로그변환 그거 뭔데. 그거 어떻게 하는건데.

ML모델을 '잘' 만들기 위해서는 넘어야할 산이 많이 있습니다.
이번 포스팅에서는 그 산들 중 하나인 정규성과 변환, 그 중에서도 로그변환에 대해 다뤄보겠습니다 🏃♂️
로그변환에 논하기 전에, '변수를 정규분포로 변환해라' 는 말을 들어본 적이 있나요?
답은 Case by case입니다. 저 한문장 안에 여러가지 따져봐야할 것들이 있습니다.
함께 물음표살인마가 되어봅시다

Q. 변수를 정규분포 형태로 꼭 변환해야할까?
정규분포 변환이 필요한 경우
- 정규성 분포를 따른다는 가정을 기반으로 하는 경우입니다
1) 선형모델:선형회귀, 로지스틱 회귀 등
2) 가우시안 나이브 베이즈
- ANOVA 및 T-검정
정규분포 변환이 필요하지 않은 경우
1) 트리 기반 모델
2) KNN, SVM(서포트벡터머신)
3) 신경망. *입력변수의 스케일을 맞추는 것은 중요
선형모델에서 변수의 정규분포가 중요한 이유
(with GPT)
-
잔차의 정규성 가정
선형 회귀 모델은 잔차(오차)의 분포가 정규분포를 따른다고 가정합니다. 이는 여러 통계적 검정과 신뢰 구간 계산의 기초가 됩니다. 잔차가 정규분포를 따를 경우, 다음과 같은 이점이 있습니다: -
추정의 효율성: 회귀 계수의 추정치가 더 정확해집니다.
신뢰 구간 및 p-값 계산의 정확성: 잔차가 정규분포를 따를 때 신뢰 구간과 p-값 계산이 정확해집니다. -
선형성 가정
독립 변수와 종속 변수 간의 관계가 선형이어야 합니다. 변수가 정규분포를 따를 때, 선형성 가정이 더 잘 만족될 수 있습니다. -
이상치의 영향 최소화
정규분포를 따르지 않는 변수는 종종 이상치를 포함합니다. 이러한 이상치는 모델에 큰 영향을 미칠 수 있습니다. 변환을 통해 이상치의 영향을 줄일 수 있습니다. -
해석의 용이성
변수가 정규분포를 따를 때, 데이터의 해석이 더 쉬워집니다. 이는 모델의 가정을 더 잘 만족하기 때문입니다.
*하지만 정규성을 위한 변환이 모델 성능향상을 반드시 보장하는 것은 아닙니다.
변환을 적용하면서 데이터의 구조적 패턴을 잃을 수도 있어요
정규분포를 위해 변환하는 방법 종류
- 데이터 분포, 특징에 따라 로그변환, 제곱근변환, box-cox변환, 지수변환, 분위수 변환 등 다르게 적용해야 해요. 이 중 흔하게 사용하는 로그변환을 예시로 들어 설명해볼게요.
로그변환을 하는 이유
- 입력과 출력의 관계가 선형적이 되어 설명력이 높아지기 때문입니다.
로그변환의 대상
언제 로그변환을 해야할까?
왼쪽으로 치우친 그래프는 x가 작은경우 기울기가 가파르고 x가 큰 경우 기울기가 완만해지죠
이를 완화하려면 어떤 특징이 있는 함수를 만나야할까요? 이를 위해서는 y의 특징을 알아야해요.
y값은 결국 새로운 함수의 input이 될거니까요
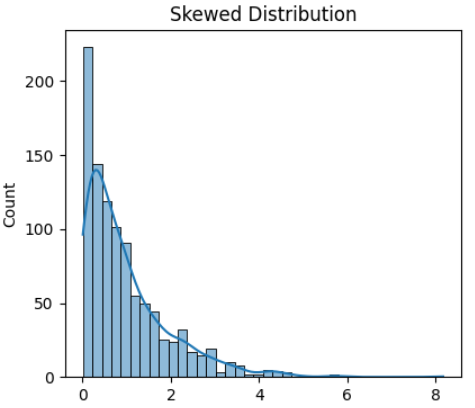
공역(y값 집합)입장에서 생각해보면
y입장에서 200이 넘는 값은 1번밖에 없는데, 60이 넘는 값은 5번이고 1이 넘는 값은 엄청 많네요. 크기가 작은 값에 밀집해있다는 뜻이죠
결국 왼쪽으로 치우친 그래프는 정규분포처럼 바뀌려면 x값이 작을 때는 차이를 크게(기울기를 가파르게), x값이 클 때는 차이를 작게(기울기를 완만하게) 해주는 함수를 만나야해요.
그게 뭐냐? 바로 로그함수입니다
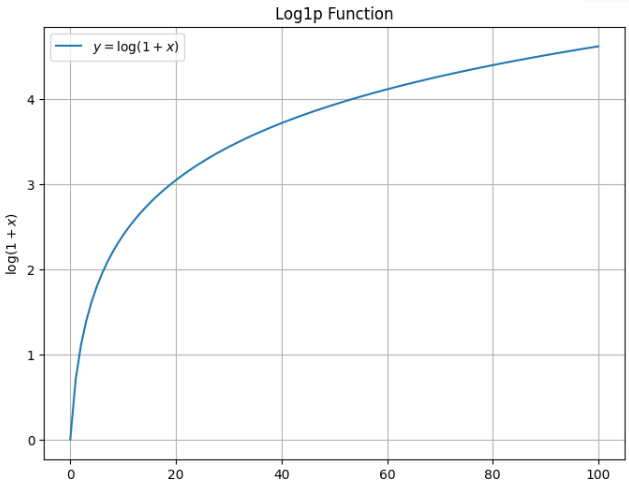
로그는 기울기가 가파르게 증가하다가 어느 순간부터 기울기가 완만해지는 분포를 가지죠.
x의 값이 작은 경우는 차이가 더 강화되고 x값이 큰 경우는 차이가 완만해지는 것이죠
왼쪽으로 치우친 분포는 x가 작을 때 y값이 크고 기울기가 가팔라요
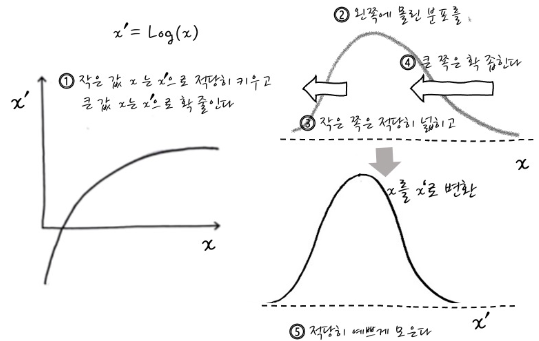
그럼 오른쪽으로 치우친 분포는?
오른쪽으로 치우친 분포는 반대로 로그함수의 역함수인 지수함수로 처리해주면 됩니다.
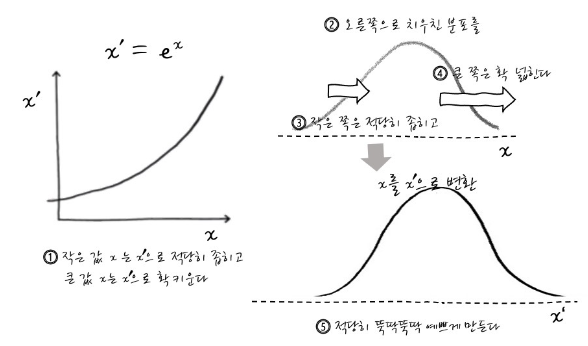
로그는 큰 값을 눌러주는 효과가 있어요.
로그가 취해진 변수를 직관적으로 해석하려면 ln=1/100으로 생각해주면 됩니다.
로그 변환을 적용할 때 유의할 점
-
음수 값: 로그 변환은 음수 값을 처리하지 못하므로, 데이터에 음수가 포함되어 있으면 로그 변환이 적용되지 않습니다. 따라서 데이터에 음수 값이 있는지 먼저 확인해야 합니다.
-
제로 값: 로그 변환은 0에 대해서는 정의되지 않으므로, 데이터에 0 값이 있으면 로그 변환이 적용되지 않습니다. 0 값이 있는 경우에는 보통 1을 더하거나 작은 값을 더해주는 등의 처리를 해야 합니다.
-
역변환: 로그 변환된 값을 사용하여 예측을 수행한 후에는 예측값을 역변환하여 원래 스케일로 되돌려야 합니다. 역변환 시에는 원본 데이터가 사용한 변환과 동일한 변환을 적용해야 합니다. 역변환을 하지 않으면 MSE와 R² 값이 왜곡되어 실제 모델의 성능을 제대로 평가할 수 없음을 알 수 있습니다.
Q. 역변환은 언제?
A.변환한 것으로 모델학습 후 성능평가 이전에 역변환!
+참고) 관련 코드
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
from scipy.stats import shapiro, probplot
# 데이터 로드
boston = fetch_openml(name='boston', version=1, as_frame=True)
data = boston.data
data['PRICE'] = boston.target
# 종속 변수와 독립 변수 분리
X = data.drop('PRICE', axis=1).astype('float')
y = data['PRICE'].astype('float')
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 제곱근 변환 (sqrt)
y_train_sqrt = np.sqrt(y_train)
y_test_sqrt = np.sqrt(y_test)
# 제곱근 변환 후 정규성 테스트
stat, p_value = shapiro(y_train_sqrt)
print(f'Shapiro-Wilk Test after Square Root Transform: Statistic={stat:.4f}, p-value={p_value:.4f}')
if p_value > 0.05:
print('The transformed variable follows a normal distribution (fail to reject H0)')
else:
print('The transformed variable does not follow a normal distribution (reject H0)')
# 시각적 확인
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
sns.histplot(y_train_sqrt, kde=True)
plt.title('Square Root Transformed Target Distribution')
plt.subplot(1, 2, 2)
probplot(y_train_sqrt, dist="norm", plot=plt)
plt.title('Q-Q Plot of Square Root Transformed Target')
plt.show()
# 선형 회귀 모델 (제곱근 변환 후)
model_sqrt = LinearRegression()
model_sqrt.fit(X_train, y_train_sqrt)
y_pred_sqrt = model_sqrt.predict(X_test)
# 예측값을 역변환
y_pred_sqrt_inv = y_pred_sqrt ** 2
# 성능 평가 (제곱근 변환 후)
mse_sqrt = mean_squared_error(y_test, y_pred_sqrt_inv)
r2_sqrt = r2_score(y_test, y_pred_sqrt_inv)
print(f'MSE with Square Root transform: {mse_sqrt:.4f}')
print(f'R2 with Square Root transform: {r2_sqrt:.4f}')
# 원래와 예측된 값 분포 비교
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
sns.histplot(y_test, kde=True)
plt.title('Original Target Distribution')
plt.subplot(1, 2, 2)
sns.histplot(y_pred_sqrt_inv, kde=True)
plt.title('Predicted Target Distribution after Inverse Transform')
plt.show()
로그변환했는데 성능이 더 안좋아진 경우&정규성확보가 안된 경우
- 비선형성을 잘 처리할 수 있는 트리기반 모델 or 딥러닝 모델로 종류를 변경
- box-cox 등 다른 변환 방법 시도
- 변환 적용 x
- 종속 변수의 정규성보다는 잔차의 정규성을 확인하여 선형 회귀 모델의 적절성을 평가
제곱근 변환이나 Box-Cox, Yeo-Johnson 변환 후에도 변수가 여전히 정규분포를 따르지 않는 경우, 예를 들어, 비선형 모델을 사용하거나, 정규성을 가정하지 않는 다른 모델을 사용 추천
Reference
