Apache Kafka는 무엇인가?
Data in Motion Platform for Enterprise
움직이는 데이터를 처리하는 플랫폼
Event Streams를 받아서 이를 필요로 하는 Event Streams로 전송
Event는 비즈니스에서 일어나는 모든 일(데이터)을 의미
- 웹사이트에서 무언가를 클릭하는 것
- 청구서발행
- 송금
- 배송물건의 위치정보
- 택시의GPS 좌표
- 센서의온도/압력데이터
Event는 BigData의 특징을 가짐
- 비즈니스의 모든영역에서 광범위하게 발생
- 대용량의데이터(Big Data) 발생
Event Stream은 연속적인 많은 이벤트들의 흐름을 의미
Apache Kafka의 특징
- 이벤트 스트림을 안전하게 전송
- 이벤트 스트림을 디스크에 저장✨
- 이벤트 스트림을 분석 및 처리
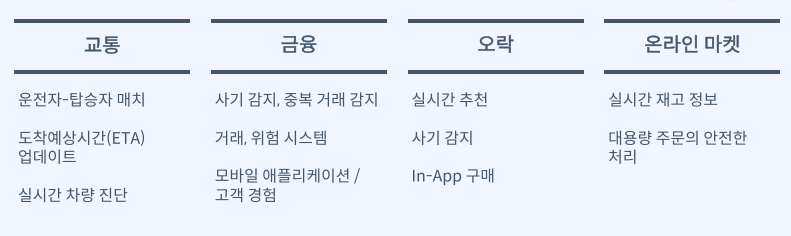
Event(메시지/데이터)가 사용되는 모든 곳에서 사용
- Messaging System
- IOT디바이스로부터 데이터수집
- 애플리케이션에서 발생하는 로그수집
- Realtime Event Stream Processing (Fraud Detection, 이상 감지 등)
- DB동기화 (MSA 기반의 분리된 DB간 동기화)
- 실시간 ETL (데이터를 추출해서 변환하고 다시 적재)
- Spark, Flink, Storm, Hadoop 과 같은 빅데이터기술과 같이 사용
Apache Kafka 주요 요소
Topic, Producer, Consumer
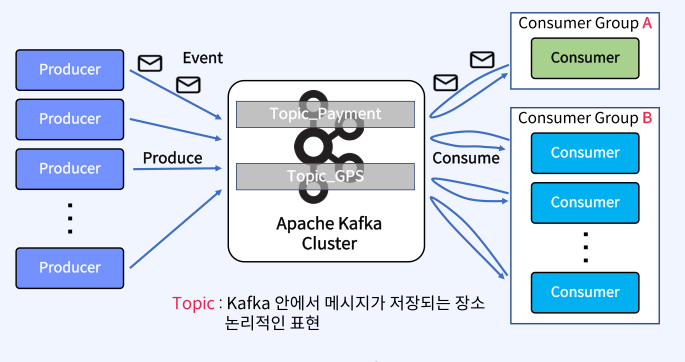
• Producer : 메시지를 생산(Produce)해서 Kafka의 Topic으로 메시지를 보내는 애플리케이션
• Consumer : Topic의 메시지를 가져와서 소비(Consume)하는 애플리케이션
• Consumer Group : Topic의 메시지를 사용하기위해 협력하는 Consumer들의 집합
• 하나의 Consumer는 하나의Consumer Group에 포함되며, Consumer Group내의 Consumer들은협력하여 Topic의 메시지를 분산병렬 처리함
Producer와 Consumer의 기본 동작 방식
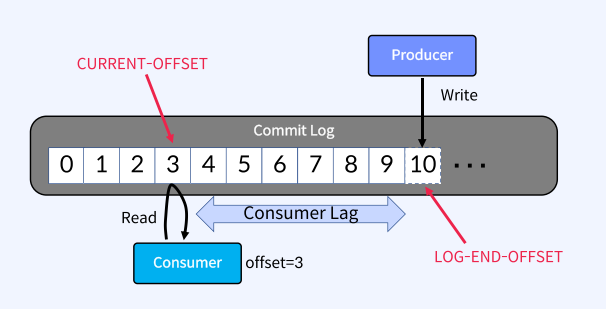
• Producer와 Consumer는 서로 알지 못하며, Producer와 Consumer는 각각 고유의 속도로 Commit Log에 Write 및 Read를 수행
• 다른Consumer Group에 속한C onsumer들은 서로 관련이 없으며, Commit Log에 있는 Event(Message)를 동시에 다른 위치에서 Read할 수 있음
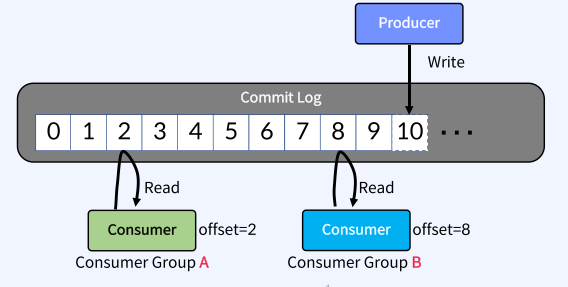
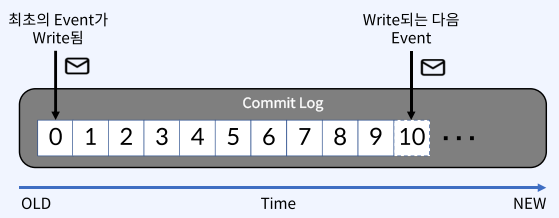
• Commit Log : 추가만 가능하고 변경 불가능한 데이터 스트럭처 데이터(Event)는 항상 로그 끝에 추가되고 변경되지 않음
• Offset : Commit Log 에서 Event의 위치 아래그림에서는 0부터 10까지의 Offset을 볼 수 있음
Producer가 Write하는 LOG-END-OFFSET과 Consumer Group의 Consumer가 Read하고 처리한 후에 Commit한 CURRENT-OFFSET과의 차이(Consumer Lag)가 발생할 수 있음
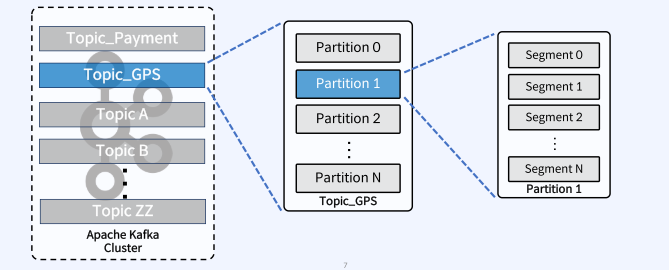
Topic, Partition, Segment Logical View
• Topic : Kafka안에서 메시지가 저장되는 장소, 논리적인표현
• Partition : (=Commit Log), 하나의 Topic은 하나 이상의 Partition으로 구성 병렬처리(Throughput 향상)를 위해서 다수의 Partition 사용
• Segment : 메시지(데이터)가 저장되는 실제물리 File Segment File이 지정된 크기보다 크거나 지정된 기간보다 오래되면 새 파일이 열리고 메시지는 새 파일에 추가됨
Topic, Partition, Segment Physical View
• Topic 생성시 Partition 개수를 지정하고, 각Partition은 Broker들에 분산되며 Segment File들로 구성됨
• Rolling Strategy : log.segment.bytes(default 1 GB)=> 용량, log.roll.hours(default 168 hours) => 시간 으로 만듦 ==> 너무 커지는걸 방지
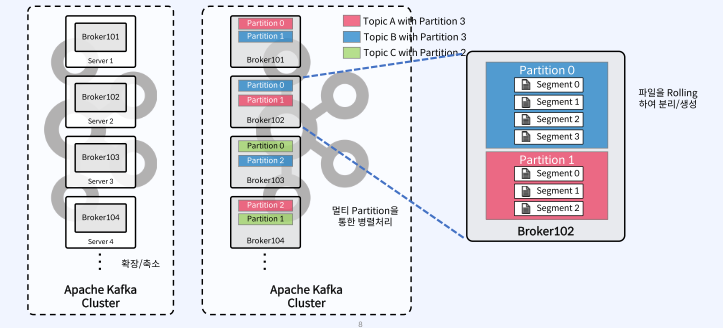
Apache Kafka Cluster는 여러개의 Broker들로 구성되어져 있음(이후 확장/축소 가능)
TopicA는 Partition3개를 가지고 만들겠다! => TopicA가 Broker들에 분산되어짐
TopicB는 Partition3개를 가지고 만들겠다! => TopicB가 Broker들에 분산되어짐
분산되는 방식은 Broker, Cluster내에서 최적의 장소에 위치시킴
Broker102를 보면, TopicB의 Partition0과 TopicA의 Partition1의 Segment File들이 Rolling되어져 있음Partition당 오직 하나의 Segment가 활성화(Active) 되어있음
=> 데이터가 계속 쓰여지고 있는 중
• Partition번호는 0부터 시작하고 오름차순
• Topic 내의 Partition들은 서로 독립적임
• Event(Message)의 위치를 나타내는 offset이 존재
• Offset은 하나의 Partition에서만 의미를 가짐 Partition 0의 offset 1 ≠ Partition 1의 offset 1
• Event(Message)의 순서는 하나의 Partition내에서만 보장
• Partition에 저장된 데이터(Message)는 변경이 불가능(Immutable)
• Partition에 Write되는 데이터는 맨끝에 추가되어 저장됨
