
CS231n 10강

one to one
지금까지 우리는 입력 1개 -> 출력 1개의 구조를 배웠었다.
일반적으로 fixed size의 이미지가 input으로 들어가면 hidden layer를 거쳐서 fixed size를 가지는 클래스의 스코어가 output으로 나오는...
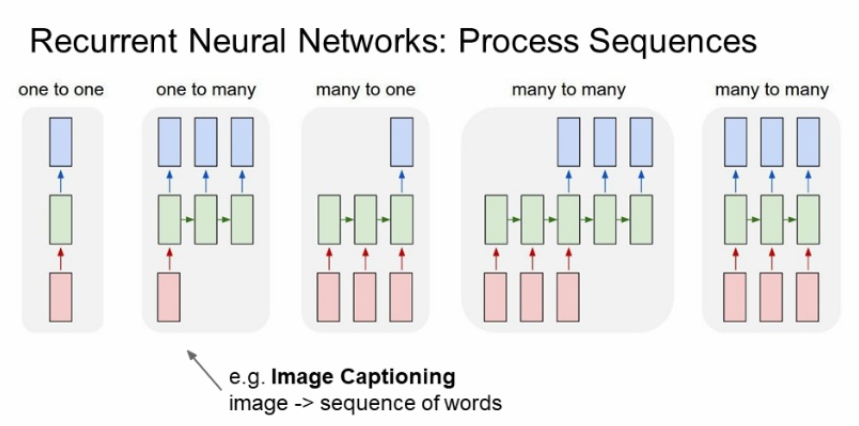
그치만 입력값과 출력값이 많을 수도 있다.
one to many는 이미지를 주면 그에 맞는 시퀀스 문장이 나오는 image cationing에 많이 쓰인다.
many to one은 감정분석, 뉴스 카테고리 분석 등 sentiment classification에 많이 쓰인다.
many to many는 machine translation, video classification on frame level에 많이 쓰인다.
위에서 말한 데이터들은 전부 가변길이를 가지고 있다. 가변길이를 가진 데이터들은 RNN이 잘 처리해준다.

one to one 처럼 고정길이를 가진 데이터에도 RNN은 유용하다.
fixed input의 이미지를 sequential하게 접근 하여 숫자가 몇인지 최종적으로 판단하였다.

이것은 fixed out에 대해 sequential 하게 처리한 생성 모델의 예이다.
이제 RNN에 대해서 자세히 살펴보자.
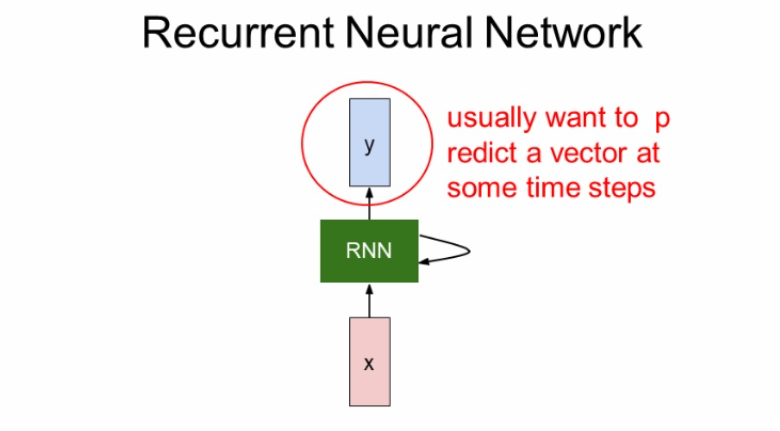
입력 x가 RNN 내부의 hidden state로 들어간다.
hidden state는 입력값이 들어올때마다 update된다.
그러고 출력을 해야 할 경우가 있으면 y로 출력을 내보낸다.
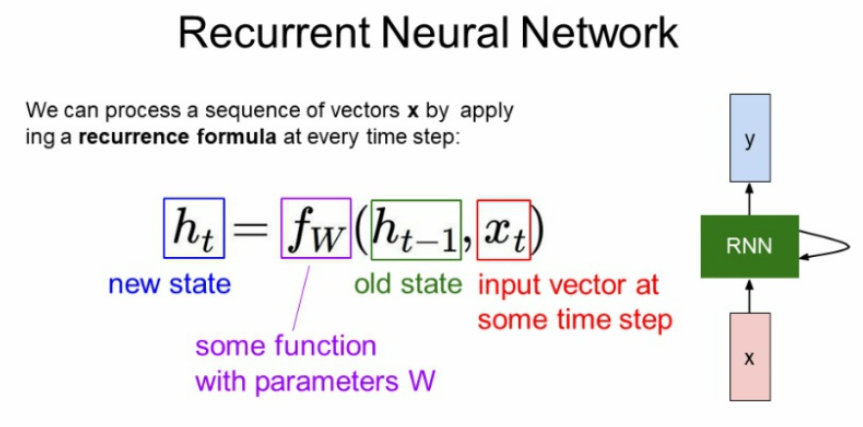
RNN을 수식적으로 표현한 것이다.
새로운 state Ht는 기존 state인 Ht-1과 현재 들어오는 Xt에 영향을 받는다. 그렇게function을 거친 Ht가 출력되면 그 다음 Ht에 영향을 미치고 ... 이런식으로 과거의 데이터가 미래에 영향을 주는 구조를 가진다.
※주의※
파라미터 w는 매 step마다 동일한 w를 쓰고, function도 마찬가지임!!

제일 기본적인 vanilla RNN을 살펴보자.
W의 종류가 세가지 있다.
hidden에서 오는 Whh
x에서 RNN으로 들어오는 Wxh
RNN cell에서 y로 넘어가는 Wyh
아까도 말했듯이 Whh,Wxh,Wyh는 각각 값이 달라도 자신의 영역에선 same한 것을 사용한다.
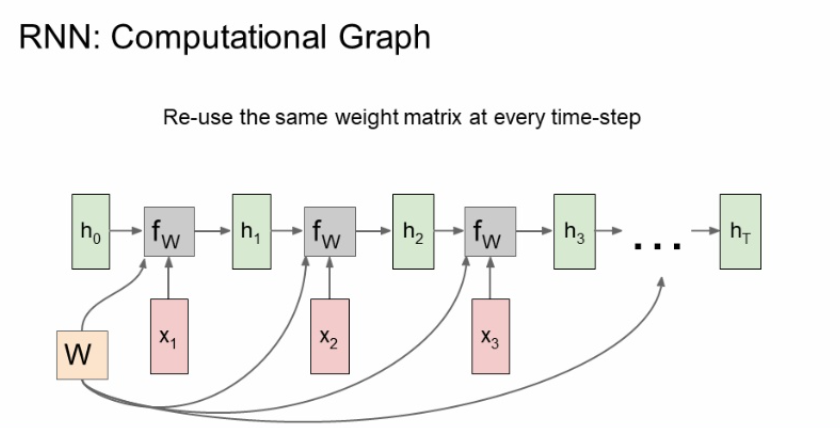
RNN을 그래프로 표현한 것이다.
입력값 X가 계속해서 들어오면 H가 이어지고 H와 fw가 이어져서 연속적인 데이터를 처리할 수 있다. 이때, H와 X는 계속해서 달라지지만 가중치 W는 동일하다는 점 주의하자.
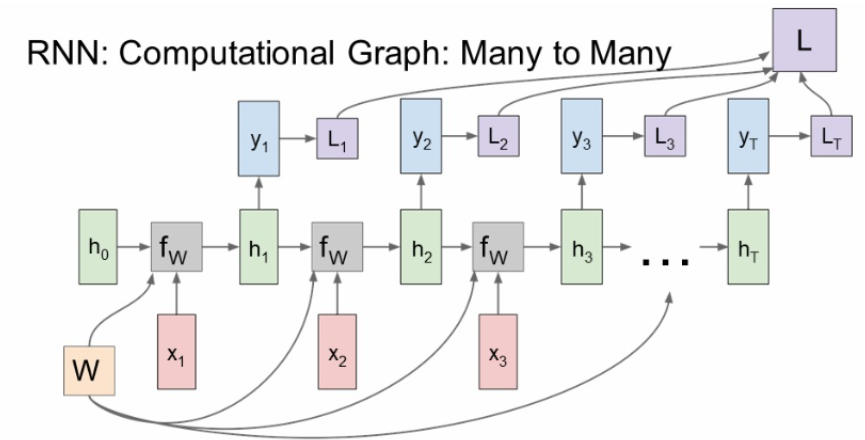
<many to many>
각 출력값마다 나오는 loss 의 총합이 최종 loss가 된다.
backpropagation의 과정을 생각해보자.
모델을 학습시키기위해 dl/dw를 구해야한다.
step마다 loss를 가중치 w에 대해서 local gradient를 구한 뒤 전부 더해준다.
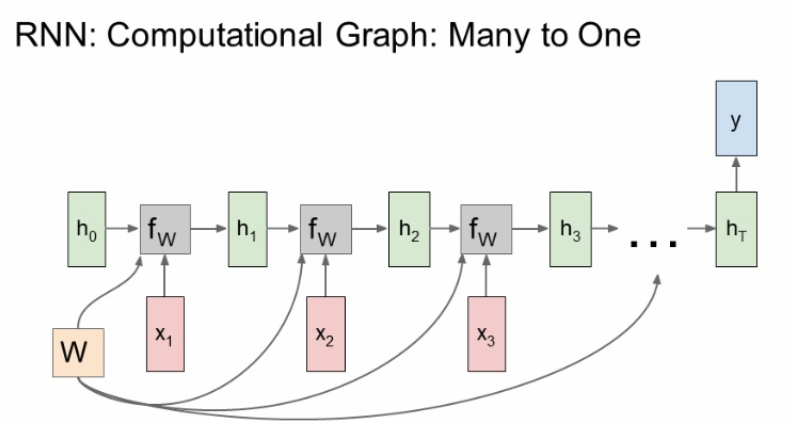
<many to one>
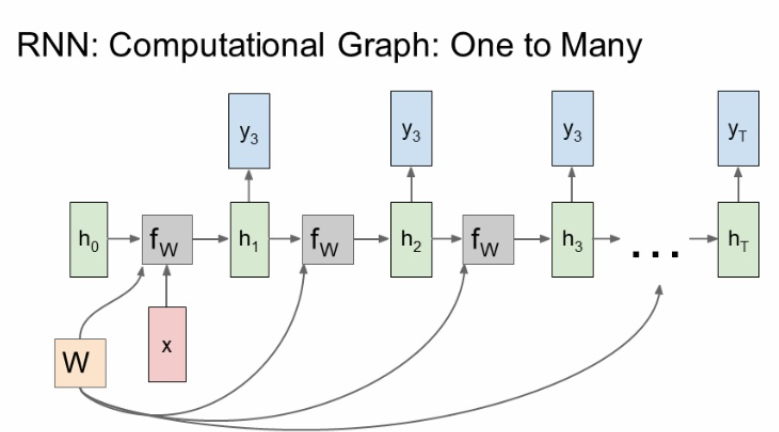
<one to many>
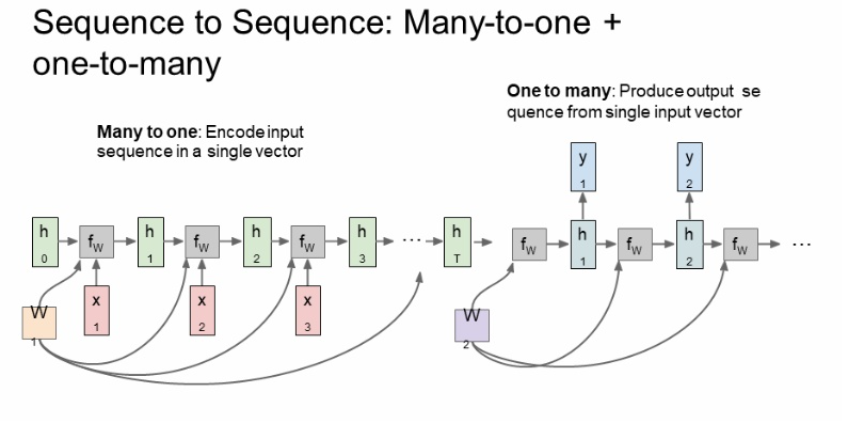
<sequence to sequence>
이는 many to one 과 one to many 의 결합으로 생각하면 된다. encoder로 가변 입력을 받고 hidden state를 통해 전체 sentence를 요약한다. 그리고 decoder를 통해 가변 출력을 해준다.
번역기에서 사용가능하다.
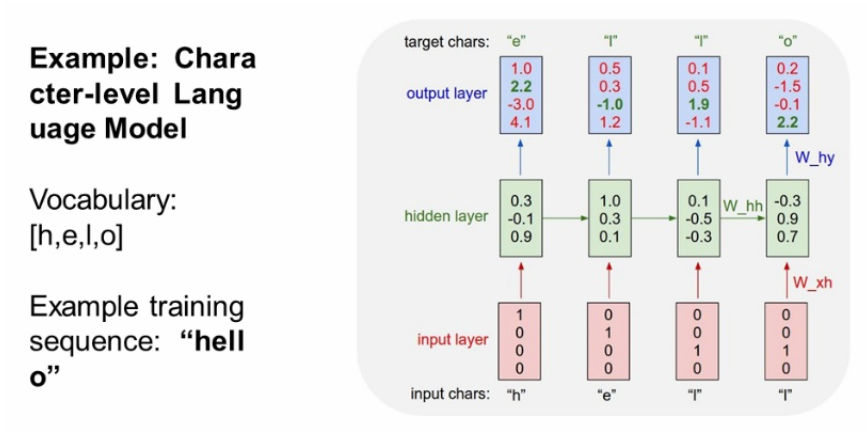
hello라는 예시를 보자.
vocab =[h,e,l,o]에 대해서 원-핫 인코딩을 해주어 input을 넣은 것을 확인할 수 있다.
input으로 h,e,l,l 순으로 들어가면 output으로는 e,l,l,o 가 나오면 굿!!
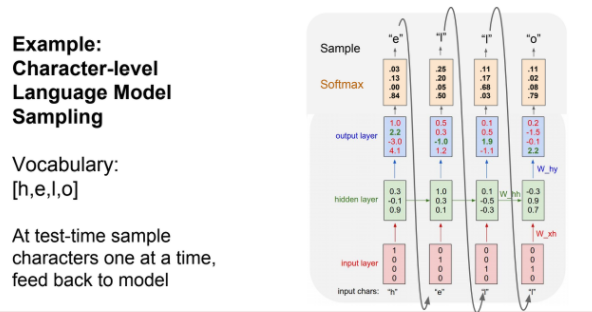
그치만 결과를 보면 o,o,l,o 값들이 나올 확률이 젤 높ㄷr...
하지만 output으로 e,l,l,o가 나온 이유는 운좋게 나왔다고 보면 된당( 확률이 높다고 무조건 그게 나오는건 아니잖아요?)
실제로는 확률분포를 쓰거나 스코어가 높은 것을 쓰거나 골라서 사용한다. 스코어가 높은 것을 썼다면 우리가 원하는 결과를 얻지 못하였을 것이다. 확률분포를 쓰면 모델에서 다양성을 얻을 수 있다고 한다.
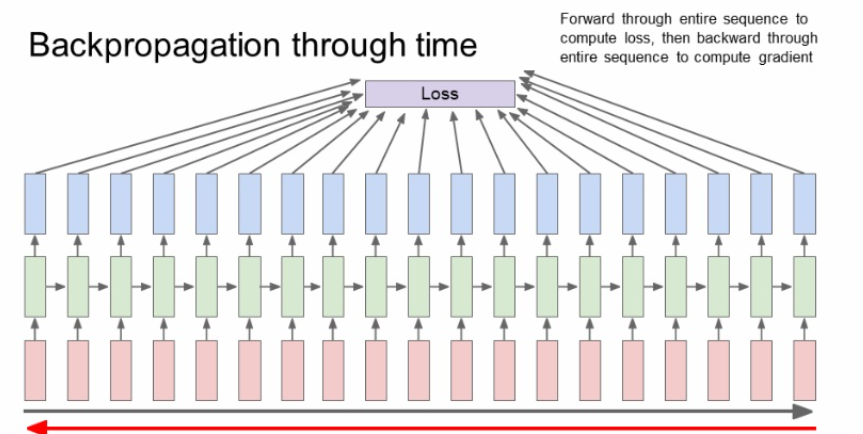
입력값들이 전부 입력되고 나서야 최종 loss를 얻고 그제서야 backpropagation을 할 수 있다. 입력 시퀀스가 길면 back prop를 하기에는 너무 비효율적이다.
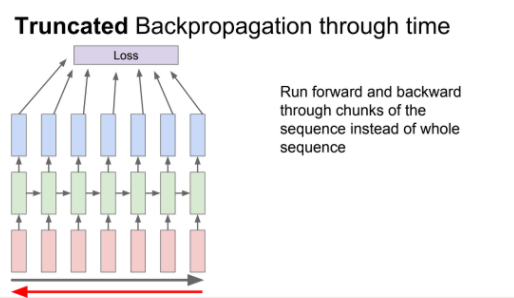
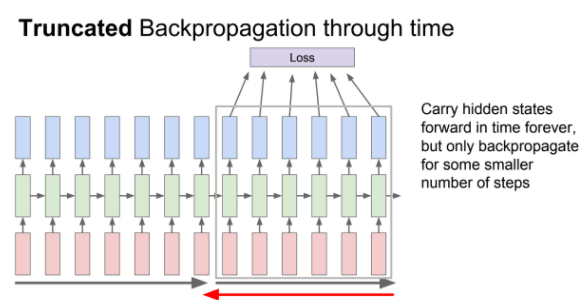
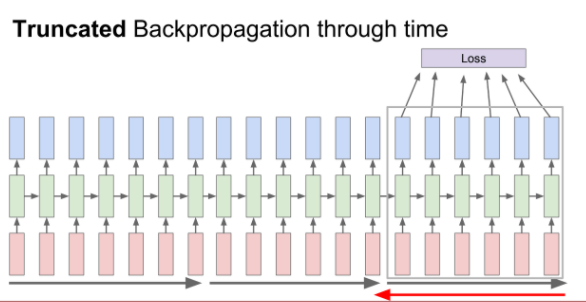
그래서 truncated backpropagation을 사용한다.(mini batch와 비슷한 개념)
train time에서 한 step을 일정 단위로 잘라 일정부분만큼 forward하고 loss 계산하고 gradient를 통해 update를 해나가는 과정을 반복한다.

셰익스피어를 입력으로 훈련시켰을 때

수학책을 입력으로 훈련시켰을 때

리눅스를 입력으로 훈련시켰을 때
모두 그럴싸하게 출력을 해낸것을 볼 수 있다 ㅎㅎ
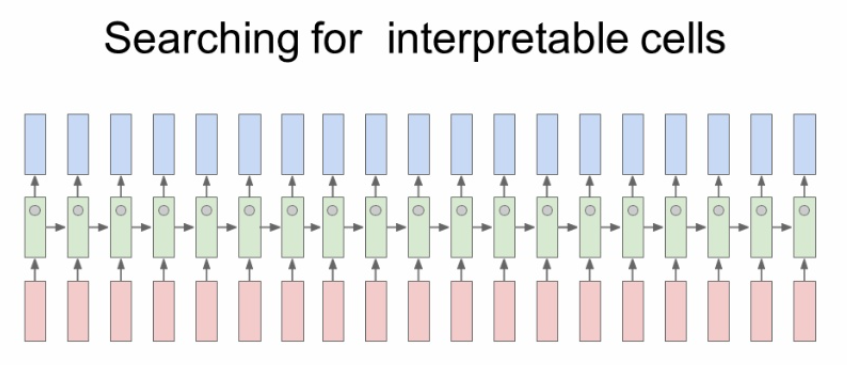
RNN에는 hidden vector가 있고 이 벡터는 계속 업데이트 된다. 이 벡터를 추측한 카파시를 살펴보자.

아무런 의미없는 패턴도 있지만

" "를 기준으로 패턴을 인식하는 경우
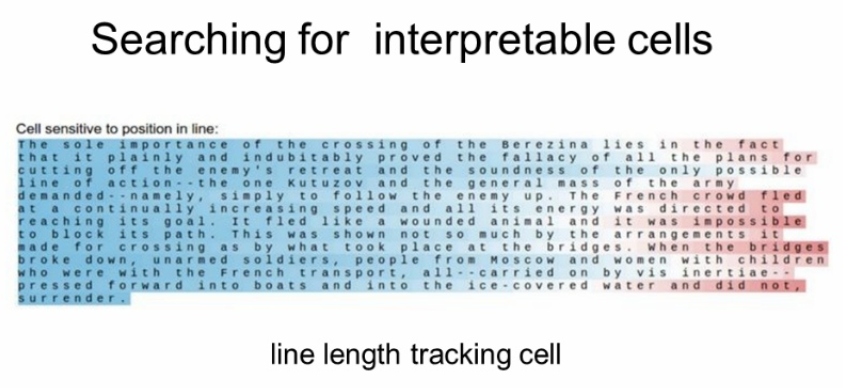
문장의 길이에 따라 패턴을 인식하는 경우

주석문에서 패턴을 인식하는 경우 등등 cell의 활동을 볼 수 있다.
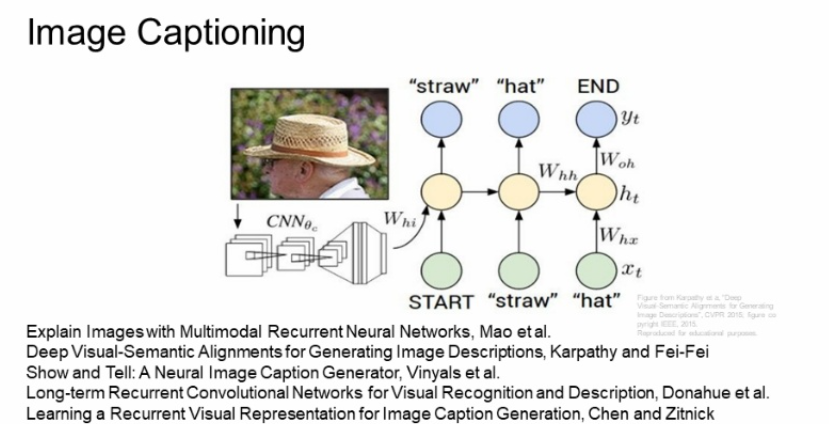
image cationing은 CNN과 RNN을 합친 구조이다.
입력으로 이미지를 받기위해 CNN이 있고, 이미지 정보가 들어있는 벡터를 출력하여 RNN의 초기 step으로 들어가 RNN이 문장을 만들어낸다.
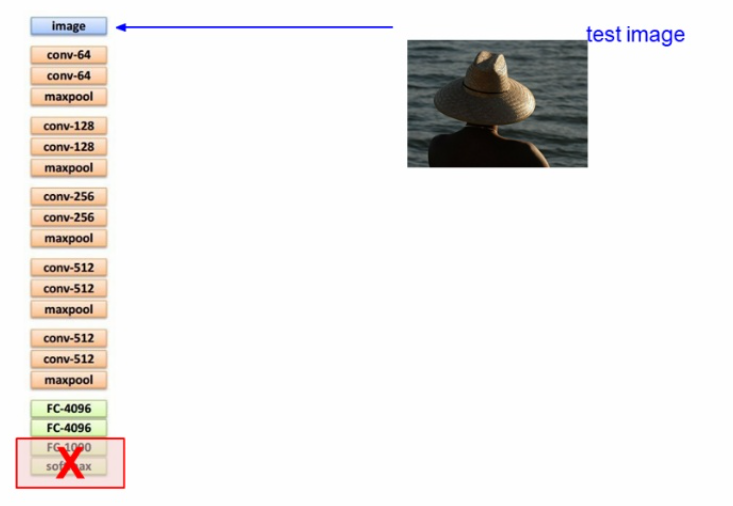
테스트할 이미지를 CNN에 넣는다.
이미지에 대한 스코어,확률을 위한 마지막단은 사용하지않고 FC-4096 까지만 사용하여 전체 이미지 정보를 요약한다.
참고로 이 구조는 VGG Net 이라고 한다.
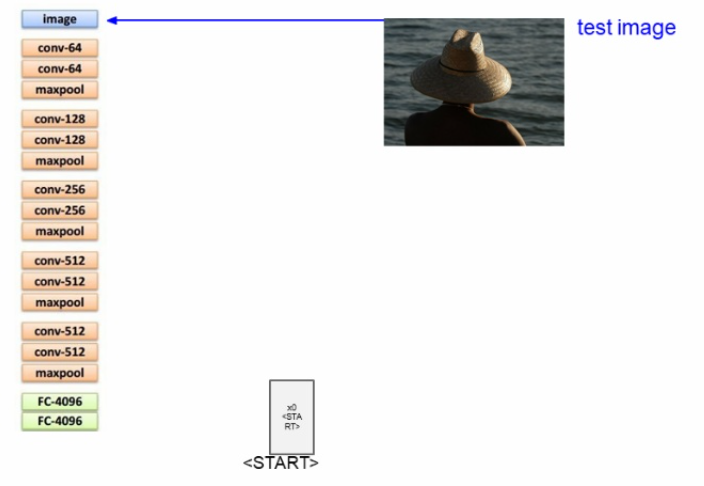
일단은, <start>라는 벡터를 꽂아주어 RNN이 시작된다는 것을 알려준다.
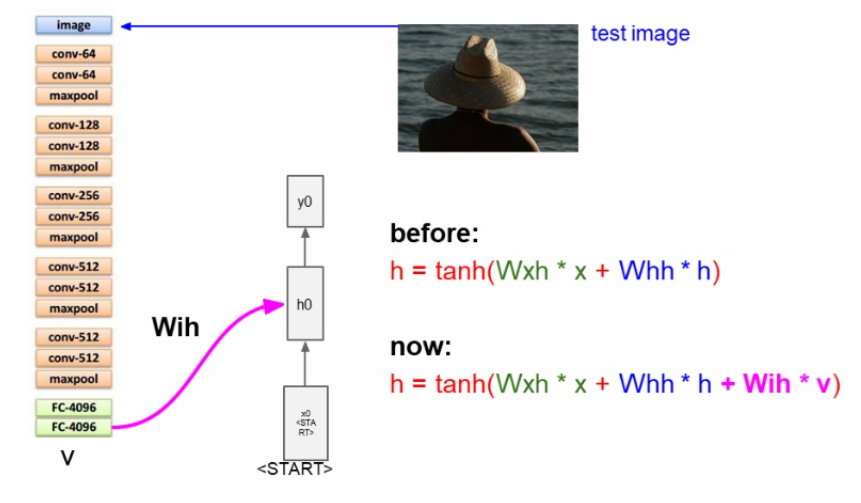
image captioning에서는 Wih * v가 추가적으로 더해지게 된다. Wih는 이미지에서 히든으로 들어가는 가중치이다.
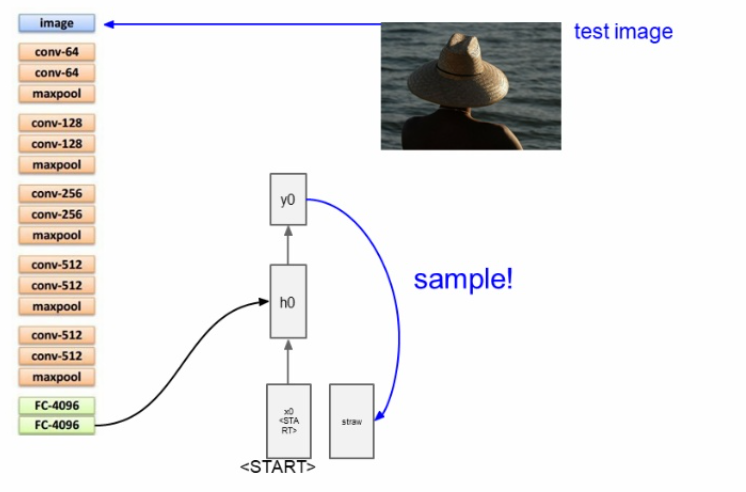
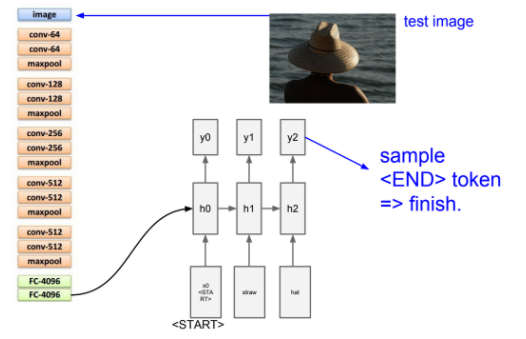
이런식으로 sample값으로 단어가 나오고, 그것이 또 입력값으로 들어가면서 최종 <end> 토큰이 나오게 된다.

image captioning은 supervised learning으로 모델을 학습시키기 위해서는 natural language caption이 있는 이미지를 가지고 있어야한다. 대표적으로 마이크로소프트 coco 데이터셋이 있다.
이걸로 훈련시켰더니 그럴듯한 결과를 낸다.

그치만 훈련이 완벽하게 다 잘되는 것도 아니다!!
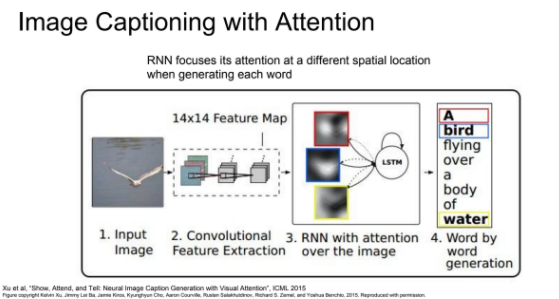
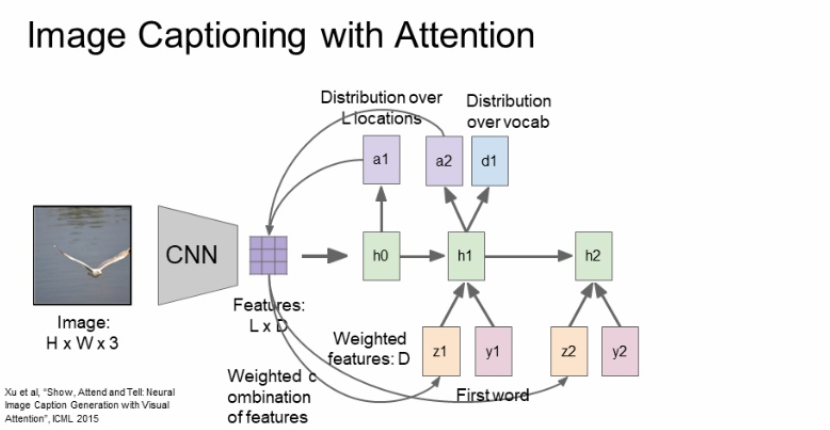
이미지의 다양한 부분에 attention해서 caption을 생성하는 image cationing with attention을 보자. 기본적으로 RNN은 이미지를 전체적으로 한번보고 끝나는 반면 attention은 이미지의 여러부분을 보고 추측한다.
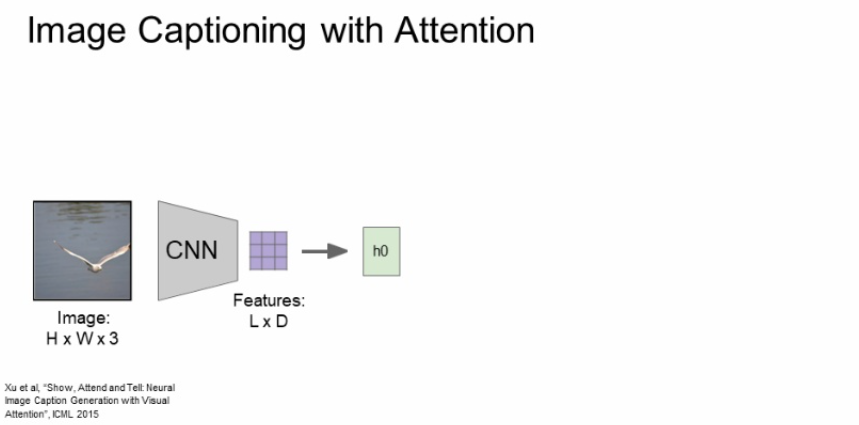
먼저, 이미지를 CNN에 넣어주고 featuers를 추출한다.
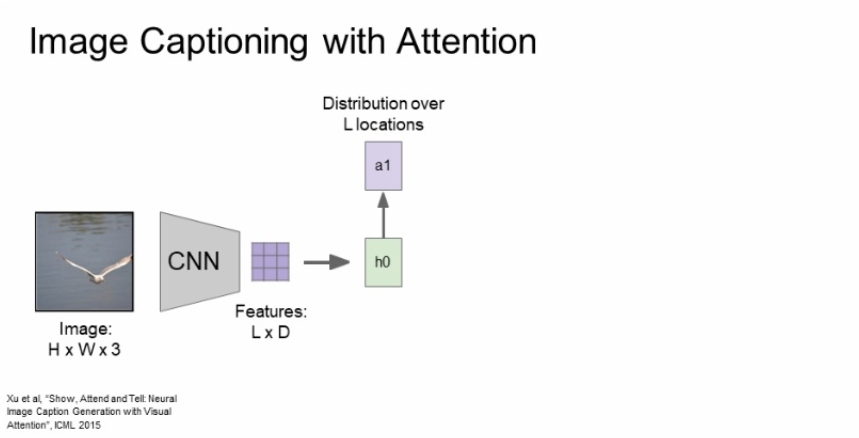
위에서 구한 feature grid를 첫번째 hidden state를 초기화 하는데 사용해주고, 이를 통해 a1이라는 것을 추출하는데 location에 대한 확률분포이다. 어떤 단어가 나올 것인가 확률분포를 구하는 것이 아니라 attention 할 위치에 대한 확률분포를 구하는 것이다.
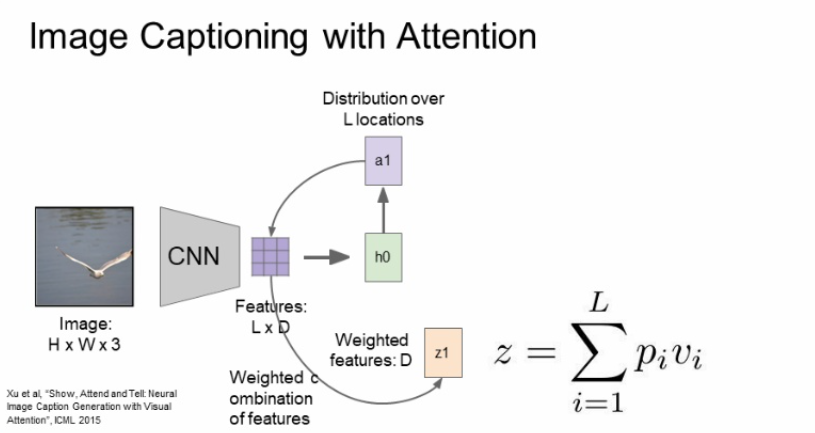
location에 대한 확률분포를 다시 feature와 연산해서 weighted feature를 구해준다. weighted feature가 비로소 feature vector가 되고 feature vector는 input 이미지를 요약해주는 sigle summarization vector가 된다.
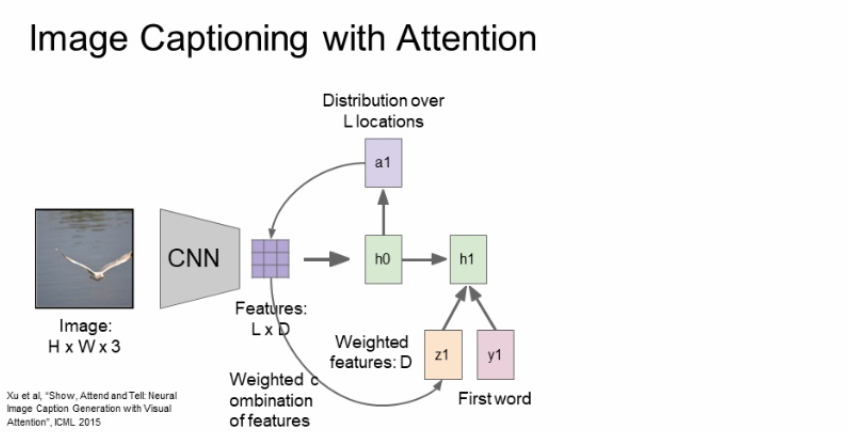
첫번째 단어와 z1(attention의 feature vector), h0(이전 단계의 hidden state) 3가지가 입력으로 들어와 h1을 생성하게 된다.
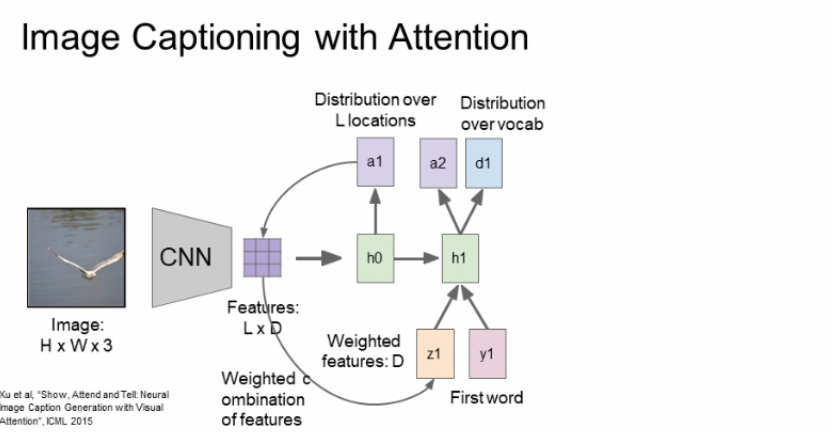
그러고 h1은 두가지의 출력을 내뱉고 d1이라는 것은 captioning에서도 봤다시피 단어에 대한 확률분포를 나타내는 것이고, a2는 또다시 위치에 대한 확률분포를 나타낸다.
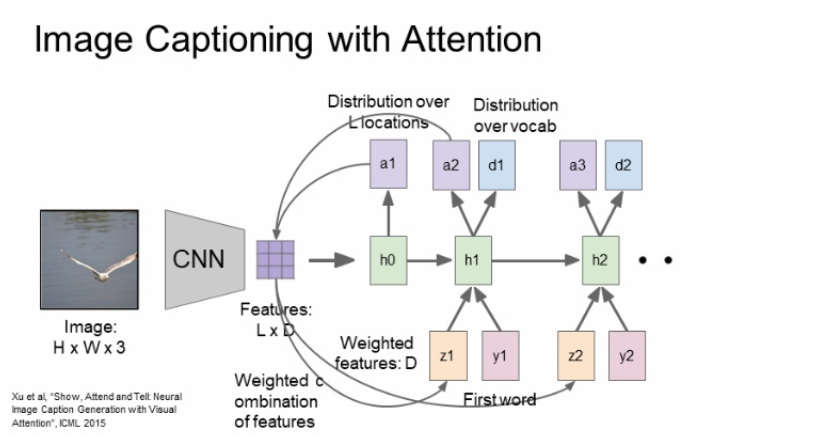
위의 과정을 계속해서 반복되는 것이다.

a값이 hidden state 마다 달라지니 attention하는 부분이 계속 달라지는 것을 볼 수 있다.
soft attention은 모든 특징과 weight를 보고, hard attention은 위치에 좀 더 집중한다고 한다.

실제로 훈련시킨 후 보면 어디를 보라고 메세지를 주지도 않았는데도 모델 스스로 학습하여 의미있는 부분에 attention한 것을 볼 수있다.

visual question answering은 (이미지, 그에 관련된 질문) 입력 2가지를 넣어서 답을 찾는 모델이다. 이 알고리즘도 CNN과 RNN을 합친 모델이며 many to one의 구조이다.
