문제


내가 푼 풀이
def solution(citations):
answer = 0
citations = sorted(citations, reverse = True)
h = max(citations)
while 1:
cnt = 0
for i in citations:
if i >= h:
cnt += 1
if cnt >= h:
answer = h
break
h -= 1
return answer✔ 처음에 작성한 코드는 테스트 케이스는 통과해도 제출하면 실패가 떴다ㅠ. 문제를 잘못 이해해서 그런 거 였다. 답이 citations안에 있어야한다고 생각했는데 그게 아니었다! 그걸 깨닫고 나니 어떻게 풀어야 할지 생각이 났다.
그렇게 잘 짠 코드는 아닌 것 같다..ㅠ 그래도 맞춰서 기쁘긴 하네...😂
좋아요가 가장 많았던 풀이
def solution(citations):
citations.sort(reverse=True)
answer = max(map(min, enumerate(citations, start=1)))
return answer하 이런 풀이들 볼 때마다 공부한다고 늘긴 하는 걸까 싶다..그래두..꾸준히 공부해나가야겠지....
✔ enumerate()
🙊 start는 여기서 처음 봤다!
- enumerate( 반복가능한 객체(리스트,튜플,문자열), start = 1 )
- enumerate(a, start = 1)란?
 ⬇ 결과
⬇ 결과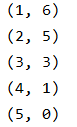
- enumerate(a)
 ⬇ 결과
⬇ 결과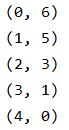 => 즉, start는 그냥 index값을 0이 아닌 지정값으로 시작하게 해주는 것 뿐이고 인자로 주어진 배열의 index를 지정값부터 가져오겠다는 의미가 아니다..!(처음에 그렇게 착각함ㅎ)
=> 즉, start는 그냥 index값을 0이 아닌 지정값으로 시작하게 해주는 것 뿐이고 인자로 주어진 배열의 index를 지정값부터 가져오겠다는 의미가 아니다..!(처음에 그렇게 착각함ㅎ) - (index, value)의 형태로 반환함.
✔ map()
- map( 변환 함수, 순회 가능한 데이터 )
- 두번째 인자로 넘어온 데이터가 담고 있는 모든 데이터에 변환 함수를 적용하여 다른 형태의 데이터를 반환
- for문으로 일일이 하는 것보다 편리하니까!
- min함수를 변환함수로 주면 결과가 어떻게 나오는지 짐작 가지 않았다...
print(list(map(min, enumerate(citations, start=1)))) #citations = [6, 5, 3, 1, 0]출력 : [1, 2, 3, 1, 0]
=> 각각 index와 value 중에서 작은 값을 반환한다.
(1, 6) => 6번 이상 인용된 논문 개수 : 최소 1개 이상
(2, 5) => 5번 이상 인용된 논문 개수 : 최소 2개 이상
(3, 3) => 3번 이상 인용된 논문 개수 : 최소 3개 이상
(4, 1) => 1번 이상 인용된 논문 개수 : 최소 1개 이상
(5, 0) => 0번 이상 인용된 논문 개수 : 최소 5개 이상
🔑 즉, h값들의 집합이 된다!!
=> max(map(min, enumerate(citations, start=1)))는 min들(h들) 중에서 제일 큰 값을 반환. 3!!!!!
citations를 내림차순으로 정렬했으니까 결국 인덱스는 개수가 되기 때문.
어떻게 이런 생각을 하지??놀랍다..

https://github.com/ono212