더 깊게 레이어를 쌓아서 학습을 시킬 순 없을까?
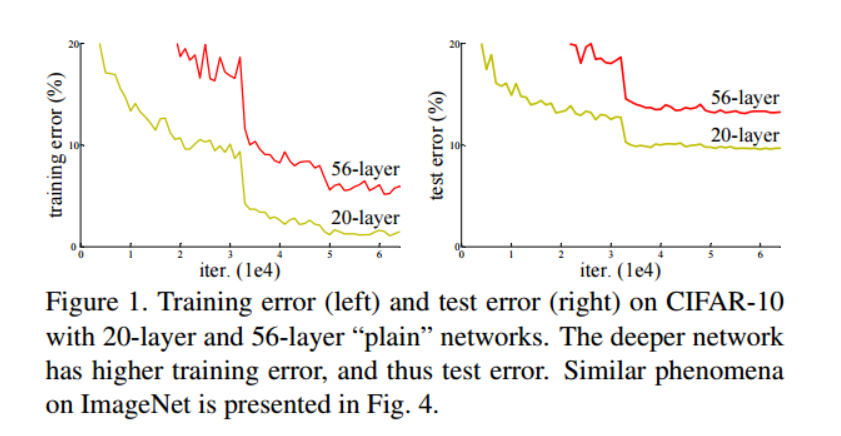
ResNet 이전까지의 모델들은 레이어를 깊게 쌓으면 gradient vanishing & exploding 문제가 발생하였다. 레이어를 깊게 쌓을수록 더 정확한 예측을 할 것이라 예상했는데 training 과 test 결과 56layer보다 20layer에서 성능을 더 좋게 보인 것이다.
Residual Block
그렇다면 어떻게 레이어를 깊에 쌓아서 성능을 좋게 만들 수 있을까?
그 해결책은 바로 Residual Block이다. 기존 방식에다가 앞서 학습된 정보를 출력값에 더해주는 skip/shortcut connection(지름길)을 만들어준 것이다.
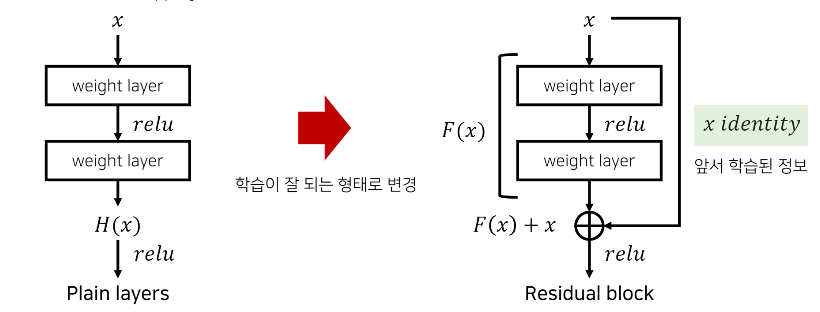
기존의 신경망은 H(x) = x 가 되도록 학습을 하였다.
레이어가 깊을수록 최적화가 어려운데 Residual Block을 사용하면 최적화가 좀 더 쉬워진다고한다. ResNet에서 H(x) = F(x)+x 로 정의하고 F(x)+x 를 최소화하는 방향으로 학습한다. 여기서 x는 이미 학습된 정보이기 때문에 변할 수 없는 값으로 보고 F(x)를 최소화하는 방향으로 학습한다고 보면 된다. 미분을 했을 때 x가 1이 되어 더해져서 gradient vanishing 문제도 해결한다.
※ 참고
F(x)를 최소로 해준다는 것은 H(x)-x 를 최소로 해주는 것과 동일하다. 여기서 H(x)-x를 잔차(residual)라고 하고 이를 학습하기에 ResNet이라고 부른다.H(x) = F(x) + x ➡ F(x) = H(x) - x
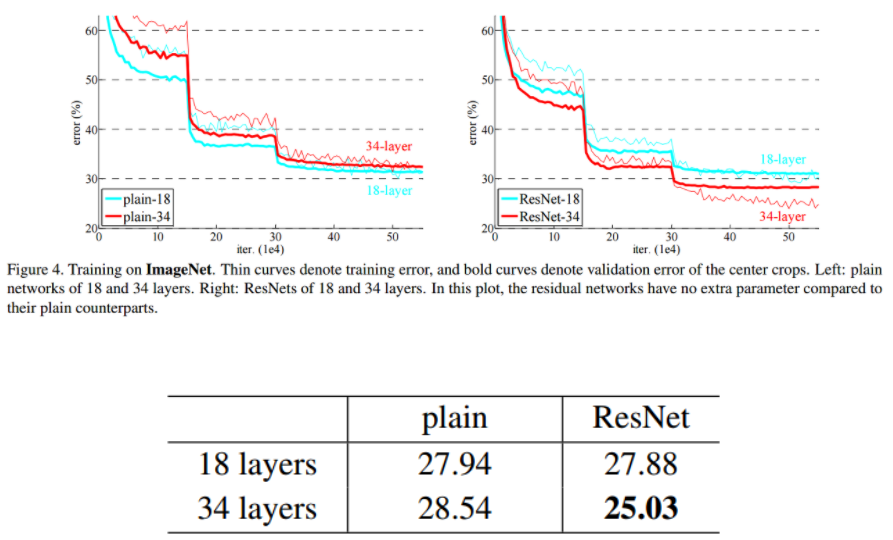
왼쪽의 plain 네트워크에서는 gradient vanishing 문제로 깊은 레이어가 얕은 레이어보다 성능이 안좋다. 하지만 오른쪽의 ResNet에서는 skip connection으로 gradient vanishing 문제를 해결하여 깊은 레이어가 성능이 더 좋은 것을 확인할 수 있다.
