
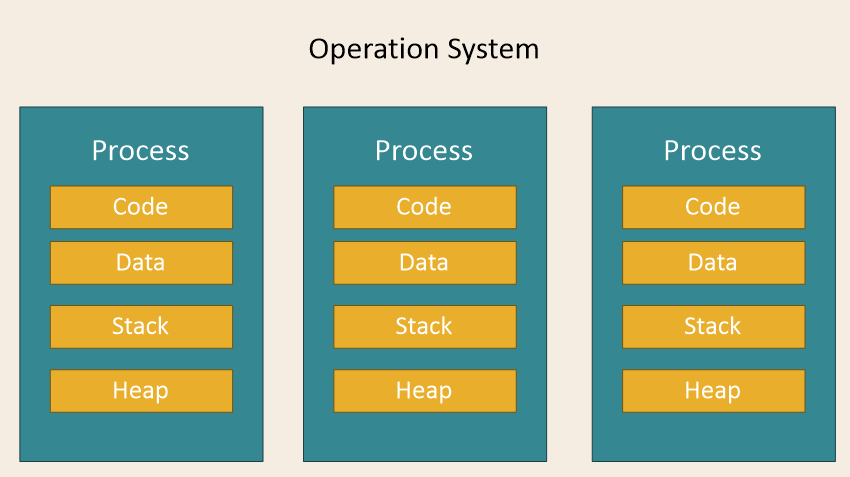
프로세스
- 운영체제로부터 시스템 자원을 할당받는 작업의 단위
- 컴퓨터에서 연속적으로 실행되고 있는 프로그램
- 메모리에 올라와 실행되고 있는 프로그램
- 메모리에 올라와 실행되고 있는 프로그램의 인스턴스
프로세스(process) = 코드영역(code) + 데이터 영역(data) + 스택 영역(stack) + 힙 영역(heap)
| 영역 | 설명 |
|---|---|
| Code | 코드 자체를 구성하는 메모리 영역 (프로그램 명령) |
| Data | 전역 변수, 정적 변수, 배열 등 (초기화된 데이터) |
| Stack | 지역변수, 매개변수, 리턴 값 (임시 메모리 영역) |
| Heap | 동적 할당 시 사용 (new(), mallock() 등) |
스레드
- 한 프로세스 내에서 동작되는 여러 실행의 흐름
- 프로세스 하나에 자원을 공유하면서 과정 여러 개를 동시에 실행시킬 수 있음
- 한 프로세서 내의 주소 공간이나 자원들을 대부분 공유
- 기본적으로 하나의 프로세스가 생성되면 하나의 스레드(메인 스레드)가 같이 생성됨
멀티 프로세스
- 하나의 컴퓨터에 여러 CPU 장착 -> 하나 이상의 프로세스를 동시에 처리(병렬)
| 장점 | 단점 |
|---|---|
| - 독립된 구조이므로 안정성이 높음 | - 각각 독립된 메모리 영역을 갖고 있으므로 - 작업량이 많을수록 오버헤드 발생 - Context Switching으로 성능 저하 |
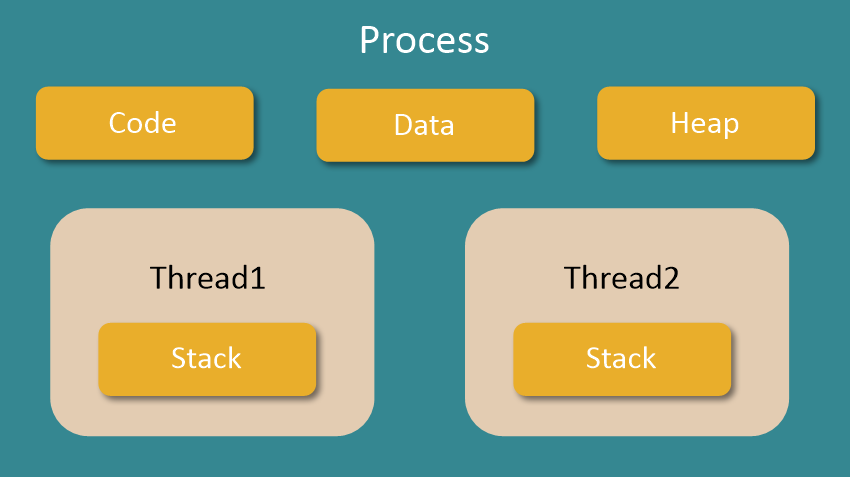
멀티 스레드
- 여러 개의 스레드를 가진 하나의 프로세스
[멀티스레드가 Code, Data, Heap 영역을 공유하고, Stack만 스레드별로 가지는 이유]
스택은 LIFO(Last In First Out : 후입 선출)의 특성을 가짐
스택이 쌓이면 위에서부터 프로세스가 섞인 채로 순서대로 나오므로 더 복잡해짐
원활한 실행 흐름을 위해 스택만 독립적으로 존재함
| 장점 | 단점 |
|---|---|
| - 프로그램의 응답 시간이 단축됨. - 시스템의 처리율이 향상됨 - 시스템의 자원 소모 감소함. - 프로세스 간 통신 방법에 비해 스레드 간의 통신 방법이 더 간단함 | - 여러 개의 스레드를 이용하는 경우, 작은 시간차나 잘못된 변수를 공유하여 오류 발생 가능 (스레드 간 통신할 경우 충돌 문제 방지하기 위해 동기화 문제 해결해야 함) - 프로그램 디버깅 어려움 - 단일 프로세스 시스템에서는 효과 기대 어려움 |
GIL(Global Interpreter Lock)
파이썬에서는 하나의 프로세스 안에 모든 자원의 락(Lock)을 글로벌(Global)하게 관리하여 한 번에 하나의 스레드만을 컨트롤하여 동작하도록 한다. 따라서 멀티 스레드가 단일 스레드의 효율이 비슷하다.
그러나, GIL이 적용되는 것은 CPU 동작이므로 스레드가 CPU 동작을 마치고 I/O 작업을 실행하는 동안에는 다른 스레드가 CPU 동작을 동시 실행할 수 있다. 따라서, CPU 동작이 많지 않고 I/O 동작이 더 많은 프로그램에서는 멀티 스레드만으로 성능을 크게 향상시킬 수 있다.
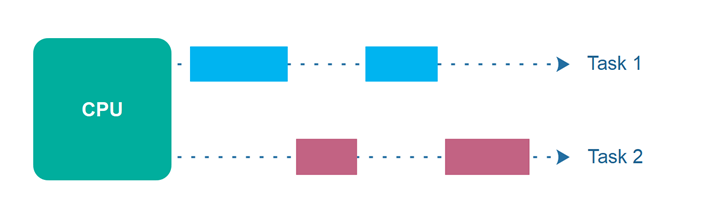
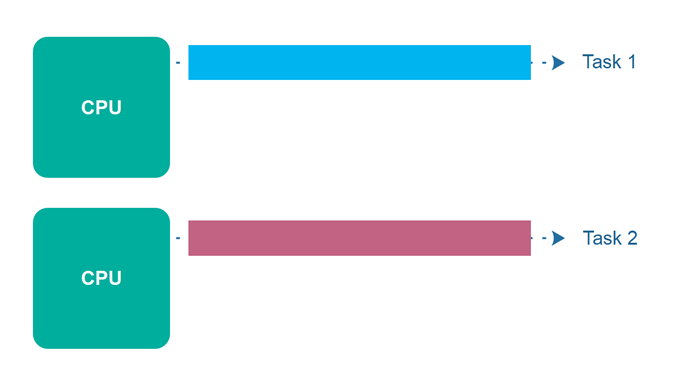
Concurrency(동시성) / Parallelism(병렬 처리)
| Concurrency | Parallelism |
|---|---|
| 단일 CPU 코어에서 두개의 task가 번갈아가면서 진행됨 | Parallelism은 실제로 둘 이상의 CPU 코어에서 두개의 task가 동시에 진행됨 |
Concurrency
Parallelism
참고
https://devuna.tistory.com/21
https://chacha95.github.io/2020-12-19-python4/
https://monkey3199.github.io/develop/python/2018/12/04/python-pararrel.html

A Data human as a Learner, a Supporter, and a Listener