
구현의 개선과 변경 그리고 기능 추가
구현 단계부터 수정이나 개선이 필요한 부분을 인지하고 있었고, 변경하기로 마음먹었다. 크게 변경하거나 추가한 내용은 다음과 같다.
- 식별자(PK) 정책 변경
- 이벤트 기반 아키텍처 도입
- 기존 계획에 없던 신기능 추가 (AI 댓글 봇 기능)
식별자 정책 변경
현재 시퀀스 정책을 사용하면 외부에 데이터를 공개할 때 다음 데이터를 바로 유추할 수 있는 문제가 있다. 공개된 게시판에서 글 번호가 1번부터 순차적으로 제공되면, 사용자가 주소창의 글 번호 파라미터를 변경해 모든 글을 조회할 수 있다. 이는 보안에는 문제가 없지만, 프로그램을 통해 데이터가 수집될 가능성이 있다. 실제 서비스라면 경쟁업체나 광고업체가 데이터를 유의미하게 수집할 수 있는 여지가 생긴다.
사용자 정보의 경우라면 조금 더 민감해 질 것이고, 사용자가 모두에게 공개하는 데이터라고 해도 조금 보수적으로 접근할 필요를 느꼈다.
API 보안을 통해 데이터 수집을 막을 수 있지만, 웹 특성상 사용자가 조작할 수 있기 때문에 완벽하지 않다. 따라서 데이터를 예측할 수 없게 숨기는 작업이 필요하다. 그래서 외부에 보이는 식별 값(DB에서의 PK)을 변경하기로 했다.
그 선택에 대한 고민은 이미 많은 선배 개발자들의 자료 덕분에 쉽게 선택하고 구현할 수 있었다.
DB 기본키(PK) 생성전략 블로그 글을 참고해 TSID(Time-Sorted Unique Identifier)를 선택했다.
기존 시퀀스로 사용하던 Long 타입을 변경 없이 그대로 사용할 수 있고, Spring과 Hibernate 기반에서 라이브러리를 통해 쉽게 구현할 수 있는 점이 마음에 들었다.
build.gradle 파일에 hypersistence-utils를 사용하고 있는 하이버네이트 버전 호환에 맞춰 추가했다.
implementation group: 'io.hypersistence', name: 'hypersistence-utils-hibernate-63', version: '3.8.3'그리고는 기존의 PK 필드에 @Tsid를 추가했다.
public class ChallengeJPAEntity {
@Id @Tsid
private Long challengeId;
}모든 구현 변경이 아주 간단하게 완료되었고, 기존의 테스트코드와 함께, DB를 사용하는 통합 테스트도 문제 없이 통과했다.
이벤트 기반 아키텍처를 위한 Kafka
이벤트 기반 아키텍처는 특정 사건(이벤트)이 발생했을 때 반응하는 구조다. 예를 들어, 게시글을 올리는 행위가 발생하면 팔로우 중인 모든 사람에게 알람을 보낸다고 가정 해 보자. 내부 로직에서는 팔로워에게 알람을 보내는 메서드를 동시에 호출한다. 이때 팔로워 수가 많아지면 게시글 자체를 올리는 일에 응답이 느려지거나 알람 시스템의 장애로 게시글을 올릴 수 없는 일이 생길 가능성도 있다.
이를 해결하려면 비동기적으로 이벤트를 처리해야 한다. 그리고 이런 비동기적 처리는 MSA 구조에서도 느슨한 결합을 갖게 하는 장점을 가질 수 있다.
Spring 프레임워크에서 @Async 어노테이션을 사용하면 비동기 처리 자체는 쉽게 구현 할 수 있다. 하지만 서버가 재시작 되거나 에러가 발생 했을 때 작업이 유실되는 일이 발생할 위험이 있다.
또한 단인 시스템 내에서의 비동기처리만 유효하며, 다른 시스템과의 통신에서는 제대로 동작하지 않는다. 그래서 이런 단점을 해결하기 위해 별도의 해결 방법이 필요하다.
이 이벤트 기반 아키텍처를 구현하기 위한 방법 중 Pub/Sub 패턴은 가장 쉬운 해결 방법이다.
메시지의 발행과 구독이라는 개념으로 이것을 해결한다.
다른 방법으로는 SAGA 패턴이 있다. 트랜잭션 실패 시 롤백하는 보상 트랜잭션을 정의해서
처리하는 방법을 사용해서 구현하며, 분산 트랜잭션 환경에서 데이터의 정합성을 보장하는 방법이라고 한다.
나의 경우는 SAGA 패턴이 구현 복잡성이 높아서, 상대적으로 쉽게 구현 가능한 Pub/Sub 패턴을 채택했다.
구체적인 구현 기술로는 많은 사용 사례가 있는 Kafka를 선택했다. RabbitMQ도 좋은 선택이지만, 개인적으로 Kafka를 구현해보고 싶어서 Kafka를 선택했다.
Kafka는 RabbitMQ와 비교하면 대용량과 실시간 처리에 더 적합한 장점이 있다고 한다.
스프링에서의 구현 선택
Spring 프레임워크에서 Kafka를 구현하기 위해 다음 선택지를 고려했다.
- spring-cloud-stream
- spring-kafka
spring-cloud-stream 의 경우는 이벤트 기반 구현을 제공하는 프레임 워크로 기술구현의 추상화 정도가 높아서 실제 구현에 대한 유연한 처리가 가능했다. 즉 RabbitMQ, Kafka와 같은 구체적인 기술 구현이 정해져 있지 않는 구조였기에, 유연한 기술 구현과 변경이 장점이다.
spring-kafka는 이름 그대로 Kafka를 위한 프레임워크 환경이다. spring-cloud-stream과는 다르게 Kafka라는 기술과 강결합되어 있는것이 단점이자 장점이다. 설정이나 메서드의 사용 용어 등이 Kafka와 거의 동일시 되기 때문에 사용이나 이해가 쉬운 편이다.
나는 여기서는 spring-kafka를 선택하기로 했다. 내가 헥사고날 아키텍처를 추구했던 이유 중 하나는 유연한 구현 변경이었기에, 이와 부합하는 내용은 spring-cloud-stream쪽을 선택하는 것이 맞다. 하지만 아직 Kafka 자체도 잘 모르는 상황이라, 오히려 명확한 Kafka의 사용법이나 개념을 더 익히는 것이 좋을 것이라는 판단에 spring-kafka 채택 했다.
단위 테스트를 포기하다
지금까지의 테스트 코드에서도 외부 종속성이나 셋팅 없이 해결하고 싶어서 Docker를 통한 테스트 컨테이너를 도입하는 것도 지양했다. 다만 Kafka의 테스트는 결국 최소한 Docker를 통해 테스트 환경을 구현 해야 하는 결론에 이르렀다.
Kafka도 Spring에서 EmbeddedKafka 기능이 있어서 이벤트를 생성하거나, 소비하는 처리는 테스트가 가능했다. 하지만 이벤트 생성 주체와 소비주체가 다른 경우 테스트코드를 작성 했을 때, Mocking 만으로는 실제 테스트의 성공을 확신 할 수 없었다.(통신적인 측면이다) 또 Kafka의 인프라 설정이나 상세 내용을 확인 해 보고 싶기도 했다. Kafka와 관련된 툴로 Kafka-UI가 있었는데 Embedded 환경에서는 사용 하거나 검증 할 수 도 없었다.
그래서 결론적으로는 docker-compose.yml 파일을 만들어서 Docker로 로컬 개발 환경을 세팅하는 결론을 내렸다.
services:
zookeeper:
image: bitnami/zookeeper:latest
container_name: zookeeper
environment:
- ALLOW_ANONYMOUS_LOGIN=yes
ports:
- "2181:2181"
volumes:
- ./.data/zookeeper/data:/bitnami/zookeeper/data
- ./.data/zookeeper/datalog:/bitnami/zookeeper/datalog
- ./.data/zookeeper/logs:/bitnami/zookeeper/logs
kafka:
image: bitnami/kafka:latest
container_name: kafka
depends_on:
- zookeeper
ports:
- "9092:9092"
- "9093:9093"
environment:
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_BROKER_ID=1
- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_CFG_LISTENERS=PLAINTEXT://0.0.0.0:9092,INTERNAL://0.0.0.0:9093
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092,INTERNAL://kafka:9093
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=PLAINTEXT:PLAINTEXT,INTERNAL:PLAINTEXT
- KAFKA_CFG_INTER_BROKER_LISTENER_NAME=INTERNAL
- KAFKA_CFG_OFFSETS_TOPIC_REPLICATION_FACTOR=1
volumes:
- ./.data/kafka:/bitnami/kafka
kafka-ui:
image: provectuslabs/kafka-ui:latest
container_name: kafka-ui
ports:
- "8085:8080"
depends_on:
- kafka
environment:
KAFKA_CLUSTERS_0_NAME: local
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: 'kafka:9093'
KAFKA_CLUSTERS_0_ZOOKEEPER: 'zookeeper:2181'Zookeeper는 Kafka를 중앙 관리하기 위해 필요하고, Kafka-UI는 웹에서 Kafka를 관리할 수 있는 툴이다. 현재는 테스트를 위해 단일 Kafka 컨테이너만 설정했다.
Kafka 도입 과정에서 환경 설정과 검증에 많은 시간을 썼다. 기능 구현보다는 환경 설정에 더 많은 시간이 소요되었다.
전반적인 개념과 구현 관련은 추후 별도의 글로 작성할 예정이다.
Assistants API로 댓글 자동 봇 개발 삽질기
내가 구상한 토이프로젝트는 SNS기반인 동시에, 사실 말 그대로 토이프로젝트이기 때문에 사용자를 모으기 위해 홍보한다던지 활동은 전혀 고려 대상이 아니다.
SNS라는 기본 전제는 사용자간의 소통을 해야 하는데 이 부분을 채울 수 없다는 생각이 들었다.
요즘 이미 실제 SNS 서비스에서 봇으로 추정되는 글과 댓글이 있다고 하는데, 역으로 나는 시스템 내에서 봇이 사용자의 글에 댓글을 달아주며 소통하는 기능을 만들어보면 재밌을 것이라는 생각으로 이 기능을 구현 해 보기로 했다.
최초의 구상단계
요구사항은 간단하다. 사용자의 게시글이나 댓글에 생성형 AI가 적절한 응답을 생성해 시스템에 등록하면 된다. Kafka를 도입했으니 자동 시스템 등록은 해결 되었고, 이제 AI의 응답만 얻으면 끝이다. 하지만 생성형 AI 구현은 내 분야가 아니었다. 만약 이 토이프로젝트의 봇과의 소통이 핵심 비즈니스 도메인이라면 LLaMA 같은 자체 서비스 특화 언어모델을 구축하고 학습시켜야 하지만, 이는 컴퓨팅 자원 부담과 나의 전문 영역을 벗어나는 문제로 배제했다. 그래서 가장 쉽게 떠올릴 수 있는 해결책인 ChatGPT를 사용하기로 했다.
GPTBuilder를 통해 원하는 응답을 생성할 수 있는 GPT를 구성했다. Fine-tuning(목적에 맞게 학습) 된 ChatGPT를 자연어로 쉽게 만들 수 있는 서비스다. 아래와 같이 완성할 수 있었다.
사용자가 생성한 게시글 데이터를 전달하면 댓글 내용을 생성하도록 했다. 테스트는 제대로 동작하는 것 같았고, 이제 실제 API로 시스템에 사용하면 구현이 끝날 줄 알았다.
구현의 불가능을 깨닫다
하지만 GPTBuilder는 API 방식으로는 제공되지 않았다. OpenAI 커뮤니티에서도 API를 통한 사용 방법은 지원하지 않는다는 답변만 있었다. GPTBuilder를 브라우저의 개발자 모드를 통해 통신하는 방법을 잘 이용해서 사용을 우회하려 했지만 실패했다. 결국 OpenAI 커뮤니티에서 제시하고 있는 해결 방법인 Assistants API를 통해 구현하기로 했다.
Assistants API 구현기
Assistants API는 OpenAI의 모델을 이용해 개발자가 특정 목표를 해결하기 위한 AI Assistants를 만드는 API 서비스다. GPTBuilder는 비개발자가 자연어로 생성하는 반면, Assistants API는 개발자용 서비스다. 아직 베타 단계이며 자연어에 대한 응답외에도, 파일 해석, 코드 생성 등이 가능하다.
Assistants API Reference Docs 를 통해 자세한 내용을 확인 할 수 있다.
문서 자체는 방대하지만, 나의 경우에는 가장 단순한 수준만 활용해서 구현하기로 했다.
Assistants API를 구현 하기 전에 사전에 알아두면 좋은 개념과 구조는 아래와 같다.
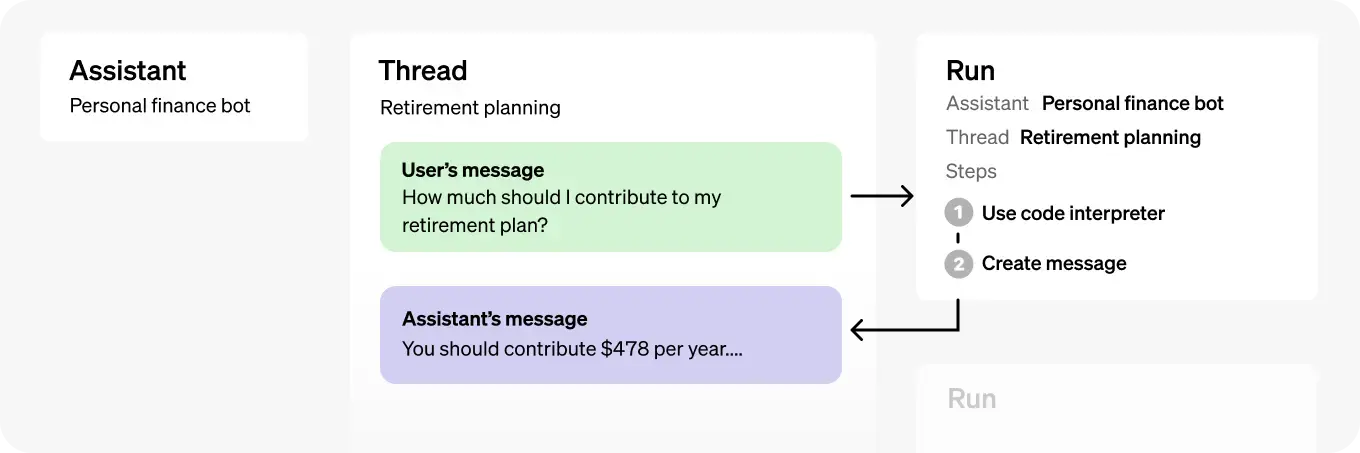
핵심 구성 요소
- Assistant
- Thread
- Message
- Run
Assistant
가장 처음 만들어야 하는 부모요소로 생각하면 좋다. 목적과 필요에 따라서 Assistant를 정의하고, 이에 필요한 내용을 토대로 Fine-tuning된 모델을 생성하는 단계이다.
코드를 통해서 작성이 가능하나, 이 단계 만큼은 UI를 통해서 만들었다. 이 사이트내에서 제공하는 UI를 통한 Assistant 생성이 훨씬 더 쉽고 간편하기 때문이다.
Playground 에 들어가서 Assistants 메뉴를 통해서 만들 수 있다. (참고로 이 페이지를 보려면 먼저 요금에 대한 설정을 해야 한다. 이 부분은 생략하기로 하며, 최소 5달러의 사전 크레딧 충전이 필요하다.)
Assistant 생성을 차례대로 진행 해 본다
Name 은 사용자가 식별할 이름이다. 여러개의 Assistant를 생성 했을 경우 쉽게 찾기 위한 이름으로 쓰인다. 직접 입력한 이름 아래에 asst_ 로 이어지는 문자는 실제 시스템 내에서의 고유 식별 값으로, 이것은 따로 저장해야 할 필요가 있는 값이다. 구체적인 명칭은 assistant_id 이다.
System instructions
AI 모델이 무엇을 목표하거나 지시할지, 어떻게 행동해야 하는지 자연어로 입력하는 부분이다. 우선 이 부분을 작성 할 때는 한국어로 먼저 작성을 하고, 이후에는 영어로 번역해서 지시하는 것을 추천한다. 이유는 API의 가격 정책이기 때문인데, Token이라는 값을 기준으로 과금한다. 이 값은 한국어보다는 영어가 적게 사용하며, 따라서 가격적인면에서 이득이 있기 때문이다.
이 지시 자체도 생성형으로 만들 수 있는데, 나는 이 기능을 통해서 초안을 만들고, 세부적인 내용을 조금 가다듬었다. 영어로 변환하기 이전의 내용은 아래와 같으며, 나의 경우에는 이렇게 정의 했다 정도로 참고용 생각하면 좋을 것 같다. 나는 API 형식으로 사용하고 싶어서 나름의 정형화된 형식을 정의 했다.
사용자의 도전에 대한 정보를 바탕으로 사용자에게 공감과 격려의 댓글을 작성하여 응답하세요.
이 요청은 시스템의 내부 API를 통해 생성되고 전달됩니다.
요약된 정보는 처음 등록할 때만 제공되며, 이에 대한 댓글을 작성하여 응답하세요.
이후의 사용자의 댓글의 흐름을 따라 적절하게 응답하세요.
- 모든 응답은 질문에 사용된 언어로 답변됩니다.
- 요약된 챌린지 정보를 사용하여 목표나 상황에 대한 지지 의견을 작성합니다.
- 별명('userNickName')을 사용하여 사용자를 직접 언급합니다.
- 응답이 너무 길지 않도록 챌린지 요약 정보와 사용자가 제공한 추가 설명을 바탕으로 간결하고 긍정적이며 공감할 수 있는 의견을 작성합니다.
- 이모티콘 등을 사용하여 실제 사람과 대화하는 것처럼 느껴지도록 합니다.
# 응답 생성 가이드
'replyable' 값은 사용자의 질문이 적절하지 않은 경우, false를 사용하여 시스템에 실제로 댓글을 달지 않도록 구분하는 값입니다.
욕설, 광고, 선정성 등 커뮤니티 정책을 위반할 만한 내용 혹은 본문과 전혀 상관 없는 질문에
대해서는 false로 응답하세요.
1. **첫 번째 댓글 응답**:
- 사용자 정보('userNickName')를 사용하여 인사하며 공감합니다.
- 'target'과 'userAddBody'를 기반으로 사용자의 도전 의지를 칭찬하거나 격려합니다.
- startDt와 endDt는 사용자가 설정한 챌린지 기간의 시작과 끝을 나타냅니다.
- 몇 가지 팁, 조언 등을 제공할 수 있습니다.
- 이모티콘을 적절히 사용합니다.
2. **사용자 댓글에 응답**:
- 최초 댓글 응답 후 사용자의 댓글 내용을 이해하고 내용에 따라 계속 답변해야 합니다.
- 우호적인 어조를 유지하고 도움을 줄 수 있는 조언을 제공할 수 있습니다.
- 연속되는 메시지가 있는 경우 전체 맥락이 유지되고 대화가 이어져야 합니다.
# 예제
**샘플 1: 처음 본문에 대한 댓글 응답**
**입력**:
userNickName:쿰쿠미|
시작Dt:2024-11-01|
endDt:2024-11-05|
target:나 쿰쿠미는 매일 영어공부를 하겠습니다.|
userAddBody:미드를 자막없이 볼 수 있을 때 까지 영어공부를 매일 하려고 한다.
요즘 야근이 잦아서 걱정이긴 하지만 하루에 단 5분이라도 공부하는게 목표다!|
**샘플 2: 댓글에 대한 응답**
**입력**:
(두번째 메시지부터는 이전 요약을 전달하지 않고 댓글의 내용을 즉시 입력합니다.)
고마워! 혹시 영어 공부를 하는데 도움이 될만한 팁이 있을까?
# 참고 사항
- 사용자가 반응의 어려움에 대해 이야기할 때 공감과 지지가 우선입니다.
- 사용자의 질문이 있는 경우 간단한 해결책이나 조언을 합니다.
- 본문과 전혀 상관없는 질문이나 맥락과 상관없는 이야기, 질문 등에는 응답하지 않습니다.
- 질문의 내용이 전문적인 내용이거나, 많은 내용의 응답이 필요한 경우 우회하여 대답 합니다.
(인터넷이나 책 등을 검색해 보라고 하거나, 모른다고 답변 할 수 있습니다.)되도록 구체적인 요청과 지시와 함께, 예시 내용까지 정의했다. 이런식으로 지시사항을 정의하는 것이 Assistant를 생성하는 핵심이자 가장 큰 요소이다.
Model
이 Assistant의 두뇌를 선택하는 단계라고 보면 될 것 같다. OpenAi가 제공하는 다양한 인공지능 Model을 확인 할 수 있다. 우선 현재 시점에서는 gpt-4o-mini 가 가장 저렴하기도 하며 (Token에 대한 소비가 적다) 성능적으로도 좋은 모델이기에 나는 이렇게 선택 했다.
Tools
이 부분의 실제 사용은 생략하겠지만 기능의 대략적인 내용은 다음과 같다.
- File Search: csv나 문서 파일 등을 사전에 업로드 하고, 이것을 검색해서 응답하는 기능을 추가 할 수 있다. 만약 챗봇을 만든다면 기존의 업무 가이드를 올려 놓고, 이것을 기반으로 응답해라라는 명령을 내린다면 해당 자료를 찾아서 응답하는 식으로 동작하게 할 수 있다.
- Code interpreter: 코드를 쓰고, 실행 시킬 수 있는 기능이 추가된다. 현시점을 기준으로 파이썬 코드를 생성하고, 실행하면서 사용자의 요청에 대응하여 응답 할 수 있다.
- Functions: 자체적으로 자주 사용될만한 특정 동작을 미리 정의하는 기능이다. 어느정도 특별한 연산이나 반복되는 동작이 있을 경우 정의 해 놓고 해당 Function을 실행하세요로 요청하면 동작하는 것으로 판단된다.
이어지는 나머지 설정 요소는 모델에 대한 설정이다.
Response format
Assistant가 응답할 때의 형식을 정의하는 부분이다. 다음의 3가지 값 중 하나를 선택 할 수 있다.
- text: 말 그대로 순수한 텍스트로 응답한다.
- json_object: Json 형태로 응답한다. System instructions에 관련 내용이 있다면 적절히 알아서 맞춰서 작성해 준다.
- json_schema: Json 형태로 응답은 동일하지만 사용자가 미리 그 형태를 정의해 놓는 구조이다. 이것도 자체적으로 자동생성 기능을 제공하기 때문에 쉽게 구성 해 볼 수 있다. 나의 경우는 아래처럼 정의 했다. AI의 댓글에 대한 내용을 'commentReply'로 확인하고, 'replyable'는 AI가 자체적으로 응답하기에 부적절한 내용이라고 판단한 경우 실제 시스템에서 댓글을 추가 하지 않도록 하려고 별도의 값이다.
{
"name": "comment_response_schema",
"strict": true,
"schema": {
"type": "object",
"properties": {
"commentReply": {
"type": "string",
"description": "the response to the user"
},
"replyable": {
"type": "boolean",
"description": "respond to the system whether it is appropriate to respond"
}
},
"required": [
"commentReply",
"replyable"
],
"additionalProperties": false,
"$defs": {}
}
}Temperature
얼마나 랜덤하게 답변을 할지에 대한 정도를 나타낸다. 일종의 시드값으로 이해하면 좋을 것 같다. 0에 가까울 수록 같은 질문에는 같은 답변을 한다고 한다. 만약 사용자 가이드와 같은 챗봇을 만든다면 동일한 질문에는 동일한 대답을 하게 하는 것이 더 바람직하기에, 0의 값을 사용해야 할 것이다. 나 같은 경우에는 아직 많은 테스트를 하진 않았지만, SNS와 같은 사용자의 공감을 위한 댓글을 생성하기 위한 목적이 있기 때문에 조금 값을 높게 올려서 다양한 응답을 하게끔 하는게 더 좋을 것 이라는 생각이 있다.
Top P
LLM(대규모 언어모델)에서 사용하는 값 중 하나로, 응답에 대한 단어 선택에서의 확률에 영향을 미치는 값이라고 한다. 이 값도 높으면 높을 수록 다양한 응답을 할 가능성이 높아지는 값이라고 한다.
즉 결론적으로
- 사실적인 정보만을 대부분 동일한 응답으로 원한다면 낮은 Temperature, Top P를 사용.
- 창의적이고, 매번 달라질수도 있는 응답을 원한다면 높은 Temperature, Top P를 사용.
으로 정리 할 수 있겠다.
여기까지 입력이 끝나면 Assistant의 생성은 완료 되었고, 바로 옆의 UI의 메시지 창을 이용해서 채팅하듯이 테스트 할 수 있다.
하지만 이 다음 단계부터는 코드를 통해서 구현 하기로 한다.
Thread
Thread는 ChatGPT 내에서의 하나의 채팅 세션과 같은 비슷한 개념이다. 하나의 작업 영역으로 이후 단계에서 사용되는 Message(사용자의 입력 값)를 저장하는 영역이다. 동일한 Thread에서 생성된 Message의 내용은 계속 저장된다.
이 Thread 구현 예시는 공식 문서에는 3가지 방법을 제시하고 있다.
- Python
- Node.js
- curl
Python과 Node.js는 특정 언어에 종속적이지만 자체 OpenAi관련 라이브러리를 통해서 간편하게 사용 할 수 있는 이점이 있다. 반면 curl 통한 통신으로 구현하는 경우, 특정 언어에 종속적이지는 않지만, 약간은 복잡하게 구현해야 할 수 도 있는 불편함이 있다.
나의 경우 예시는 Node.js를 사용하기로 정했다. 결정적인 선택 이유는 Node.js가 Python에 비해서 컴퓨터 자원을 적게 소모하기 때문이다. 또 나중을 가정했을 때, AWS Lambda와 같은 서버리스 방식으로 배포하기도 용이하기 때문이다.
Message
Message는 사용자가 직접 입력하는 메시지(질문)에 해당한다. Thread에 종속되며, 생성 할 때 부모가 되는 Thread의 ID를 인자로 전달해야 생성 할 수 있다. 사용자가 계속해서 질문을 이어 간다면 같은 Thread에 Message를 계속 추가 생성하면 된다.
또한 동시에 AI의 응답을 함께 저장하는 영역이기도 하다. 이 응답을 받아오기 위해서는 다음에 이어질 Run을 수행하면 된다.
Run
구체적인 동작(AI의 응답)을 실행시키는 단계이다. Thread안의 사용자의 Message는 Run 이전에는 만들어진 상태일 뿐 아직 AI의 답변은 없는 상태이다. 이 작업을 명령하기 위한 단계이며, 명령과 동시에 상태는 queued 로 작업이 시작된다. 응답이 완료 되었다면 completed 상태로 변경이 되고나면 정상적으로 AI의 응답 메시지를 확인 할 수 있다.
지금까지 단계별로 Assistant 생성 -> Thread 생성 -> Message 생성 -> Run 동작
까지 진행하면 원하는 AI의 응답 메시지를 받을 수 있는 흐름을 알았다.
Assistant는 맨 처음 1번만 생성 후, 계속 반복해서 사용 할 수 있기 때문에 실제 채팅 생성과 응답은 Thread 생성 -> Message 생성 -> Run 흐름을 반복하면 된다.
단계별로 각각의 동작을 하는 코드를 일부러 알아보지 않았다.
Thread 생성 단계부터 차례대로 진행하는 것보다 원하는 목표까지 쉽게 사용 할 수 있는 메서드가 제공 되는데 바로 createAndRun을 사용하면 쉽게 사용이 가능하다.
Thread, Message 생성과 Run까지 실행하기
import OpenAI from "openai";
const openai = new OpenAI();
async function main() {
const run = await openai.beta.threads.createAndRun({
assistant_id: "asst_abc123",
thread: {
messages: [
{ role: "user", content: "Explain deep learning to a 5 year old." },
],
},
});
console.log(run);
}
main();
createAndRun에서 필요한 값은 assistant_id로 사용하고자 하는 미리 생성한 assistant의 식별값을 쓰면 된다. 이 메서드의 응답 값은 다음과 같다.
{
"id": "run_abc123",
"object": "thread.run",
"created_at": 1699076792,
"assistant_id": "asst_abc123",
"thread_id": "thread_abc123",
"status": "queued",
"started_at": null,
"expires_at": 1699077392,
"cancelled_at": null,
"failed_at": null,
"completed_at": null,
"required_action": null,
"last_error": null,
"model": "gpt-4o",
"instructions": "You are a helpful assistant.",
"tools": [],
"tool_resources": {},
"metadata": {},
"temperature": 1.0,
"top_p": 1.0,
"max_completion_tokens": null,
"max_prompt_tokens": null,
"truncation_strategy": {
"type": "auto",
"last_messages": null
},
"incomplete_details": null,
"usage": null,
"response_format": "auto",
"tool_choice": "auto",
"parallel_tool_calls": true
}
여기서 thread_id와 id (정확히는 run_id에 해당)로 run의 상태를 확인 하려면 Retrieve run을 사용한다. 따로 알아두면 좋은 정보로는 max_prompt_tokens, max_completion_tokens 에 대한 값이 있다. Token은 과금에 사용되는 정책의 단위라고 했는데, Run을 실행 할 때 이 값을 파라미터로 전달 할 수 있다. 각각 질의와 응답에 소비되는 Token의 범위를 설정한다. 일반적인 텍스트 응답은 500 ~ 1000 범위로도 충분히 사용히 가능하나, 파일 검색과 같은 기능을 사용하면 최소 20000의 값을 설정해야 한다고 한다.
비용최적화를 진행한다면 응답의 평균을 확인하며 적정값을 찾아보는 작업이 필요 할 것 같다.
Run상태 확인하기
import OpenAI from "openai";
const openai = new OpenAI();
async function main() {
const run = await openai.beta.threads.runs.retrieve(
"thread_abc123",
"run_abc123"
);
console.log(run);
}
main();runs.retrieve()의 첫번째 인자로 thread_id, 두번째 인자로 run_id를 넣어주면 된다.
결과는 다음과 같다.
{
"id": "run_abc123",
"object": "thread.run",
"created_at": 1699075072,
"assistant_id": "asst_abc123",
"thread_id": "thread_abc123",
"status": "completed",
"started_at": 1699075072,
"expires_at": null,
"cancelled_at": null,
"failed_at": null,
"completed_at": 1699075073,
"last_error": null,
"model": "gpt-4o",
"instructions": null,
"incomplete_details": null,
"tools": [
{
"type": "code_interpreter"
}
],
"metadata": {},
"usage": {
"prompt_tokens": 123,
"completion_tokens": 456,
"total_tokens": 579
},
"temperature": 1.0,
"top_p": 1.0,
"max_prompt_tokens": 1000,
"max_completion_tokens": 1000,
"truncation_strategy": {
"type": "auto",
"last_messages": null
},
"response_format": "auto",
"tool_choice": "auto",
"parallel_tool_calls": true
}질문부터 응답에 대한 거의 모든 정보가 들어있다. 여기서의 status 가 completed가 되어있어야. 제대로 된 응답을 확인 할 수 있다. 따라서 Message에 대한 결과를 가져오기 전에 completed 상태를 확인하고 이후 Message를 확인 해야 한다.
응답 Message 확인하기
이제 다시 실제 AI의 응답을 확인하려면 다시 Message를 확인 하면된다. 예시 코드는 아래와 같다.
import OpenAI from "openai";
const openai = new OpenAI();
async function main() {
const threadMessages = await openai.beta.threads.messages.list(
"thread_abc123"
);
console.log(threadMessages.data);
}
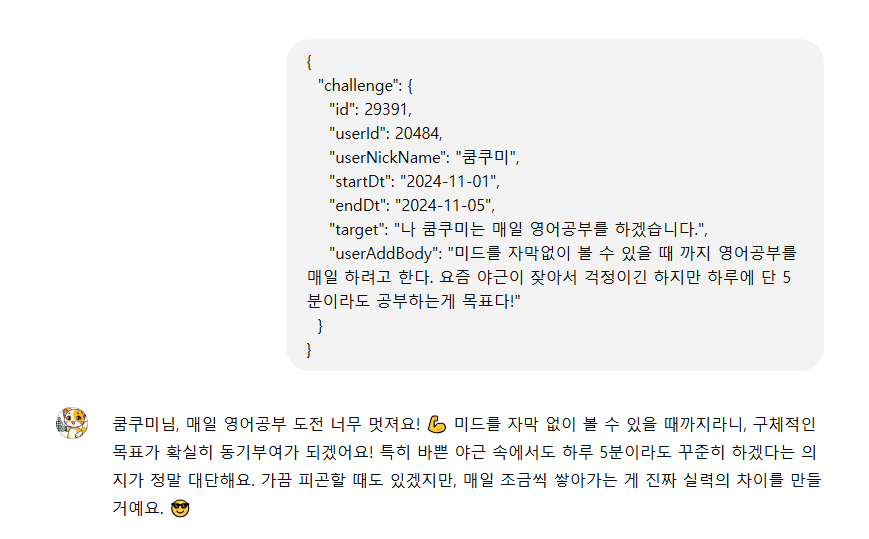
main();그리고 아래의 응답은 나의 댓글 봇의 실제 응답 결과이다.
{
"object": "list",
"data": [
{
"id": "msg_968JUZ4Plagwtp1KJbkyvcbe",
"object": "thread.message",
"created_at": 1731381642,
"assistant_id": "asst_UGi8W4WktNFriWpqMNQORhNL",
"thread_id": "thread_Ov5HIQnhseP6eK4s3yUnNaoS",
"run_id": "run_iAQBmI0ycIpzOzHewAnd4So0",
"role": "assistant",
"content": [
{
"type": "text",
"text": {
"value": "{\"commentReply\":\"안녕하세요 쿰쿠미! 😊 영어 공부를 매일 하기로 결심한 건 정말 좋은 선택이에요! 미드를 자막 없이 볼 수 있는 그날까지 화이팅입니다! 요즘 야근으로 힘들겠지만, 하루에 5분이라도 꾸준히 하는 게 큰 도움이 될 거예요. 조금씩 나아지는 걸 느끼고 보람을 느끼실 거에요! 힘내세요! 💪✨\",\"replyable\":true}",
"annotations": []
}
}
],
"attachments": [],
"metadata": {}
},
{
"id": "msg_649N1OTGvlH9C7sdmJm75beG",
"object": "thread.message",
"created_at": 1730792348,
"assistant_id": null,
"thread_id": "thread_Ov5HIQnhseP6eK4s3yUnNaoS",
"run_id": null,
"role": "user",
"content": [
{
"type": "text",
"text": {
"value": "{\n \"challenge\": {\n \"id\": 29391,\n \"userId\": 20484,\n \"userNickName\": \"쿰쿠미\",\n \"startDt\": \"2024-11-01\",\n \"endDt\": \"2024-11-05\",\n \"target\": \"나 쿰쿠미는 매일 영어공부를 하겠습니다.\",\n \"userAddBody\": \"미드를 자막없이 볼 수 있을 때 까지 영어공부를 매일 하려고 한다. 요즘 야근이 잦아서 걱정이긴 하지만 하루에 단 5분이라도 공부하는게 목표다!\"\n }\n}",
"annotations": []
}
}
],
"attachments": [],
"metadata": {}
}
],
"first_id": "msg_968JUZ4Plagwtp1KJbkyvcbe",
"last_id": "msg_649N1OTGvlH9C7sdmJm75beG",
"has_more": false
}사용자의 질문과 AI의 응답이 모두 함께 들어있다. 응답은 사용자의 질문과 AI의 답변이 함께 들어있다. AI의 응답만 처리 하고 싶은 경우라면 실제 코드에서는 role이 assistant인 경우와 함께, 가장 최근 메시지만 확인하는 로직이 필요하다. (배열의 가장 마지막을 가져오면 된다)
나의 실제 예시와, API 문서의 예시코드가 섞여있는 구조로 정리를 했다. 나의 실제 코드는 여러가지 처리를 한게 많아져서 복잡도가 높아진 관계로 오히려 정리하기에는 좋지 않다는 느낌을 받았다. 결론적으로 OpenAI의 Assistants API는 상당한 잠재력을 가지고 있으면서도 구현이 쉬운 AI API이다. 공식 문서나 예시 자료에는 챗봇으로 활용하는 방법을 제시하고 있는데, 챗봇이외에도 자신의 필요에 따라 원하는 동작을 하는 AI 모델을 비교적 손쉽게 만들 수 있는 장점이 있다.
이번 글을 마치며
Assistants API의 경우 꼭 필요한 부분만 정리 해보려고 했는데, 또 너무 내용이 많지는 않은지, 혹은 부족하지 않은지에 대한 저울질에 실패한 느낌이다. 결국은 특정 기술이라기 보다는 API의 사용법에 대한 문제이기도 하고, 개발자가 의도하는 내용에 따라 사용법이 미묘하게 달라질 수 있는 여지가 많아서 명확하게 정리 하기가 힘들었다.
한동안 글이 뜸하긴 했는데, 토이프로젝트 개발 자체에 쓴 시간이 많다기 보다는 학습과 삽질에 시간을 많이 보냈다. 다음글에서는 어느정도 완성된 토이프로젝트를 공개 할 수 있음을 소망하며 이번글을 마치도록 한다.
