scikit-learn(사이킷런)의 예제를 사용하여 해볼것이다.
데이터셋을 다루기전에 데이터셋의 정보를 먼저 확인하는 것이 중요하다.
( 몇개의 데이터가 있는지, 몇개의 정보가 담겨있는지 )
https://scikit-learn.org/stable/datasets/toy_dataset.html#breast-cancer-wisconsin-diagnostic-dataset
사이킷런의 유방암 진단 데이터셋을 사용해볼것이다.
1. 데이터 준비
from sklearn.datasets import load_breast_cancer
breast_cancer=load_breast_cancer()
breast_cancer_data=breast_cancer.data
breast_cancer에 여러 정보가 있는데 그 중에서도 data만 따로 뽑아 breast_cancer_data에 저장한다.
2.데이터 이해하기
0. 데이터셋 정보 확인
print(breast_cancer.DESCR)1. label,target 지정하기
머신러닝 모델에게 여러 정보를 입력했을 때 양성인지 음성인지 출력하도록 학습을 시켜야한다. 이때 머신러닝 모델이 출력해야하는 정답을 label,target이라고 한다.
breast_cancer_label=breast_cancer.target
breast_cancer_label

breast_cancer.target_names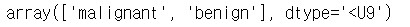
즉, label이 0이면 malignant 양성, 1이면 benign 음성이다.
2. feature data 지정하기
breast_cancer_feature=breast_cancer.feature_names3. dataframe으로 확인해보기
import pandas as pd
breast_cancer_df=pd.DataFrame(data=breast_cancer_data,columns=breast_cancer_feature)
breast_cancer_df['label']=breast_cancer_label # 맨끝쪽에 정답지 추가
breast_cancer_df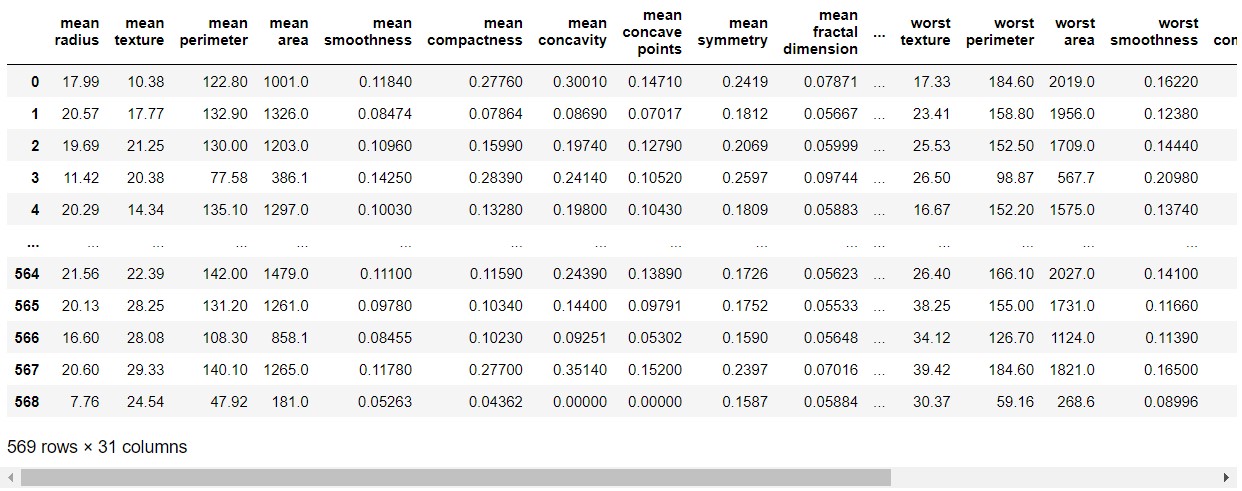
feature=문제지 ,변수 이름 x
label=정답지,변수 이름y
3.데이터 분리하기
모든 데이터를 train 하는데 다 써버리면 test를 할 수 없다.
그래서 train데이터와 test데이터를 분리해줘야한다.
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(breast_cancer_data,
breast_cancer_label,
test_size=0.2,
random_state=7)breast_cancer_data : feature의 역할 (문제지)
breast_cancer_label: target의 역할(정답지)
test_size: 총 데이터에서 테스트할 데이터의 비율
random_state:데이터가 일렬로 나열된 경우가 많기때문에 섞어준다.
4.모델 학습&테스트
우리는 머신러닝에게 정답을 주고 (지도학습) , 그 중에서도 양성인지 음성인지 분류하는 모델(분류)을 사용할 것이다.
1)Decision Tree 모델
- 학습하기
from sklearn.tree import DecisionTreeClassifier
decision_tree=DecisionTreeClassifier(random_state=32)
decision_tree.fit(x_train,y_train)
학습의 매서드는 fit이다.
- 테스트하기
from sklearn.metrics import classification_report
y_pred=decision_tree.predict(x_test)
print(classification_report(y_test,y_pred))
2)Random Forest모델
Decision Tree 모델은 feature의 수가 많으면 그걸로 하나의 결정트리로 만들어서 트리의 가지가 많아지고 결국 오버피팅을 야기한다.
그래서 feature 중 랜덤으로 몇개씩을 뽑아 결정트리를 여러개 만들어서 보완한 모델이 random tree이다.
즉, 하나의 거대한 결정트리를 만드는 것이 아니라 여러개의 작은 결정트리를 만드는 것이다.
- 학습&테스트
from sklearn.ensemble import RandomForestClassifier
random_forest=RandomForestClassifier(randomstate=32)
random_forest.fit(x_train,y_train)
y_pred=random_forest.predict(x_test)
print(classification_report(y_test, y_pred))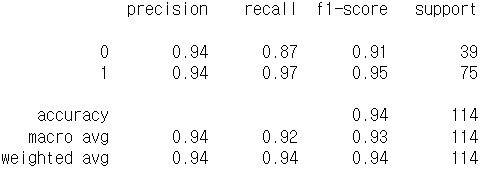
5. 모델 평가하기
유방암진단을 할 때 , 음성을 양성으로 진단하는 것보다 양성을 음성으로 진단하는 것이 더 큰 문제가 된다. 그래서 recall로 평가할 것이다.
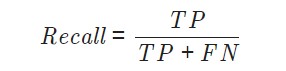
거짓 음성(FN)을 낮추는데 힘을 써야한다.
from sklearn.metrics import recall_score
recall=recall_score(y_test,y_pred)
recall