LFS (Log-Structured FS)
-
디스크를 타겟으로 만들어진 시스템
-
특징 : 로그 스트럭쳐 : 모든 쓰기를 로그형태로 쓴다. 뒤에 차곡차곡 붙여 쓴다.
-
OUT OF PLACE , APPEND으로 쓴다.
-
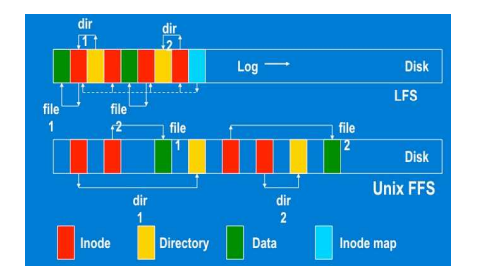
LFS vs FFS
-
dir1/file1 , dir2/file2 생성
-
FFS : 8개의 랜덤 write가 발생
-
LFS : 파일데이터 => 아이노드 => 디렉토리데이터 => 아이노드 ... 순차적
-
시퀀셜하게 쓰면 성능에 좋다. 이러면 아이노드가 고정된 위치가 아니다.
- 아이노드의 위치를 알려주는 매핑 테이블 정보를 따로 만들어줘야한다.(추가적인 write)
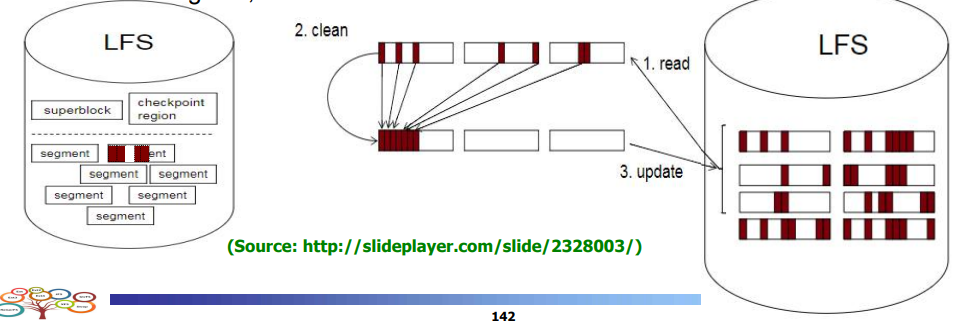
로그가 어떻게 관리가 되나?
-
세그먼트 컨셉 도입
-
LFS : 슈퍼블럭 , 체크포인트 영역(마지막에 쓰여진 메타데이터 정보,위치) , 세그먼트들
-
새로운 데이터를 쓴다면 세그먼트에 로그형태로 쓴다.
- 업데이트 시 invalid하고 뒤에 append한다.
- 흰색 부분이 invalid
-
세그먼트가 다 차면 가비지 컬렉션 발생 => 세그먼트 클리닝
-
세그먼트들을 회수해서 valid을 따로 빼냄
어떤 세그먼트를 꺼내서 clean?
- valid가 가장 적은 순으로 세그먼트를 가져옴
- valid한 데이터는 copy , 회수
- 슈퍼블럭은 고정된 위치
- 체크포인트 리전( 어느 블럭에 있는지 위치 기억 )
- 디렉토리 체인지 로그 ( 일관성 유지 )
쓰기 비용

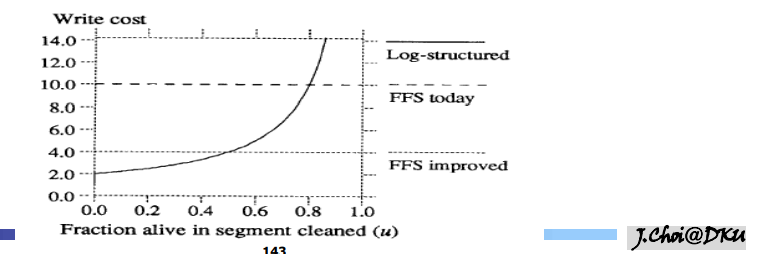
- 쓰기 비용에 대한 효과 적인 모델 제공
- 쓰기 비용
- u: 이용률
- u 가 증가할수록 스기 비용이 증가한다.
- 0.5를 기준으로 작으면 좋은 성능을 보인다
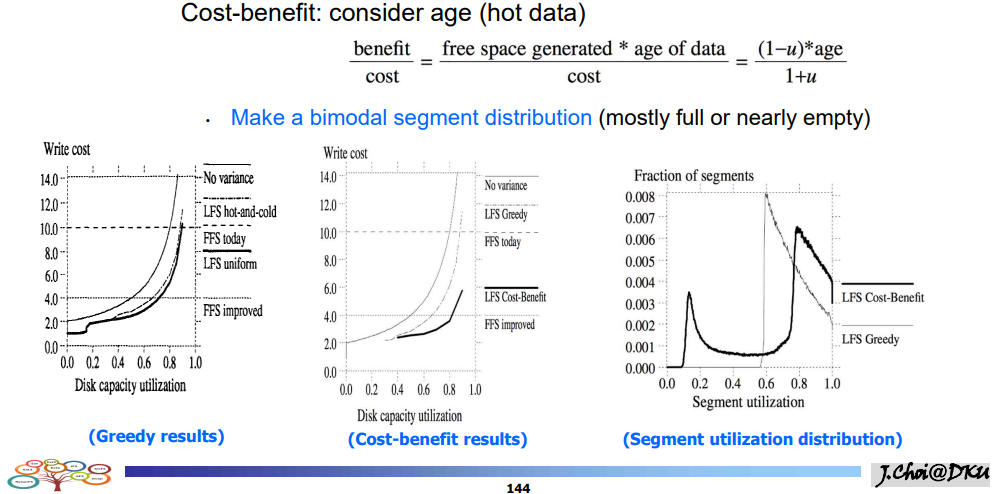
- 그리디 방식 : util이 낮은 것 선택(invalid가 많은 것)
- 0.6까지는 거의 선택이 되어서 존재 x , 거의 대부분의 seg가 0.6의 비슷한 seg를 보이는 분포
- cost benefit은 hot하다면 0.2정도는 기회를 준다. 나중에 갈수록 cost-benfit 방식이 더 효율이 좋아짐
어떤 세그먼트 선택?
-
그리디 : 유틸라이제이션이 가장 작은거 선택. 세그먼트 1 ,2 ,3 이 있을 때 0.1, 0.5 , 0.3 일 때 클리닝 비용이 seg1이 가장 작다. 그러므로 1을 선택하면 greedy 방식
-
세그먼트 나이 고려. 가장 최근 : 가장 핫하다. 나이가 적을수록 냅둔다.
-
cold 데이터중에 util이 작은 것
우려들
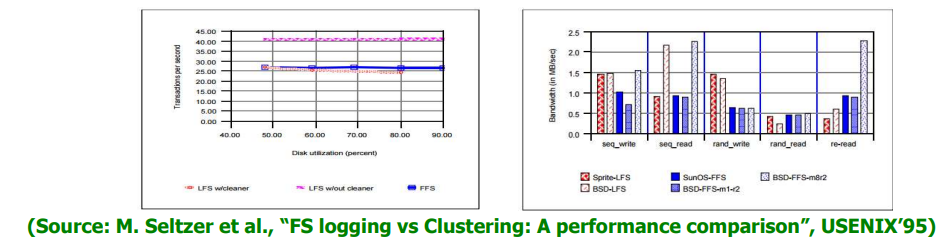
-
클리닝 오버헤드가 크지 않나?
- 클리닝이 있으면 성능이 낮아진다 ==> 논문
-
re-read인 경우 성능이 좋지 않다.
로그 스트럭쳐 FS와 플래시메모리
- 플래시 메모리는 오버라이트가 안되기때문
- 이후 FTL , F2FS 등등이 만들어짐

F2FS (Flash Friendly FS)
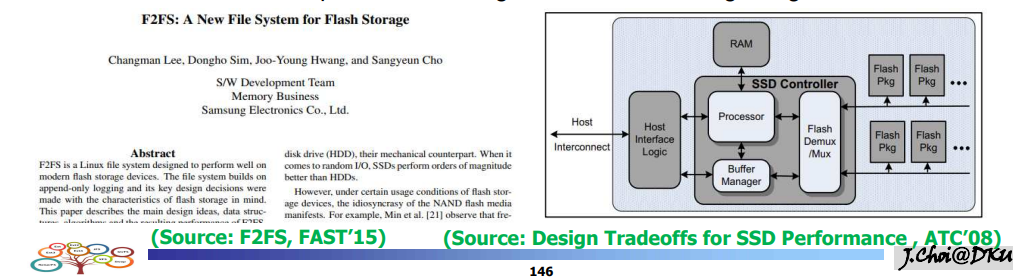
목표 : 플래시 메모리 특화된 파일 시스템을 원한다.
- 플래시 특성 : 로그 스트럭쳐
- Erase Before Write (단위가 다름) 페이지 단위 vs 블럭 단위
- 다양한 에러 : erase 횟수 제한 , 리텐션 , 옆의 셀에서의 간섭
- 위의 특성들을 인지한 파일시스템을 만드는게 목적
- SSD 내부에 굉장히 다양한 병렬 유닛이 존재.
- 프로세서 , RAM , Flash Demux/mux ==> FTL의 기반
- 퍼포먼스 고려 ==> 멀티 로깅 / 핫 콜드 구분 - 플래시 칩 : 여러개의 칩들이 여러개의 채널로 연결된다. 멀티채널/멀티웨이
- Write Clip(쓰기 절벽) : 처음엔 성능이 좋다가 가비지 컬렉션이 트리거되고 오버헤드되면 성능이 나빠짐
- 가능한 핫, 콜드 구분한다.
- 프로세서 , RAM , Flash Demux/mux ==> FTL의 기반
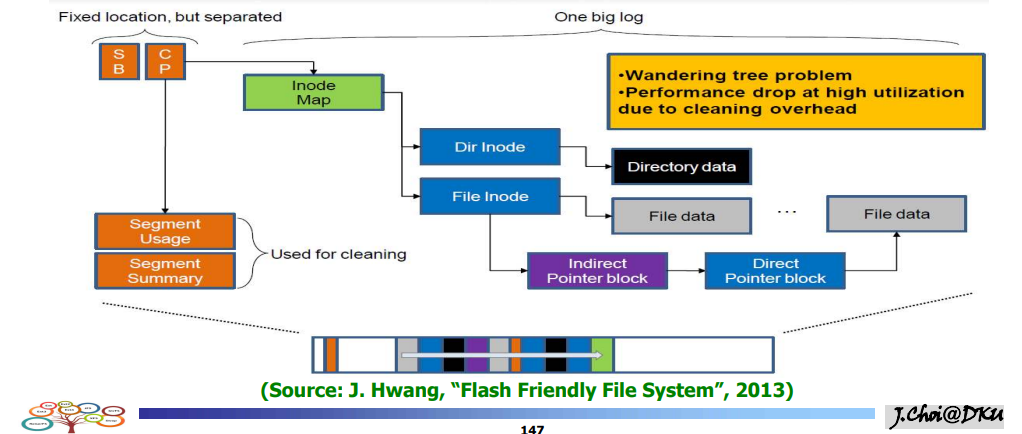
Based on LFS
-
슈퍼블럭, 체크포인트 리전 (고정위치)
-
슈퍼블럭 : 파일시스템 정보
-
체크포인트 리전 : 아이노드 위치, 세그먼트 정보(usage , summary)
-
세그먼트는 로그 구조로 이루어짐(apped형식)
-
아이노드의 일부는 디렉토리 , 일부는 파일아이노드
- 사이즈가 커지면 INdirect 포인터 => 파일데이터
문제점 ====> 한 데이터가 수정되면 상위데이터까지 수정해야한다.
-
overwrite가 안되니 다른 페이지에 작성했을 것 => 이 위치를 가리키는 포인터 블럭도 수정을 해야한다. => 파일 아이노드 , 아이노드 맵 , 체크포인트까지 수정해야한다.
-
클리닝 오버헤드 : 퍼포먼스 이슈
F2FS에서의 해결책
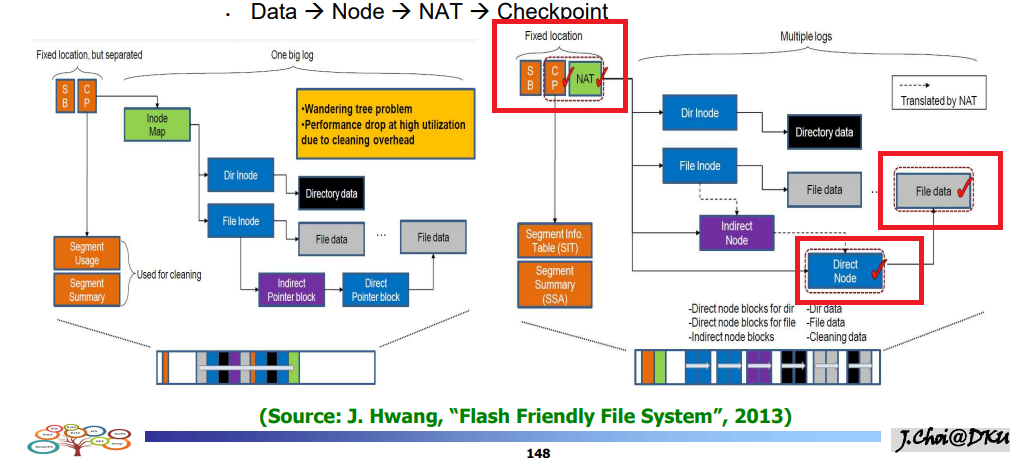
- F2FS에서는 Index 블럭을 Node로 지칭한다.
- 노드 데이터를 수정하는 것 까지는 똑같다.
- ex) 10번에서 11번으로 옮겨졌다고 하더라도 노드의 논리적 번호는 변하지 않는다.
- ex) 10번(플래시 메모리상의 10번 물리페이지) => 10번이 아니고 11번
- 하지만 NAT 주소변환을 사용하면 10번이 11번인 것을 알 수 있다.
- Node , NAT , 체크포인트 리전만 바꾸면 된다.
- 6번의 업데이트 => 4번의 업데이트
- 노드 데이터를 수정하는 것 까지는 똑같다.
F2FS의 다른 특징틀
-
노드 블럭 : 주소 변환(NAT) , Wandering Tree Problem 해결
-
멀티 헤드 로깅 : 여러 세그먼트들을 쓰고 동시에 플러시 (병렬유닛 최대로 활용)
-
핫 콜드 분화 : 클리닝 오버헤드 줄임
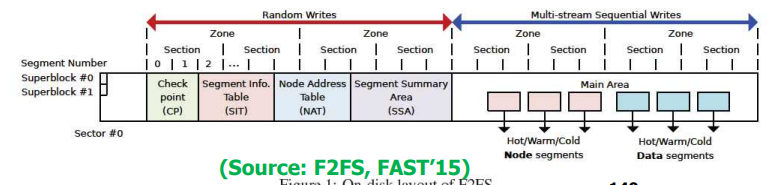
<그림.F2FS의 내부구조>
-
슈퍼블럭 , 체크포인트 , 세그먼트 summary ,NAT , seg usage
-
메타데이터와 일반데이터로 구분함.
- 끼리끼리 로깅을 하여 write를 한다.
- 메타데이터,데이터는 Hot / Warm / Cold 로 나뉨
- 서로다른 6개의 데이터가 멀티 로깅되는 구조
-
hot/cold 분화, hot이면 다시 참조될 확률이 높다.
- invalid 페이지가 많다.
-
cold : 대부분 valid
====> LFS에서의 성능그래프가 그려짐 -
세그먼트를 모아서 => 섹션 , 섹션을 모아서 => 존으로 관리
- 세그먼트 : 할당 , 섹션 : 클리닝 , 존 : 로깅
- 존 : 메타데이터 존 , 데이터 존

-
스레디드 로깅 : 이용률이 높을 때 , Copy하는 오버헤드가 없고 점프하면서 쓴다.
-
노멀 로깅 : 세그먼트 클리닝 => valid를 한쪽으로 모으고 나머지를 free한다.
- 이용률이 높아지면 대부분이 valid한 블럭이라서 copy하는 오버헤드가 커진다.
정리
- FTL 성능 분석
- 덮어쓰기 x
- write erase 단위 다름 / 페이지 vs 블럭
- erase 횟수제한 , 리텐션 , 왜란
- retention : 셀이 물리적인 특성으로 인해 전하가 센다. 점점 줄어들어서 원래있던 비트가 아닌것에 걸리면 리텐션에러다. // 전하의 개수로 0 , 1을 결정한다.
- ex) 0~50개 : 1 , 51~100개 : 0
- 줄어들다보면 비트플립이 발생
- disturbance : 3번 페이지를 할때 2 , 4에도 약한 전압을 건다. 약한 영향을 끼치면 간섭이 생긴다
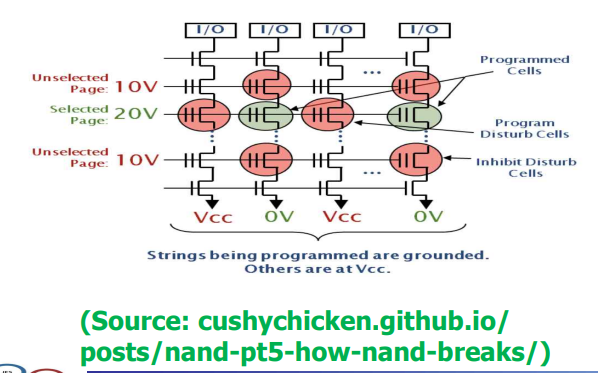
- 가로줄 한줄이 페이지
- 페이지에 고전압을 건다. 현재 3번페이지에 20V를 걸었음
- 2 , 4에도 약한 전압을 걸면 셀에 영향이 감
- 집적도가 높아지면서 0 , 1로만 판단하던걸 00 01 10 11로 판단해야함
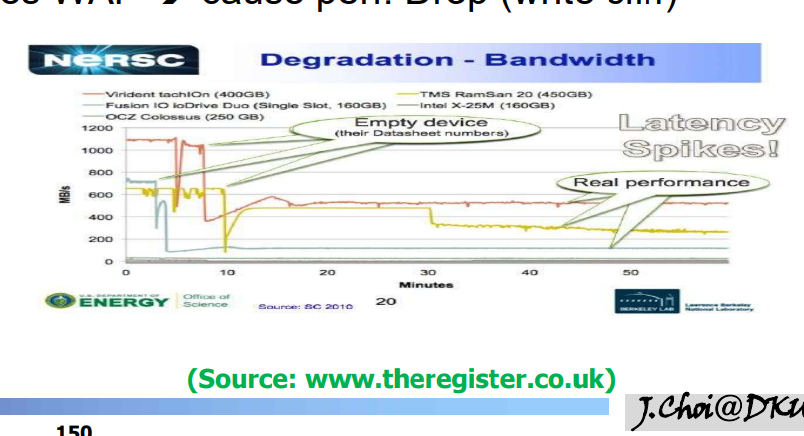
- write cliff를 보여주는 그래프
가비지 컬렉션 오베헤드를 줄이는 법
- 그리디 , 에이지기법
- Streamd SSD : 핫 , 콜드를 명시적으로 SSD에 알려줌.
가비지 컬렉션 분석
- 가비지 컬렉션 발생시 writes와 erases를 평가한다. write cost
- 다양한 정책으로 비교
- 4개의 블럭, 각 블럭마다 4개의 페이지
- 위쪽 그리디, 아래쪽 코스트 베네핏
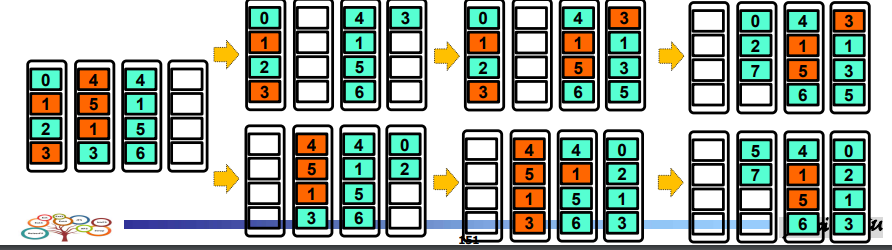
- 나이를 고려하면 B0가 가장 오래됨 , B1이 최근 , B2가 가장 최근
- B0가 B1에 비해 util이 높긴 하지만 가장 오래되어서 선택한다.
- 0,1 복사하고 erase한다. 0,2 는 B3에 입력
- 5,7은 erase 후 블럭 중 한 곳을 골라서 삽입
