✔ 구현해 보기
: 이전에 만들었던 가변 배열 클래스에 iterator 구현하기
(1) 반복자 클래스 생성
-
반복자는 inner class이므로, 배열 클래스 내부에 클래스 만들기
-
T*가 8바이트고 int형 멤버변수가 2개 있으니까 이 클래스는 총 16바이트.
-> 이 때 내부 클래스에도 8바이트짜리 변수가 있다면?
-> 그럼 클래스 객체 하나는 24바이트?? ( X )
👉CArr<T>와iterator<T>는 별개의 클래스다. 반복자 선언이 가변배열 클래스 안에 되어있을 뿐임 -
클래스 템플릿 내부에 구현하는 것이므로 반복자도 템플릿이 된다.
vector<float>::iterator;
vector<short>::iterator;
vector<int>::iterator;-> 따라서 이 셋은 각자 전혀 다른 클래스의 반복자임
-
반복자가 어떤 멤버를 가지고서 어떻게 동작해야 가변배열 안의 데이터를 가리키는 역할을 할 수 있을까?
-> 가변배열의 시작 주소, 인덱스 를 가지고
-> 시작 주소로부터 몇 칸 떨어져 있는지(인덱스) 파악한다. -
생성자/소멸자 생성,
- 가변배열의 begin() 설명
vector<int>::iterator veciter = vecInt.begin();
: 반복자 객체 생성해서 가변배열의 시작주소 할당
-> 가변배열은 자신의 멤버함수begin()을 반복자에게 넘겨준다.
👉begin()의 반환 타입이 iterator라서 반복자 객체veciter가 받을 수 있음
- 따라서 가변배열에
iterator begin();라고 begin 함수를 선언하려는데, iterator 클래스가 더 밑에 있어서 iterator 타입을 아직 모름.
그러면
- 반복자 밑에다 선언해 주거나,
- 위에
class iterator;라고 전방선언을 해준다.
(2) begin 함수
: 가변배열의 첫 번째 데이터를 가리킨다.
1)
template<typename T>
typename CArr<T>::iterator CArr<T>::begin()-> begin()은 가변배열의 함수임
-
정의할 때 타입 앞에
typename붙인 이유
: 반환 타입이 내부 클래스(iterator)일 경우. 이 함수가 특정 타입이라는 걸 알려주기 위해 이 키워드 붙여야 함.-> (
CArr<T>::iterator: 반환 타입)
2)
- 시작을 가리키는 iterator를 만들어서 반환해 준다.
-> 그러면 메인에 있는
CArr<int>::iterator myiter = myvector.begin();
의myiter가 반환값을 받는다.- 따라서 반복자 객체에게 가변 배열의 시작 주소를 넘겨 주고, 인덱스를 0으로 초기화한 뒤 반환한다.
->iterator iter; iter.m_pData = this->m_pData; iter.m_iIdx = 0; return iter;iter.m_pData는 iterator 쪽의 멤버 변수,
this->m_pData는 CArr<T> 쪽의 멤버 변수
- 따라서 반복자 객체에게 가변 배열의 시작 주소를 넘겨 주고, 인덱스를 0으로 초기화한 뒤 반환한다.
- But 아래처럼 반복자의 인자 있는 생성자를 새로 추가하면 위의 초기화 코드 작성할 필요 X
//iterator(CArr* _pArr, T* _pData, int _iIdx)
iterator(T* _pData, int _iIdx)
// m_pArr(_pArr) (3)에서 추가됨
: m_pData(_pData)
m_iIdx(_iIdx)
{
}- 그러면 begin 함수는 반복자만 반환하면 되는데,
어차피 반복자 지역변수를 만든 다음 바로 반환할 거니까, 그냥 변수 없이 아래처럼 임시 객체를 만들어서 그 순간 바로 반환한다.
// return iterator(this, m_pData, 0); (3)에서 수정됨
return iterator(m_pData, 0);(3) 연산자 함수
: 전위/후위 증감 연산자, *, ==, != 함수 구현하기
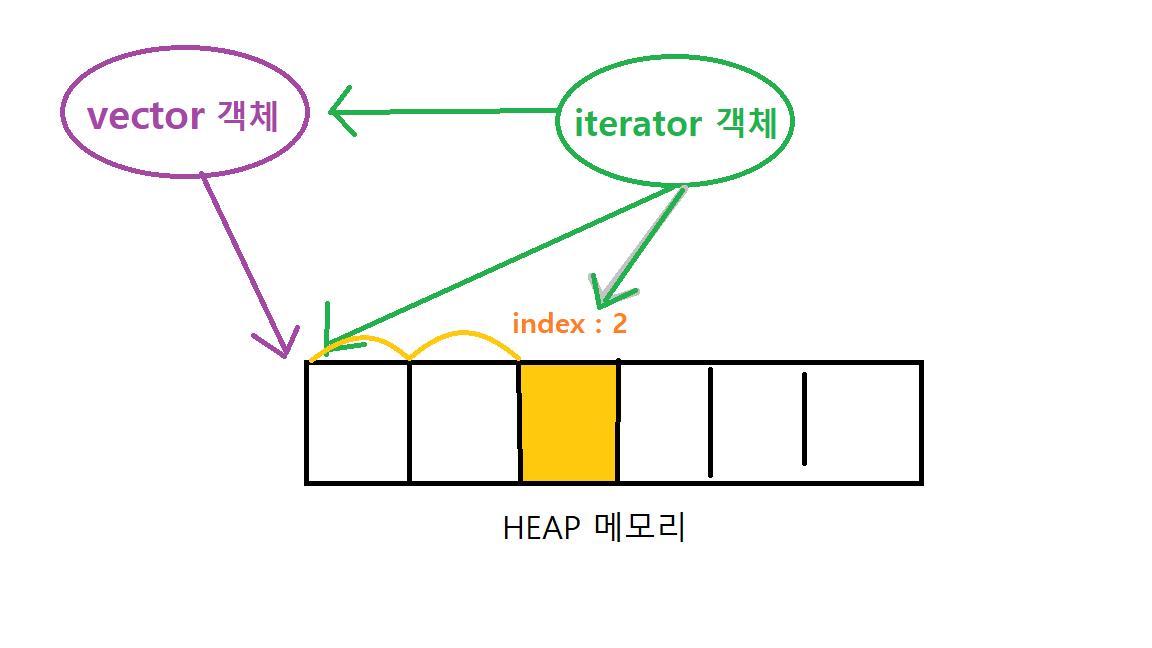
-
반복자가 가변배열의 첫 번째 데이터 주소를 알고 있을 때,
만약 가변배열에 데이터가 꽉 차서 재할당이 일어난다면, 반복자는 새 주소를 가리켜야 한다.
(비어버린 메모리 주소를 계속 가리키게 될 수도 있으므로)
-> 그러려면 반복자는 (배열 크기를 늘린 주체인) 가변배열 객체를 알아야 함
(재할당시 가변배열 객체가 새 메모리 주소, 즉 데이터 주소를 알고 있음)- 💡가변배열은 가리키던 메모리의 주소가 달라지는 것을 문제로 인식한다. 따라서 메모리 주소가 그대로인지 비교할 수 있도록 데이터 시작 주소를 알고 있다.
- 💡가변배열은 가리키던 메모리의 주소가 달라지는 것을 문제로 인식한다. 따라서 메모리 주소가 그대로인지 비교할 수 있도록 데이터 시작 주소를 알고 있다.
-
반복자의 멤버 변수
private:
CArr* m_pArr; // iterator가 가리킬 데이터를 관리하는 가변배열
T* m_pData; // 데이터들의 시작 주소
int m_iIdx; // 가리키는 데이터의 인덱스-> 데이터를 관리하는 가변배열 객체 m_pArr를 알아야 한다.
-> 반복자가 클래스 템플릿이므로, 가변배열의 데이터 저장 단위인 T 포인터 타입의 데이터 시작 주소 m_pData를 알아야 한다.
-> 데이터 시작 주소로부터 몇 칸 떨어져 있는지 알기 위해 인덱스 m_iIdx를 알아야 한다.
검필: CArr<T>* 이 아니라
CArr* 라고 멤버변수 타입을 써뒀는데
둘이 똑같아서 굳이 안 적고 생략한건가?
내부클래스니까 상위클래스 타입네임은 안써도 되는거?
❗ 반복자가 단순히 데이터 시작 주소와 인덱스만 알고 있으면, 재할당 전/후 데이터 주소가 다른지 알 수 없음. 반복자는 생성될 때 초기화되니까 주소가 바뀌어도 알지 못하고, 계속 예전 주소로 접근하게 될 것임..
- 반복자가 가변배열 객체를 알고 있으므로, 결국 현재 데이터의 시작 주소도 알게 된다.
(가변배열이 재할당되지 않아 주소가 그대로라면, 가변배열이 관리하는 멤버m_pData와 반복자의m_pData가 동일한 주소를 가질 것임)
- 반복자의 멤버 변수에
CArr*타입이 추가됐으므로 생성자를 수정해 준다.
iterator(CArr* _pArr, T* _pData, int _iIdx)
: m_pArr(_pArr)
, m_pData(_pData)
, m_iIdx(_iIdx)
{
}- begin()이 반환할 임시 클래스 객체의 초기화 값도 수정해 준다.
template<typename T>
typename CArr<T>::iterator CArr<T>::begin()
{
// 시작을 가리키는 iterator 를 만들어서 반환해줌
return iterator(this, m_pData, 0);
}-> begin()이 CArr<T>의 멤버함수이므로 this를 넣어줘야 한다.
-> 이 때 this 는 가변배열의 주소를 의미한다.
- 내부 클래스의 특징
-> 클래스 안에 선언된 클래스를 지칭하려면, 외부 클래스부터 범위 지정 연산자로 접근해서 지칭해줘야 함.
-> 외부 클래스의 private 멤버에 접근할 수 있다.
- ❗ begin() 의 허점
-> 데이터가 하나도 없을 때는 begin이 곧 end이다.- 따라서 데이터가 하나도 없는 경우를 예외처리
-> (임의로) 데이터가 0개일 때의 인덱스는 -1이라고 정해 두고 예외처리함
- 따라서 데이터가 하나도 없는 경우를 예외처리
template<typename T>
typename CArr<T>::iterator CArr<T>::begin()
{
// 시작을 가리키는 iterator 를 만들어서 반환해줌
if(0 == m_iCount)
return iterator(this, m_pData, -1); // 데이터가 없는 경우. begin() == end()
else
return iterator(this, m_pData, 0);
}- end 함수 만들기
// CArr<T> 에 함수 선언
iterator end();// 클래스 바깥에 함수 정의
template<typename T>
typename CArr<T>::iterator CArr<T>::end()
{
// 끝의 다음을 가리키는 iterator 를 만들어서 반환해줌
return iterator(this, m_pData, -1);
}
역참조 연산자(*)
: 반복자가 현재 가리키는 주소의 값을 반환한다.
- 반환타입이 레퍼런스가 아니면 역참조해온 뒤 값을 수정할 수가 없다.
CArr<int>::iterator myiter = myvector.begin();
int ivalue = *myiter;
*myiter = 100; // Error- 예외처리 )
- 반복자가 가리키는 데이터 주소와, 가변배열이 가리키는 데이터 주소가 같은지 확인한다.
- 반복자가 end일 경우 가리키는 데이터가 없어 역참조할 수 없으므로, 인덱스가 -1인지 확인한다.
public:
T& operator * ()
{
// iterator가 알고 있는 주소와, 가변배열이 알고 있는 주소가 달라진 경우(공간 확장으로 주소가 달라진 경우)
// end iterator인 경우
if (m_pArr->m_pData != m_pData || -1 == m_iIdx)
{
assert(nullptr);
}
return m_pData[m_iIdx];
}- 마지막 데이터 가리키는 반복자에 ++하면 end 가 되겠지만,
end에 ++ 하거나
begin에서 -- 하는 건 ❗에러❗
//예시
veciter = vecInt.begin();
--veciter; //Error- 증감 연산자 함수의 반환타입?
int k = 0;
++(++k);- k를 1 증가시키고 : ++(++k)
- 다시 k를 1 증가시킨다 : ++(k)
👉 그러려면 (증가한 후의) 자기 자신을 반환해야 함.
연산이 끝난 후, 연산자를 호출시킨 객체가 다시 반환되어야 그 객체를 통해 연속해서 연산자 함수를 호출시킬 수 있게 된다.
예시뭐지;
- 반복자가 가변배열의 특정 데이터를 가리키고 있을 때, 반복자에 ++, -- 연산을 하면 가리키는 대상을 뒤or앞 으로 인덱스 한 칸씩 옮길 수 있어야 한다.
증가 연산자(++)
-
전위 )
: 반복자가 현재 가리키는 대상의 다음 데이터를 가리키도록 한다.
👉 인덱스 1 증가- 예외처리 )
- 반복자가 마지막 데이터_를 가리키고 있는 경우
- 반복자가 end_인 경우
- 반복자가 알고 있는 데이터 주소와 가변배열이 알고 있는 데이터 주소가 다른 경우
// ++ 전위
iterator& operator ++()
{
// 2. end iterator인 경우
// 3. iterator가 알고 있는 주소와, 가변배열이 알고 있는 주소가 달라진 경우 (공간 확장으로 주소가 달라진 경우)
if (m_pArr->m_pData != m_pData || -1 == m_iIdx)
{
assert(nullptr);
}
// 1. iterator가 마지막 데이터를 가리키고 있는 경우
// --> end iterator가 된다.
if (m_pArr->size() - 1 == m_iIdx)
{
m_iIdx = -1;
}
else
{
++m_iIdx;
}
return *this;
}- 후위 )
: 반복자가 현재 가리키는 대상의 다음 데이터를 가리키도록 한다.
👉 인덱스 1 증가 (실제 결과는 전위 연산과 같다.)
앞서 만든 전위 연산자를 그대로 활용하여 구현한다.
- 전/후위 연산자는 연산자 함수 자체가 다르다.
일반적으로 기본 자료형에 대한 전/후위 연산자의 동작 방식은
연산이 수행되는 시점에 차이가 있다.
후위는 가장 마지막에 수행된다.
- 증가 연산자는 기본 연산자(사칙연산)가 아닌, 오퍼레이터 함수이기 때문에 멤버함수의 규칙을 따른다.
그래서 ++ 붙이는 위치가 달라진다고(전/후위) 호출 시점이 달라지지 않는다.
👉 후위 연산자는 전위와 다른 별개의 함수를 만들어야 한다.
- 선언에 인자로 자료형 int를 적어주는데 이건 아무 의미 X, 변수명도 적을 필요 없음. 그냥 int 타입 하나 받을 거라고 선언해준 것
👉 적어둔int를 기반으로 컴파일러가opterator ++가 후위 버전 ++이라고 인식하게 됨.
-> 즉시 호출되는 건 멤버함수 규칙 그대로지만, 가장 마지막에 호출이 되는 진짜 후위 연산자인 것처럼 페이크를 줘야 함.
- 후위 연산자는 일반 멤버함수랑 똑같이 곧바로 호출되므로 반환타입이 중요함.
전위 연산자처럼 자기 자신을 그대로 반환시켜 버리면, 절대 후위 연산자처럼 동작(맨 마지막에 호출)하지 않음
👉 레퍼런스가 아니라 복사본을 줘야 한다.
(반환한 뒤 복사본은 사라진다.)
- 반복자 지역변수를 만들고 후위 ++ 연산자를 호출한 객체(자기 자신)를 넣어서 반환한다.
그리고 후위 ++ 연산자가 동작을 마친 뒤 리턴된 객체를 확인해 보면, 원래 가리키던 대상이 다음 요소로 증가되어 있지 않다.
-> 전위 연산자를 활용해서, 후위 연산자를 호출시킨 객체가 다음 요소를 가리키게 한다.
-> But 반환은 증가된 객체가 아닌, 증가되기 전 객체의 복사본을 반환해야 한다.
(원본은 이미 증가됐고, 반환만 증가하기 전의 복사본으로 함)
- 전/후위 연산자는 연산자 함수 자체가 다르다.
// ++ 후위
iterator operator ++(int)
{
iterator copy_iter = *this;
// 후위를 호출시킨 객체는 다음 요소를 가리키게 됨
++(*this);
// 전위로 증가시키기 전 상태의 복사본을 반환
return copy_iter();
}💡 팁
- 전위/후위 둘 다 상관없을 때라면 웬만하면 전위 연산자를 쓰는 것이 좋다.
-> 이유 : 비용이 적게 든다.
(후위는 쓸데없는 객체 생성/삭제 비용이 든다.)- 원래라면 자동 구현될 생성자를 사용자가 1개라도 직접 구현하면, 생성자 오버로딩이 되어 생성자가 생겨난다. 그럼 컴파일러는 기본 생성자를 제공하지 않는다.
👉 이런 경우 기본 생성자를 직접 만들어줘야 함
(Why? 사용자가 기본 생성자를 사용하고 싶지 않을 수도 있는데, 컴파일러가 무조건 자동 생성해 주면 사용자의 의도와 다르게 동작하는 문제가 생긴다.)
- 원래라면 자동 구현될 생성자를 사용자가 1개라도 직접 구현하면, 생성자 오버로딩이 되어 생성자가 생겨난다. 그럼 컴파일러는 기본 생성자를 제공하지 않는다.
- 후위 연산자 중요 개념
: 클래스에는 겉으로 보이지는 않지만 자동으로 생성되는 생성자/소멸자와 대입 연산자 함수가 있었다.
생성자는 여러 종류로 오버로딩이 가능했는데. 그 중에서도 복사 생성자는 복사의 원형이 되는 것을 가져와서 그 값을 자신의 초기값으로 사용한다.-
사용자가 직접 만들지 않아도 자동으로 생성된다.
// 예시 class CTest { private: int m_i; public: CTest(const CTest& _other) : m_i(_other.m_i) { } };-> 생성자 하나를 만들었으니 기본 생성자도 구현해 줘야 한다.
-
이렇게 두 번 나눠서 작업하지 말고
CTest t1, t1.m_i = 100; CTest t2; t2 = t1; -
객체를 생성함과 동시에 대입을 받게 되면 컴파일러가 그 동작을 복사 생성자로 바꿔준다.
-
복사 생성자 호출해서 객체 생성/대입을 동시에 해버리기
CTest t1, t1.m_i = 100; CTest t2(t1); -
대입 연산자 호출하는 것처럼 보이지만, t3을 새롭게 생성하면서 t1을 대입받고 있다.
=> 그럼 복사 생성자임 ㅇㅇCTest t3 = t1;-> 지금 객체의 생성과 대입을 동시에 하고 있는데?
=> 그냥 복사 생성사 호출해서 한 번에 처리해버리기.--> 그럼 아까 구현한 후위 연산자 함수의
iterator copy_iter = this도 복사 생성자를 호출하는 것이다.
-
감소 연산자 (--) 직접 구현
-
전위 )
: 반복자가 현재 가리키는 대상의 이전 데이터를 가리키도록 한다.
👉 인덱스 1 감소 -
예외처리 )
- 반복자가 첫 번째 데이터를 가리키고 있는 경우
- 반복자가 알고 있는 데이터 주소와 가변배열이 알고 있는 데이터 주소가 다른 경우
- 데이터가 0개인 경우
- 반복자가 end인 경우
// -- 전위
iterator& operator --()
{
// 1. iterator가 첫 번째 데이터를 가리키고 있는 경우
// 2. iterator가 알고 있는 주소와, 가변배열이 알고 있는 주소가 달라진 경우
// 3. 데이터가 0개인 경우
if (m_pArr->m_pData != m_pData || 0 == m_iIdx || 0 == m_pArr->size() )
{
assert(nullptr);
}
// 4. end iterator인 경우
// --> 마지막 데이터를 가리키게 된다.
if ( -1 == m_iIdx )
{
m_iIdx = m_pArr->size() - 1;
}
else
{
--m_iIdx;
}
return *this;
} - 후위 )
: 반복자가 현재 가리키는 대상의 이전 데이터를 가리키도록 한다.
👉 인덱스 1 감소 (실제 결과는 전위 연산과 같다.)
앞서 만든 전위 연산자를 그대로 활용하여 구현한다.
- 반복자 지역변수를 만들어
후위 -- 연산자를 호출한 객체를 넣어준다.후위 -- 연산자를 호출한 객체(자기 자신)을 전위 연산자를 활용하여 감소시킨다.- 아까 만든 복사본(반복자 지역변수)을 반환한다.
-> 원본은 이미 감소되었고, 반환만 감소 전의 복사본으로 함
// -- 후위
iterator operator --(int)
{
iterator copy_iter = *this;
// 후위를 호출시킨 객체는 이전 요소를 가리키게 됨
--(*this);
// 전위로 감소시키기 전 상태의 복사본을 반환
return copy_iter();
}비교 연산자
-
참/거짓 결과를 반환하므로 bool 타입.
-
반복자를 인자로 받아 비교하는데, 이 때 직접 복사하지 않고 참조하여 비용을 절감한다. 또한 값을 수정하지 않고 비교만 하면 되기 때문에 const 참조로 받아온다.
this: 이 멤버함수를 호출시킨 객체_otheriter:this와 비교될 객체
-
뭐가 같아야 같은 반복자라고 판단할 수 있을까?
: 가리키는 요소가 같을 때
-> 데이터 시작 주소(m_pData)와 데이터의 인덱스(m_iIdx)가 같을 때
-
== 연산자
bool operator == (const iterator& _otheriter)
{
if (m_pData == _otheriter.m_pData && m_iIdx == _otheriter.m_iItdx)
{
return true;
}
return false;
}- != 연산자
: 위에서 구현한== 연산자를 호출하여 더욱 간단해졌다.
bool operator == (const iterator& _otheriter)
{
return !(*this == _otheriter);
} 👉 자기 자신과 인자끼리 ==로 비교한 값을 반대로 반환한다.
[참고]
https://youtu.be/Z5p4UmjsZlY (2)
https://youtu.be/pv7cOxy_x7k (3)
https://youtu.be/s3UfCS4QAcI (4)
https://youtu.be/I8-wha1B0NE (5)
