-
로지스틱 회귀
선형방정식을 사용한 분류 알고리즘이다. 시그모이드 함수나 소프트맥스 함수를 사용하여 클래스 확률을 출력할 수 있다.
-
다중 분류
타깃 클래스가 2개 이상인 분류문제이다. 로지스틱 회귀는 다중 분류를 위해 소프트맥스 함수를 사용하여 클래스를 예측한다. -
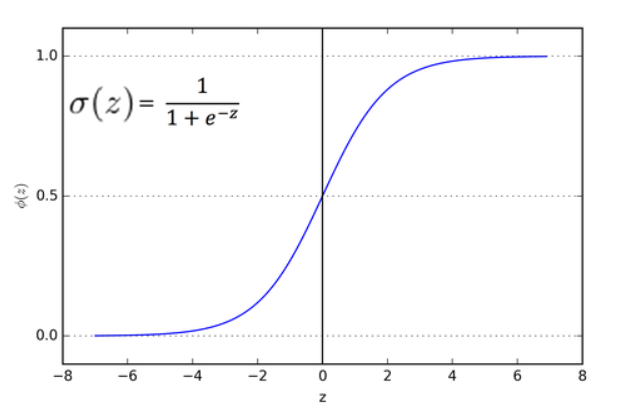
시그모이드 함수
이진분류를 위해 사용하고, 선형방정식의 출력을 0~1 사이의 값으로 압축한다. -
소프트맥스 함수
다중분류를 위해 사용하고, 여러 선형 방정식의 출력 결과를 정규화하여 합이 1이 되도록 만든다. -
LogisticRegression
선형 분류 알고리즘인 로지스틱 회귀를 위한 클래스이다. -
predict_proba()
예측 확률을 반환한다. -
decision_function()
모델이 학습한 선형 방정식의 출력을 반환한다.
이진 분류일 경우 양성클래스의 확률이 반환된다.
다중 분류일 경우 각 클래스마다 선형방정식을 계산해서 가장 큰 값의 클래스가 예측 클래스가 된다.
import pandas as pd
fish = pd.read_csv('https://bit.ly/fish_csv')
fish.head()
print(pd.unique(fish['Species']))
- pd.unique()를 사용하여 species의 고유한 값들을 출력한다(일종의 set 개념?)
- 총 7개의 종이 있다.
fish_input = fish[['Weight','Length','Diagonal','Height','Width']].to_numpy()
fish_target = fish['Species'].to_numpy()
- input과 target을 numpy배열로 저장해줌
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(
fish_input, fish_target, random_state=42)
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)
- 데이터 분리와 데이터들의 정규화를 시켜줌
1. k 최근접 이웃 분류기의 확률 예측
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier(n_neighbors=3)
kn.fit(train_scaled, train_target)
print(kn.score(train_scaled, train_target))
print(kn.score(test_scaled, test_target))
print(kn.classes_)
- KNEighborsClassifier에 정렬된 타깃값은 class_의 속성에 저장되있음
- print(pd.unique(fish['Species'])) 로 출력했던 순서와 달리 알파벳정렬이 되있음
print(kn.predict(test_scaled[:5]))
- 처음 5개 샘플에 대한 타깃값 예측
import numpy as np
proba = kn.predict_proba(test_scaled[:5])
print(np.round(proba, decimals=4))
- predict_proba 를 사용하여 각 클래스별 확률을 보여준다.
- 행:5개의 샘플 / 열: 각각의 클래스
- np.round(proba,decimals=4) 소수점 아래 5번째에서 반올림하여 4번째자리까지 표기한다.
distances, indexes = kn.kneighbors(test_scaled[3:4])
print(train_target[indexes])
잠깐 !!
- n_neighbors=3 으로 3개의 최근접이웃을 사용하면 확률이 0, 1/3, 2/3, 1 밖에 안나옴
- 연속적인 확률을 표기하기위해 로지스틱 회귀를 사용함
2. 로지스틱 회귀 (이진분류)
- 이름은 회귀지만 분류할 때 사용
bream_smelt_indexes = (train_target == 'Bream') | (train_target == 'Smelt')
train_bream_smelt = train_scaled[bream_smelt_indexes]
target_bream_smelt = train_target[bream_smelt_indexes]
- bream_smelt_indexes 배열은 도미와 빙어일 경우 true이고, 그 외 모두 false의 값이 들어있다.
- bream_smelt_indexes 의 배열을 사용해서 train_scaled와 train_target 에서 도미와 빙어만 골라낼 수 있다.
from sklearn.linear_model import LogisticRegression
lr=LogisticRegression()
lr.fit(train_bream_smelt,target_bream_smelt)
print(lr.predict(train_bream_smelt[:5]))
print(lr.predict_proba(train_bream_smelt[:5]))
- 첫번째 열 : 음성클래스에 대한 비율(bream)
- 두번째 열 : 양성클래스에 대한 비율(smelt)
print(lr.coef_,lr.intercept_)
decisions = lr.decision_function(train_bream_smelt[:5])
print(decisions)
- train_bream_smelt 의 5개 샘플의 z값
from scipy.special import expit
print(expit(decisions))
- 사이파이 라이브러리에서 시그모이드함수를 불러와 z값을 넣으면 그에 대한 확률로 변환된다.
- 출력된 값을 보면 predict_proba의 두번째열의 확률과 동일하다
- decision_function()은 양성클래스에 대한 z값을 반환하는 것이다.
3. 로지스틱 회귀 (다중분류)
lr=LogisticRegression(C=20,max_iter=1000)
lr.fit(train_scaled,train_target)
print(lr.score(train_scaled,train_target))
print(lr.score(test_scaled,test_target))
- 로지스틱회귀는 기본적으로 반복적인 알고리즘을 사용한다(max_iter로 조절)
- 로지스틱회귀에서 규제를 제어하는 매개변수는 C(작을수록 규제가 커짐)
print(lr.classes_)
print(lr.predict(test_scaled[:5]))
proba=lr.predict_proba(test_scaled[:5])
print(np.round(proba,decimals=3))
-
5개 샘플에 대한 예측(행)
-
7개 생선에 대한 확률(열)
-
K최근접이웃에서는 확률이 0, 1/3, 2/3, 1 이산적)
-
로지스틱회귀 이중분류에서는 도미와 빙어에 대한 확률만 출력)
print(lr.coef_,lr.intercept_)
print(lr.coef_.shape,lr.intercept_.shape)
- 다중분류는 클래스마다 z값을 계산함
decisions=lr.decision_function(test_scaled[:5])
print(np.round(decisions,decimals=2))
from scipy.special import softmax
proba=softmax(decisions,axis=1)
print(np.round(proba,decimals=3))
- 이진분류는 시그모이드함수를 사용하고,다중분류는 소프트맥스함수를 사용해서 z값을 변환한다.
- axis=1 로 지정해서 각 행에 대해 소프트맥스를 계산한다.
참고문헌:혼공머신
