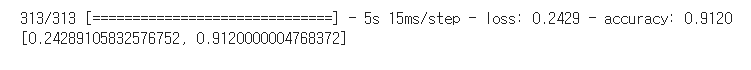8-1,2
- 합성곱
밀집층과 비슷하게 입력과 가중치를 곱하고 절편을 더하는 선형 계산이다. 밀집층과 다르게 각 합성곱은 입력 전체가 아니라 일부만 사용하여 선형 계산을 수행한다.
- 필터
밀집층으로 보면 뉴런에 해당하는 것이다. 필터의 가중치와 절편을 종종 커널이라고 부르기도 한다. 자주 사용되는 커널의 크기는 (3,3) 또는 (5,5)이다. 커널의 깊이는 입력의 깊이와 같다.
-
특성맵
합성곱 층이나 풀링 층의 출력 배열을 의미한다. 필터 하나가 하나의 특성맵을 만든다. 합성곱 층에서 5개의 필터를 적용하면 5개의 특성맵이 만들어진다. -
패딩
합성곱 층의 입력 주위에 추가한 0으로 채워진 픽셀이다. 패딩을 사용하지않으면 valid 패딩이라고 한다. 합성곱 층의 출력 크기를 입력과 동일하게 만들기 위해 입력에 패딩을 추가하는 것을 same 패딩이라고 한다. -
스트라이드
합성곱 층에서 필터가 입력 위를 이동하는 크기이다. 일반적으로 stride는 1픽셀을 사용한다. -
풀링
가중치가 없고 특성맵의 가로세로 크기를 줄이는 역할을 수행한다. 대표적으로 최대풀링,평균풀링이 있으며 (2,2) 풀랑으로 입력을 절반으로 줄인다.
from tensorflow import keras
from sklearn.model_selection import train_test_split
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
train_scaled = train_input.reshape(-1,28,28,1)/255.0
train_scaled,val_scaled,train_target,val_target = train_test_split(train_scaled,train_target,test_size=0.2,random_state=42)
- (48000,28,28) -> (48000,28,28,1) 로 reshape해줌
- Conv2D를 사용하기위해서는 깊이의 차원도 필요해서
model = keras.Sequential()
model.add(keras.layers.Conv2D(32, kernel_size=3, activation='relu', padding='same', input_shape=(28,28,1)))
model.add(keras.layers.MaxPooling2D(2))
- (28,28,1) -> (28,28,32) -> (14,14,32)
model.add(keras.layers.Conv2D(64, kernel_size=(3,3), activation='relu', padding='same'))
model.add(keras.layers.MaxPooling2D(2))
- (14,14,32) -> (14,14,64) -> (7,7,64)
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dropout(0.4))
model.add(keras.layers.Dense(10, activation='softmax'))
- flatten으로 펴준다음 Dense 층으로
- 은닉층과 출력층 사이에 dropout층을 넣어 과대적합을 막음
model.summary()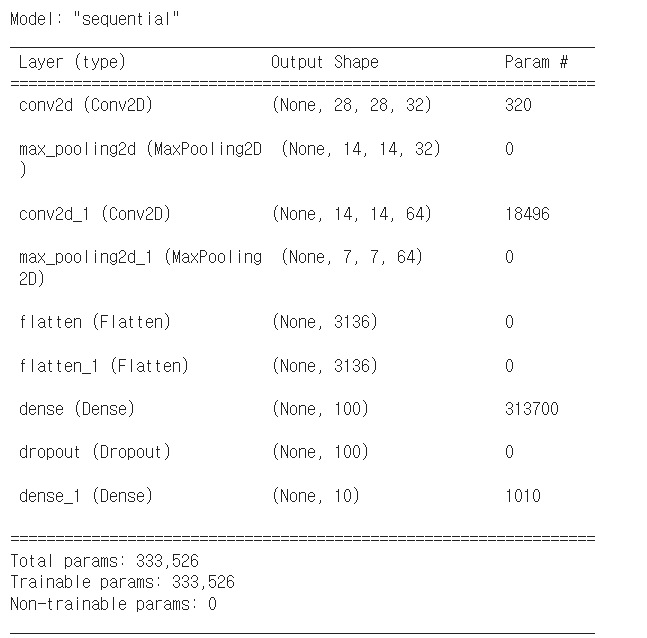
keras.utils.plot_model(model,show_shapes=True)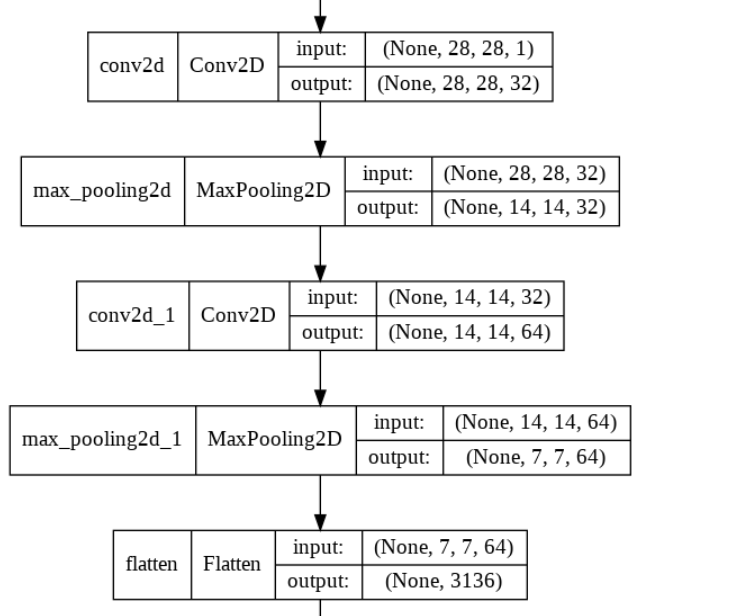
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics='accuracy')
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-cnn-model.h5',save_best_only=True)
early_stopping_cb = keras.callbacks.EarlyStopping(patience=2,restore_best_weights=True)
history=model.fit(train_scaled,train_target,epochs=20,validation_data=(val_scaled,val_target),callbacks=[checkpoint_cb,early_stopping_cb])
import matplotlib.pyplot as plt
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epochs')
plt.ylabel('loss')
plt.legend(['train','val'])
plt.show()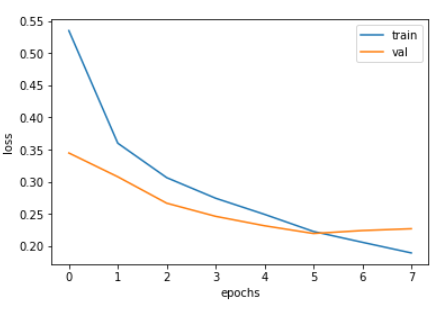
model.evaluate(val_scaled,val_target)
plt.imshow(val_scaled[0].reshape(28,28),cmap='gray_r')
plt.show()
pred = model.predict(val_scaled[0:1])
print(pred)
plt.bar(range(1,11),pred[0])
plt.xlabel('clss')
plt.ylabel('prob.')
plt.show()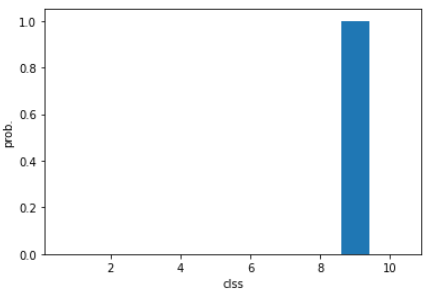
classes = ['티셔츠', '바지', '스웨터', '드레스', '코트',
'샌달', '셔츠', '스니커즈', '가방', '앵클 부츠']
import numpy as np
print(classes[np.argmax(pred)])
test_scaled = test_input.reshape(-1,28,28,1)/255.0
model.evaluate(test_scaled,test_target)