문제
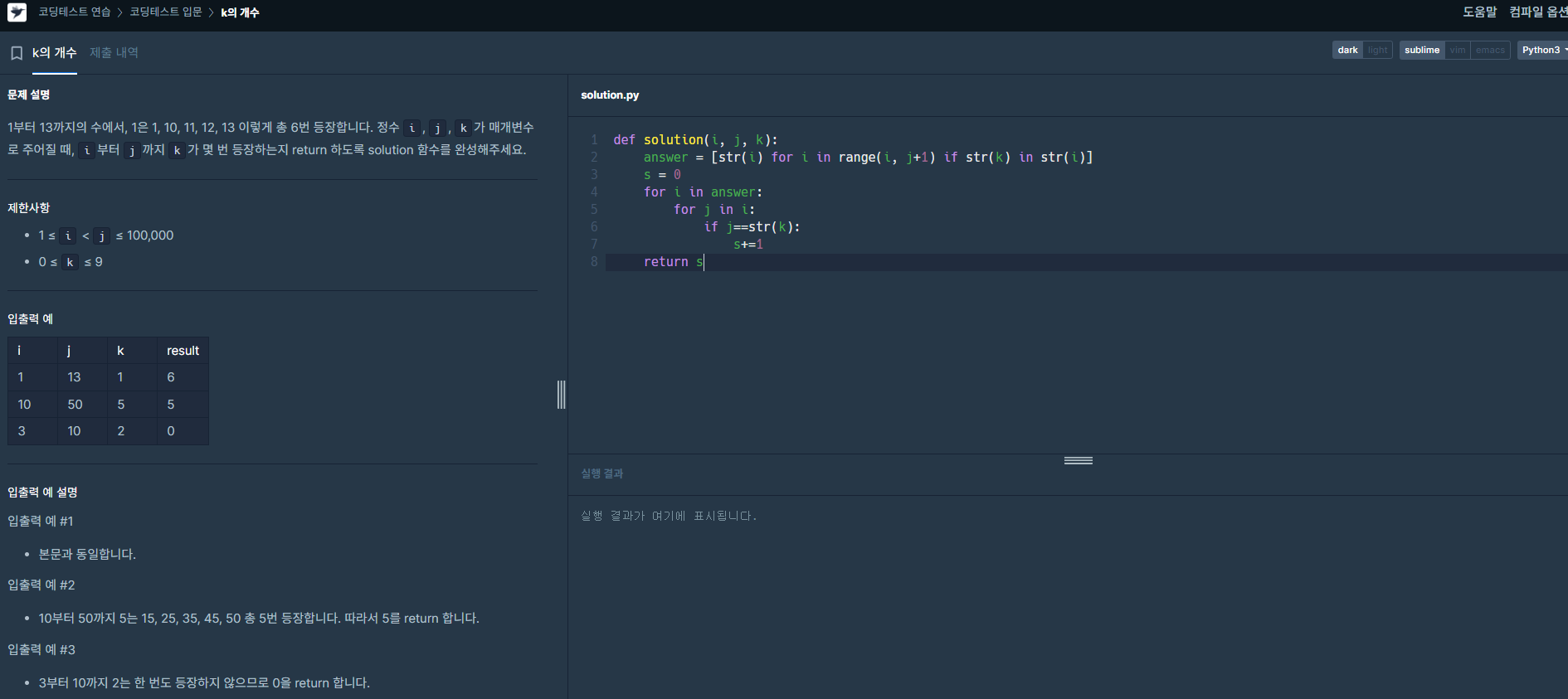 먼저 숫자 'k'가 들어 있는 숫자 조합은 모두 리스트에 넣고 그 원소를 다시 쪼개서 'k'가 들어간 숫자만큼 더하는 결과를 구했다.
먼저 숫자 'k'가 들어 있는 숫자 조합은 모두 리스트에 넣고 그 원소를 다시 쪼개서 'k'가 들어간 숫자만큼 더하는 결과를 구했다.
다른 풀이
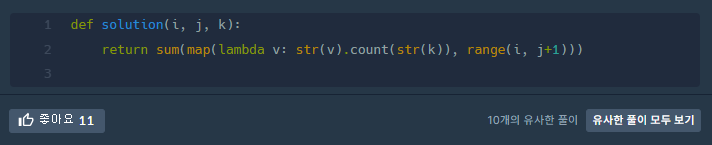 python 답게 sum, map을 이용하였으며 count를 이용하여 더욱더 간단하게 구현하였다.
python 답게 sum, map을 이용하였으며 count를 이용하여 더욱더 간단하게 구현하였다.
Count
방금 윗 풀이에서 count를 공부해보자면 count는 문자열 안에서 찾고 싶은 문자의 개수를 찾을 때 사용하며, tuple, list, set 같은 반복 가능한 iterable 자료형에서 사용 가능하다.
사용법은 변수.count(찾는 요소)로 결과값으로 값의 개수를 숫자로 반환한다.
Counter 클래스
- collection 모듈의 Counter 클래스를 사용
- 리스트와 문자열 모두 사용 가능
from collections import Counter
arr = ['a','b','c','dd','b','g','zz','k','k']
print(Counter(arr))
#Counter({'b': 2, 'k': 2, 'a': 1, 'c': 1, 'dd': 1, 'g': 1, 'zz': 1})이 때 타입은 <class 'collections.Counter'> 이다.
string = 'abracadabra'
strin = Counter(string)
print(strin)
#Counter({'a': 5, 'b': 2, 'r': 2, 'c': 1, 'd': 1})string = 'abracadabra'
cnt = Counter(string) #Counter({'a': 5, 'b': 2, 'r': 2, 'c': 1, 'd': 1})
print(cnt['a']) #5most_common() 메서드
- 데이터가 많은 순으로 정렬된 배열을 리턴
- 매개변수를 생략하면() 모든 요소를 반환하고, (n)은 가장 많은 n개를 반환
아래의 코드로 Counter와 Counter.most_common()의 차이를 확인해보자.
new_str = 'hello world!'
cntnew = Counter(new_str) #Counter({'l': 3, 'o': 2, 'h': 1, 'e': 1, ' ': 1, 'w': 1, 'r': 1, 'd': 1, '!': 1})
print(cntnew)
print(type(cntnew)) #<class 'collections.Counter'>common = Counter(new_str).most_common() #[('l', 3), ('o', 2), ('h', 1), ('e', 1), (' ', 1), ('w', 1), ('r', 1), ('d', 1), ('!', 1)]
print(common)
print(Counter(new_str).most_common(3)) #[('l', 3), ('o', 2), ('h', 1)]
print(type(common)) #<class 'list'>

책 묵는 개발자