H-Index는 과학자의 생산성과 영향력을 나타내는 지표입니다. 어느 과학자의 H-Index를 나타내는 값인 h를 구하려고 합니다. 위키백과1에 따르면, H-Index는 다음과 같이 구합니다.
어떤 과학자가 발표한 논문 n편 중, h번 이상 인용된 논문이 h편 이상이고 나머지 논문이 h번 이하 인용되었다면 h의 최댓값이 이 과학자의 H-Index입니다.
어떤 과학자가 발표한 논문의 인용 횟수를 담은 배열 citations가 매개변수로 주어질 때, 이 과학자의 H-Index를 return 하도록 solution 함수를 작성해주세요.
초기 코드
def solution(citations):
answer = 0
citations.sort(reverse=True)
for i in range(len(citations)):
if i+1 == citations[i] and answer < citations[i]:
answer = citations[i]
return answer처음에는 문제 이해를 잘못했다.
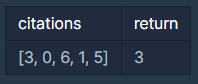
이러한 문제 예시를 보고 인덱스랑 인용횟수랑 같아지는 h를 찾으면 되는구나 라고 생각했다.
근데 히든에서 다 틀리더라
그러다가 도저히 무슨 말인지 모르겠어서 질문게시판을 뒤져봤다.
그러다가 승한이 형을 봤다 ㅋㅋㅋㅋㅋ 너무 반가웠따.
아무튼!
문제를 재정의할 필요가 있었다.
여기를 방문해서 H-Index에 대해 다시 정립하고 문제를 풀었다.
두번째 코드
def solution(citations):
answer = 0
citations.sort(reverse=True)
for i in range(len(citations)):
if i+1 <= citations[i]:
answer += 1
return answer저 링크에서 말한대로 코드를 짜니 바로 해결됐다!!
답은 citations안에서 찾는게 아니라 h에 집중해서 풀면 되는 거였다.
정렬을 해준다음에 인덱스보다 높은 인용횟수만 카운트해줬다.

성장스택 쌓고있는 개발자🏋