-
회귀
회귀는 임의의 수치를 예측하는 문제로 타깃값도 임의의 수치다. -
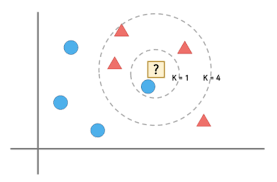
K-최근접 이웃 회귀
가장 가까운 이웃 샘플을 찾고 샘플들의 타깃값을 평균으로 예측한다. -
결정계수 (R^2)
대표적인 회귀 문제의 성능 측정 도구로 1에 가까울수록 좋고 , 0에 가까울수록 성능이 나쁜 모델이다. -
과대적합
훈련 세트 성능이 테스트 세트 성능보다 훨씬 높을 때 일어난다. 모델을 덜 복잡하게 만들어줌으로써 해결한다. (K-최근접 이웃 알고리즘의 경우 k값을 높여준다.) -
과소적합
테스트 세트 성능이 더 높거나, 훈련 세트& 테스트 세트 성능이 둘다 낮을때 일어난다. 모델을 더 복잡하게 만들어줌으로써 해결한다. (K-최근접 이웃 알고리즘의 경우 k값을 낮춰준다.)
-
KNeighborsRegressor
K-최근접 이웃 회귀 모델을 만드는 사이킷런 클래스다. n-neighbors 매개변수로 이웃의 개수를 지정하는데 기본값은 5로 지정되있다. -
mean_absolute_error()
회귀모델의 평균절대값오차를 계산한다. 첫번째 매개변수는 타깃, 두번째 매개변수는 예측값을 전달함으로써 타깃과 예측값이 얼마나 차이가 나는지 알 수 있다.
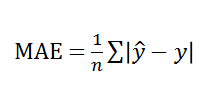
sum((타깃값-예측값)/전체갯수) -
reshape()
배열의 크기를 바꾸는 매서드이다. 바꾸고자하는 배열의 크기를 매개변수로 전달한다. 이때, reshape(-1, 열), reshape(행,-1) 처럼 -1을 넣어주면 나머지 숫자에 따라 자동으로 reshape가 된다.
k최근접 이웃 회귀
# 데이터 준비
import numpy as np
perch_length = np.array(
[8.4, 13.7, 15.0, 16.2, 17.4, 18.0, 18.7, 19.0, 19.6, 20.0,
21.0, 21.0, 21.0, 21.3, 22.0, 22.0, 22.0, 22.0, 22.0, 22.5,
22.5, 22.7, 23.0, 23.5, 24.0, 24.0, 24.6, 25.0, 25.6, 26.5,
27.3, 27.5, 27.5, 27.5, 28.0, 28.7, 30.0, 32.8, 34.5, 35.0,
36.5, 36.0, 37.0, 37.0, 39.0, 39.0, 39.0, 40.0, 40.0, 40.0,
40.0, 42.0, 43.0, 43.0, 43.5, 44.0]
)
perch_weight = np.array(
[5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0,
110.0, 115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0,
130.0, 150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0,
197.0, 218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0,
514.0, 556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0,
820.0, 850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0,
1000.0, 1000.0]
)
# 데이터 분석
import matplotlib.pyplot as plt
plt.scatter(perch_length,perch_weight)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
- 길이가 길수록 무게도 늘어나는 경향을 볼 수 있다.
# 훈련용, 테스트용 나누기
from sklearn.model_selection import train_test_split
train_input,test_input,train_target,test_target=train_test_split(perch_length,perch_weight,random_state=42)
# 왜 test_size를 안정해주지?
train_input= train_input.reshape(-1,1)
test_input=test_input.reshape(-1,1)
- 입력데이터는 feature와 샘플로 이뤄진 2차원 배열이여야해서 reshape 해줘야함
#k-최근접 이웃 회귀 모델 훈련
from sklearn.neighbors import KNeighborsRegressor
knr=KNeighborsRegressor()
knr.fit(train_input,train_target)
# 성능 측정 : 결정계수 R^2
print(knr.score(test_input,test_target))
결정계수는 0에 가까울수록 성능이 나쁘고 1에 가까울수록 성능이 좋은 모델로 볼 수 있다.
# 성능측정: 평균 절대값 오차
from sklearn.metrics import mean_absolute_error
test_prediction=knr.predict(test_input)
mae=mean_absolute_error(test_target,test_prediction)
print(mae)
- 평균적으로 예측값과 타깃이 19g정도 차이가 난다.
print(knr.score(train_input,train_target))
print(knr.score(test_input,test_target))
테스트 성능이 더 좋다 - 과소적합 - 모델을 더 복잡하게 만든다 - k-최근접이웃모델의 경우 k의 값을 줄인다.(default k=5)
knr.n_neighbors=3
knr.fit(train_input,train_target)
print(knr.score(train_input,train_target))
print(knr.score(test_input,test_target))
과소적합 해결!
참고문헌: 혼공머신
