 처리량, 확장성
- 리액티브 프로그래밍 가능
- 응답과 매핑되는 DTO 구현으로 응답을 쉽게 프로그램에서 활용 가능한 형태로 변환 가능
- 단점
- 자동 URL 인코딩 방지를 위한 추가 코드 필요
- webflux 학습 필요
- 데이터 파싱 작업 내에서 외부 API 호출이 필요했으므로,
동기 방식(block)으로 구현
- RestTemplate 방식
- 데이터 구분자
- 제공 데이터 형식이 엑셀 고정이라 문자열 처리를 편하게 하기 위해 CSV 파일로 데이터 파일 형식 고정
- 데이터 내부에 CSV 기본 구분자 (쉼표: ,) 가 존재했기 때문에 파싱 어려움 존재
- 이를 극복하고자 쉼표가 아닌 다른 구분자 (/) 로 설정하는 방식 도입
- OpenAPI 활용하는 방식이었으면 스케줄러와 배치 처리를 통해서 완전 자동화가 가능했을텐데, 해당 데이터 활용을 위해서는 데이터 업데이트 마다 수동으로 데이터 처리를 해줘야 한다는 것이 단점임
- 제공 데이터 형식이 엑셀 고정이라 문자열 처리를 편하게 하기 위해 CSV 파일로 데이터 파일 형식 고정
🔗 공공데이터

개발하고 말테야