
✔문자
- 메모리 영역
- 스택
- 힙
- 데이터
- ROM (CODE/DATA)
- char 자료형
타입 : 정수형
크기 : 1btye
-> char 값을 아스키 코드로 해석하여 문자를 표현할 수 있다,
//ASCII 코드 표에 따르면 65는 A를 의미한다.
char a = 65;
printf("%c\n", a);
a = 'A';
printf("%c", a);[출력]
A
A-> 데이터 값은 65로 그대로지만, 문자로 해석하겠다고 하는 순간 해당 데이터 값에 대응하는 문자로 표현된다.
✔문자열
"459" => [52][53][57][0]
- 메모리의 다음 칸에도 연속해서 데이터가 채워져 있을텐데..문자열의 끝이 어딘지 어떻게 알지?
👉 맨 끝에 0(NULL) 넣어주기
"4 59" => [52][32][53][57][0]
-
아스키 코드에서 공백 문자(space)는 데이터가 없는 게 아니라 10진수로 32라는 숫자가 들어있는 것이다.
-
wchar_t 자료형
타입 : 문자형
크기 : 2byte
-> 1byte로 표현할 수 없는 문자를 저장할 때 사용
char c = 'a';
wchar_t wc = L'a'; // 'L' 붙이기-> 2바이트 단위로 쓰겠다는 걸 알리기 위해 문자 앞에 'L'을 붙임
- 배열도 마찬가지
char szChar[10] = "abcdef";
wchar_t szWChar[10] = L"abcdef";
wchar_t szWChar[6] = L"abcdef"; //Error
short arrShort[10] = L"abcdef"; //Error
//abcdef와 같음, 초기화되지 않은 배열 요소는 0으로 초기화되기 때문에
//0은 굳이 넣어주지 않아도 됨
short arrShort[10] = { 97, 98, 99, 100, 101, 102, };wchar_t szWChar[6] = L"abcdef";
-> 문자열이 끝났음을 알려주는 NULL 문자가 들어갈 칸도 필요함.
따라서 데이터가 6개라면 적어도 배열 사이즈 7은 필요(문자 6칸+널 1칸)
자료형 변수명[] = L"문자열"
-> 이런 초기화법은 문자 전용 자료형에만 사용 가능
const char*
const wchar_t* pChar = L"abcdef";- 문자열은 문자열의 시작 주소를 반환함.
- L이 붙었기 때문에 각 문자 데이터들은 2byte씩 차지함.
따라서 2byte 자료형 포인터로 가리켜야 함.
wchar_t szWChar[10]= = L"abcdef";
const wchar_t* pChar = L"abcdef";- 둘의 차이
szWChar: 문자열에 있는 데이터 abcdef를 그대로 szWChar 배열 메모리로 옮김
pChar: 문자열에 있는 데이터 abcdef를( 문자열의 시작 주소를) 직접 가리킴
szWChar[1] = 'z';-> 배열에 들어 있는 b가 z로 바뀜
//둘 다 Error
pChar[1] = 'z';
*(pChar + 1) = 'z';-> 둘은 같은 코드
- 위에서 작성한
const wchar_t* pChar = L"abcdef";는 프로그램이 실행시킬 명령어이기 때문에 ROM(Read Only Memory)에 저장된다.
->pChar[1] = 'z';는 그 코드를 수정하도록 시킨 것인데. ROM(Read Only Memory)에 저장된 코드는 프로그램 실행 중에 절대 수정될 수 없다.
👉 위의 코드 두 줄 모두 에러 발생
👉 따라서 문자열 반환 타입은 문자열의 시작 주소는 받아오되, 주소로 접근해 수정할 수 없도록 무조건 const 포인터 타입만 사용할 수 있다.
멀티바이트
문자열 앞에 L이 붙지 않았다고 무조건 1byte로 표현되는 건 아니다.
- 멀티바이트 표현 방식)
: 문자에 따라서 1byte, 2byte 등의 가변 길이로 대응하는 것- 그래서 문자열에 1byte와 2byte 문자가 섞여 들어갈 수도 있음.
char szTest[10] = "abc한글"
[0] -> a, [1] -> b, [2] -> c, [3][4] -> 한, [5][6] -> 글-> abc는 각각 1byte, 한글은 각각 2byte
- 멀티바이트 방식의 문제점)
- 이제 MS 윈도우에서만 쓰임. 복잡해서 잘 쓰이지 않는다.
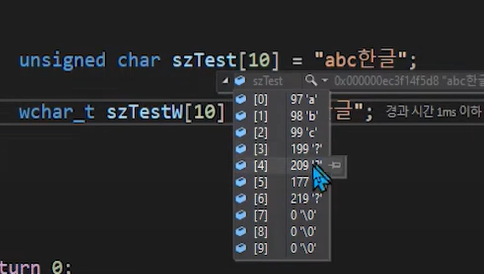
-> 2byte 기준으로 abc한글을 해석하면 한이 5만이 넘는 숫자를 의미함.
-> 1byte씩 끊어서 보면
한 : sztest[3], sztext[4] -> 199, 209
글 : sztest[3], sztext[4] -> 177, 219
-> 한과 글이 2byte짜리 문자라는 걸 알려야 시작 주소로부터 문자를 읽을 때, 어디까지 읽어야 할지를 알 수 있음
209 => 1101 0001
219 => 1101 1011
110 : 문자 길이가 2개짜리라는 걸 의미함
👉 그냥.. 모든 문자를 2바이트로 표현하는 와이드바이트 방식의 유니코드 사용하는 게 유리함.
와이드바이트
wchar_t 자료형으로 표현한다.
- 무조건 2byte 단위만 사용하기 때문에 위에서 언급한 멀티바이트의 문제를 고려할 필요가 없다.
[참고]
https://youtu.be/6T2qV8GPhN8
https://youtu.be/9XOCeYpv8ro
https://youtu.be/bozefSvT6SI
https://youtu.be/VvW00Gr1-PU
https://youtu.be/hfUxtFKhOuE
