Det3D (Class-balanced Grouping and Sampling for Point Cloud 3D Object Detection)
Abstract
nuScenes 3D 객체 탐지 챌린지에서 우승한 방법을 소개한다. 우리는 Sparse 3D 컨볼루션을 사용해 시맨틱 특징을 추출한 다음 Class-balanced multi-head 네트워크를 사용해 객체를 탐지한다. 클래스 불균형 문제를 해결하기 위해 Class-balanced 샘플링과 어그멘테이션 전략을 설계했다. 또한, 유사한 형태를 가진 카테고리의 성능을 향상시키기 위해 balanced grouping head를 제안한다.
1. Introduction
KITTI 데이터셋은 3개의 카테고리를 분류하지만, nuScenes(NS) 데이터셋은 10개의 카테고리를 분류해야한다. NS 데이터셋의 클래스는 심각하게 불균형하기 때문에 그림 2와 같이 긴 꼬리 분포를 가지고 있다. 클래스도 복잡하고 클래스의 분포도 고르지 않아 난이도가 높지만 실제 시나리오와 가깝다.
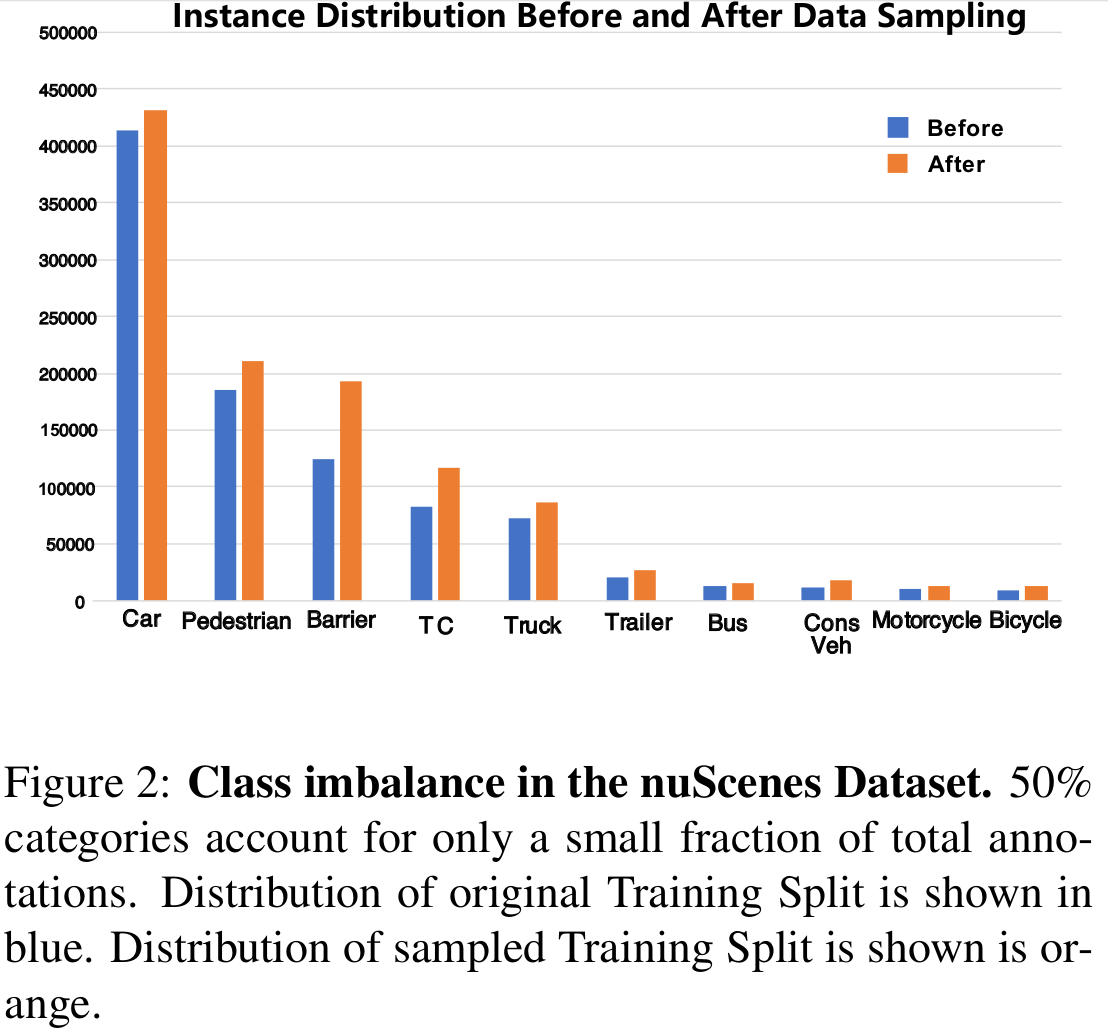
현존하는 많은 3D 객체 탐지 모델들은 Bird-Eye-view기반의 2D 컨볼루션, 복셀 기반의 3D+2D Convolution, PointNet기반 방식등 다양한 방법들이 존재하나, 모든 방법들은 하나의 카테고리에 각각 수행되어야 만족할만한 성능이 나왔다.
Multi-Category joint detection은 Multi-Task learning 문제로 간주될 수 있기 때문에, Multi-Task learning 기법은 많이 사용되는 기법이다. 이 기법을 사용하여 성능을 높힐 수 있다.
Contribution
- NS 데이터셋의 클래스 불균형을 보완하기하 위해 클래스 밸런스 샘플링 전략을 제안한다.
- 멀티 그룹 헤드 네트워크를 통해 비슷한 모양과 크기의 카테고리는 서로에게 도움이 되고, 모양과 크기가 다른 카테고리는 서로 간섭하지 않지 않게 설계가 가능하다.
2. Methology
어그멘테이션, 손실함수, 학습 절차의 개선과 함께 각 카테고리를 각각 감지하는 것보다 더 나은 성능을 달성했다.
2.1. Input and Augmentation
NS 데이터셋은 (, , , intensity, ringindex) 형태의 포인트 클라우드 정보를 제공하지만 우리는 (, , , intensity, ) 형태로 인풋 형태를 변환한다. 는 키프레임과 키프레임이 아닌 프레임간의 시간차로 0~0.45초 사이의 값을 가진다. 그리드 사이즈는 x, y, z 축으로 0.1, 0.1, 0.2m 이며 포인트 클라우드를 복셀로 일단 변환한다. 각 복셀의 모든 포인트 점의 평균을 구해 네티워크에 최종 입력을 얻고 별도의 정규화 처리는 하지 않는다.
NS 데이터셋의 클래스 불균형을 완하하기 위해 DS Sampling을 제안한다. DS Sampling은 전체 샘플의 카테고리 비율에 따라 각 카테고리의 샘플을 복제하되 샘플 수가 적을수록 더 많이 복제하는 방식이다.
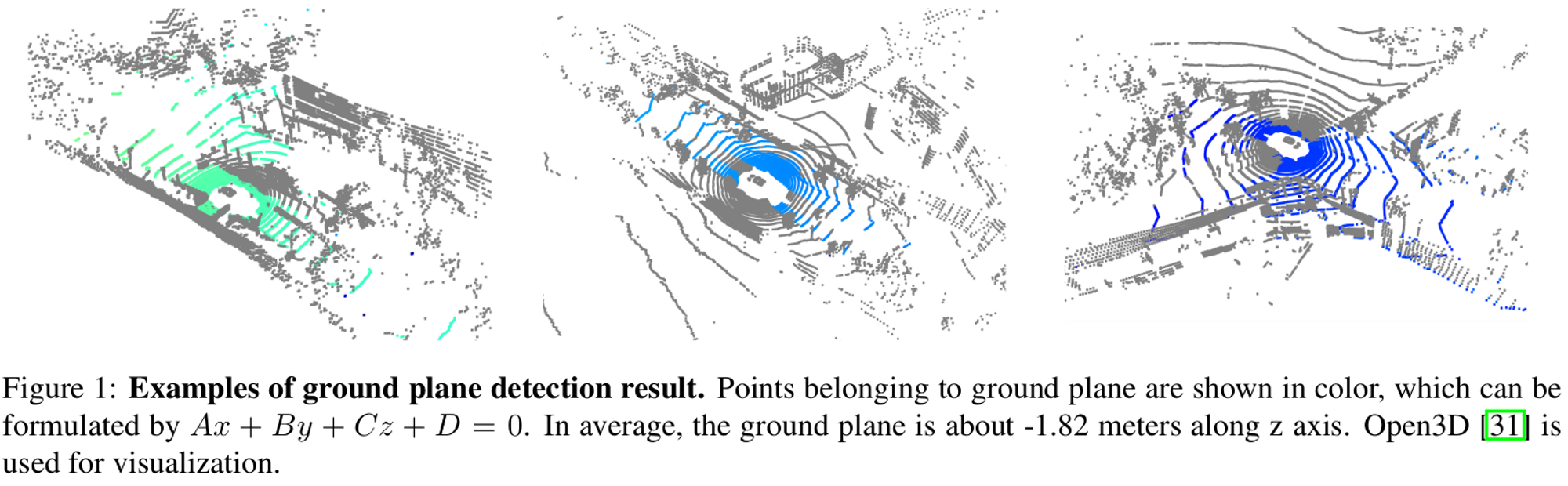
추가로 사용한 전략이 SECOND에서 제안한 GT-AUG 전략이다. 오프라인에서 생성한 GT Database에서 GT를 샘플링하고, 그 샘플링된 GT를 다른 포인트 클라우드에서 사용한다. GT 박스를 올바르게 배치하기 위해 지면을 RANSAC으로 계산하여 지면 위에 올라오도록 배치한다.
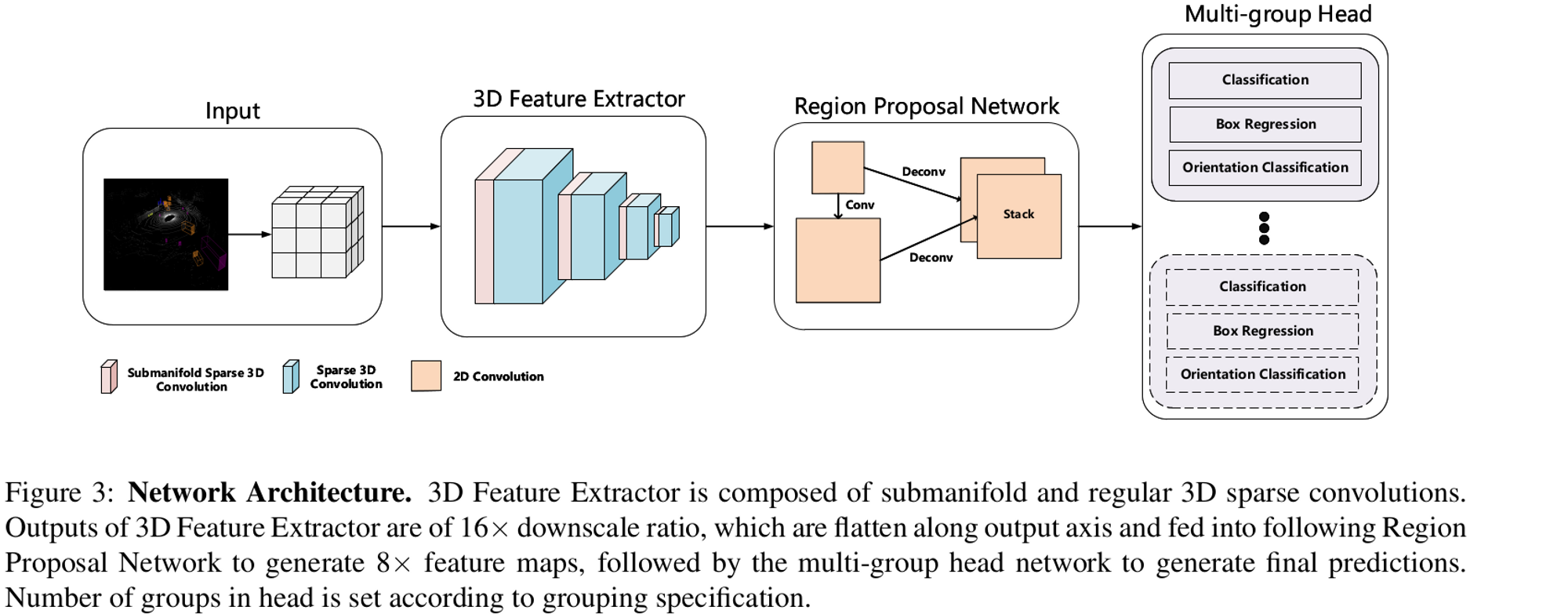
2.2. Network
그림 3과 같이, SPConv3D와 Skip-Connection를 사용해 ResNet과 유사한 3D 특징 추출 네트워크를 구축한다.
X X X 크기의 텐서가 입력으로 들어오면 특징 추출 네트워크는 X X X X 크기의 특징맵을 출력하며, 과 은 , , 차원의 다운스케일 팩터, 은 3D 특징 추출 네티워크 마지막 레이어의 출력 채널 수이다. 3D 특징맵을 RPN과 Multi-group head에 적합한 형태로 가공하기 위해 X X X 형태로 Reshape을 하고 2DConv와 DeConv를 수행해 더욱 통학하고 높은 해상도의 특징맵을 얻는다.
2.3. Class-balanced Grouping
초기의 긴꼬리 클래스 분포 데이터셋의 경우 분포가 다른 클래스를 하나의 헤더에서 처리하려고 하면 빈도가 높은 클래스에 너무 영향이 치우쳐 희귀한 클래스의 성능이 저하된다. 반면 모양이나 크기가 서로 다른 클래스를 하나의 헤더에서 처리하려고 하면 서로 간섭을 일으켜 성능이 저하될 수 있다.
직관적으로 비슷한 모양이나 클래스는 하나의 헤더에서 학습해 공통의 특징을 학습할 수 있도록 하여 높은 성능을 얻는 것이 좋다. 이를 위해 몇가지 원칙에 따라 모든 카테고리를 여러 그룹으로 나누어 학습한다.
- 모양과 크기가 비슷한 카테고리는 그룹화한다. 모양과 크기가 비슷한 그룹은 논리적으로 두 단계로 분류를 수행한다. 먼저 모델은 데이터가 들어오면 그룹을 먼저 인식한다. 그다음 그룹 내 카테고리의 다른점을 그룹헤드에서 학습하고, 서로 다은 그룹은 서로 다른 모양과 크기 패턴을 학습한다.
- 서로 다른 그룹의 데이터 수는 적절하게 균형을 이루어야 한다. 서로 다른 구륩의 데이터 수가 크게 다르면 학습과정이 메이저 클래스에 의해 지배될 수 있기 때문에 메이저 클래스는 따로 그룹으로 빼는 것이 좋다. 예를 들어 차와 트럭, 건설기계는 모양과 크기가 비슷해 같은 그룹으로 묶을 수도 있지만 차는 다른 카테고리보다 데이터 수가 많기 때문에 차를 하나의 그룹으로, 트럭과 건설기계를 하나의 그룹으로 따로 묶는 것이 좋다. 그 다음 그룹별로 가중치를 제어해 불균형 문제를 완화할 수 있다.
위의 두 가지 원칙에 따라 최종 설정에서 10개의 클래스를 (Car), (Truck, Construction Vehicle), (Bus, Trailer), (Barrier), (Motorcycle, Bicycle), (Pedestrian, Traffic Cone) 등 6개 그룹으로 나누었습니다. 표 4에 표시된 ablation 연구에 따르면, 클래스 균형 그룹화가 최종 결과에 가장 큰 기여를 한 것으로 나타났다.

2.4. Loss Function
기존의 3D 객체 탐지 모델에서 사용한 분류와 회귀 브런치 뿐만 아니라, SECOND에서 제안된 Orientation 분류 브런치를 추가했다. Orientation 분류 브런치를 그대로 사용하면 예측된 바운딩 박스의 방향이 실제 방향과 정반대인 경우가 많아 mean Average Orientation Error (mAOE)가 높기 때문에, 오프셋을 Orientation 분류 브런치에 추가해 모호성을 제거하였다. 속도 추정의 경우, 정규화 없이 회귀하는게 성능 상 이득이 있었다.
GT 박스의 사전 정보를 사용해 앵커에 적용함으로서 학습 난이도를 낮출 수 있다. 클래스별로 앵커는 하나의 크기, 두개의 다른 방향으로 구성되며 속도는 x, y축 모두 0으로 설정된다. 물체는 지면을 따라 이동하므로 z축의 속도는 추정할 필요가 없다.
각 그룹마다 분류는 Weighted Focal Loss를 사용하고, 회귀에서는 smooth-L1 loss를 사용해 x, y, z, l, w, h, yaw, v_x, v_y를 구하며, orientation은 softmax cross-entropy를 사용해 분류한다.
멀티 그룹 헤드는 Uniform Scaling을 사용해 각 헤드의 가중치 합이 1(n*[1/n])이 되도록 설정한다.
2.5. Other Improvements
SENet이나 Weight Standardization을 사용해 더 성능을 개선시킬 수도 있다.
3. Training Details
이장에서는 어그멘테이션의 구현과 훈련 절차 및 방법에 대해 자세히 설명한다. 포인트 클라우드는 x: [-50.4 ~ 50.4], y: [-51.2, ~ 51.2], z: [-5, 3] 범위로 ROI를 제한해 사용한다. 복셀 사이즈는 가로 세로 0.1 m, 높이 0.2 m로 설정하여 총 복셀의 수는 1008 X 1024 X 40개이다. 복셀 내 포인트 최대 수는 10개, 비어있지 않은 최대 복셀 수는 60000개로 설정하였다.
학습 동안 어그멘테이션은 x축으로 랜덤 플립, [0.95 ~ 1.05]로 스케일 샘플링, Z 축으로 [-22.4 ~ 22.4]도 회전 샘플링, 모든 축으로 0.2 m 이동 샘플링을 적용하였다. GT-AUG를 위해 일단 GT 내 포인트 개수가 5개 미만은 필터링하고, 표 5와 같이 서로 다른 클래스의 GT 박스를 랜덤 샘플링해 붙혀 넣었다.

3.1. Training Procedure
AdamW 옵티마이저와 one-cycle policy를 사용해 학습하였다. 최대 러닝 레이트는 0.04, division factor는 10, 모멘텀 범위는 [0.95 ~ 0.85], Fixed weight decay는 0.01로 설정하였다. 배치 사이즈가 5이면 에포크는 20으로 설정하고, NMS 임계값은 0.1, IoU 임계값은 0.2로 설정하였다. 추론에서 1000개의 proposal들은 NMS 이후 80개로 줄어든다.
3.2. Network Details
3D 특징 추출기에서는 각 블록에 대해 16, 32, 34, 128개의 SpConv 레이어를 사용한다. 특징맵을 다운 샘플링할 때는 SubSpConv를 사용하였다. 다른 조건에서는 일반적인 SpConv가 적용된다. RPN 모듈에서는 다운 스케일 비율이 16배, 8배인 레이어에 각각 128, 256개의 레이어를 사용한다. 각 헤드에선 1X1 컨볼루션을 적용해 최종 예측을 얻는다. 헤드를 더 무겁세 만들려면 하나의 3X3 컨볼루션 레이어를 사용해 채널을 1/8배로 줄인 후 1X1 컨볼루션을 사용해 최종예측을 얻는다. 마지막 레이어를 제외한 모든 레이어에 배치 정규화를 적용한다.
앵커 사이즈는 GT의 평균 크기를 계산해 결정하며, 데이터 수가 많은 클래스는 Positive Area 임계값을 0.6으로, 데이터 수가 적은 클래수는 0.4로 임계값을 설정한다.
Focal Loss의 가중치는 포인트필라의 기본값을 사용한다. 회귀의 경우, 속도 예측에만 loss weight를 0.2로 설정하고 나머지 변수는 0.1로 설정한다.
4. Results
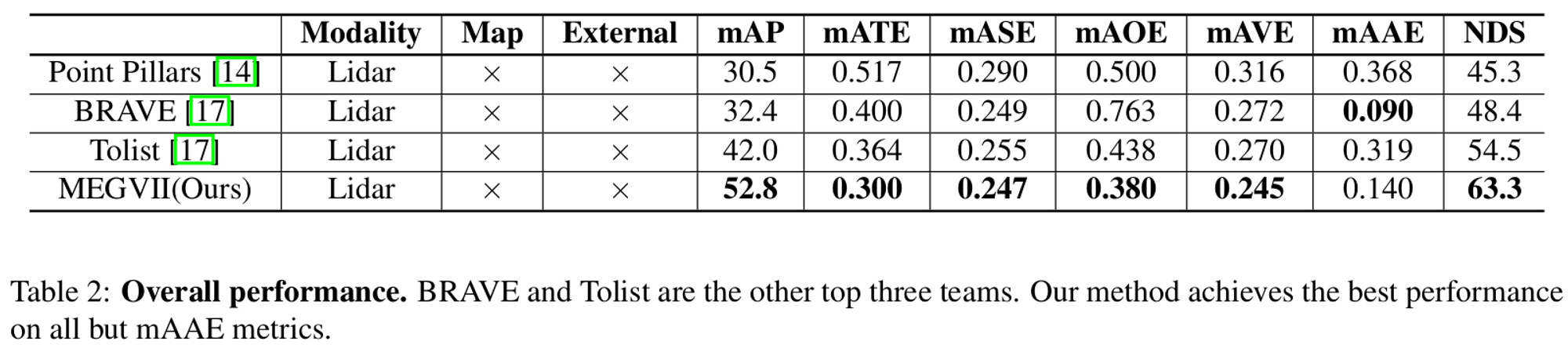
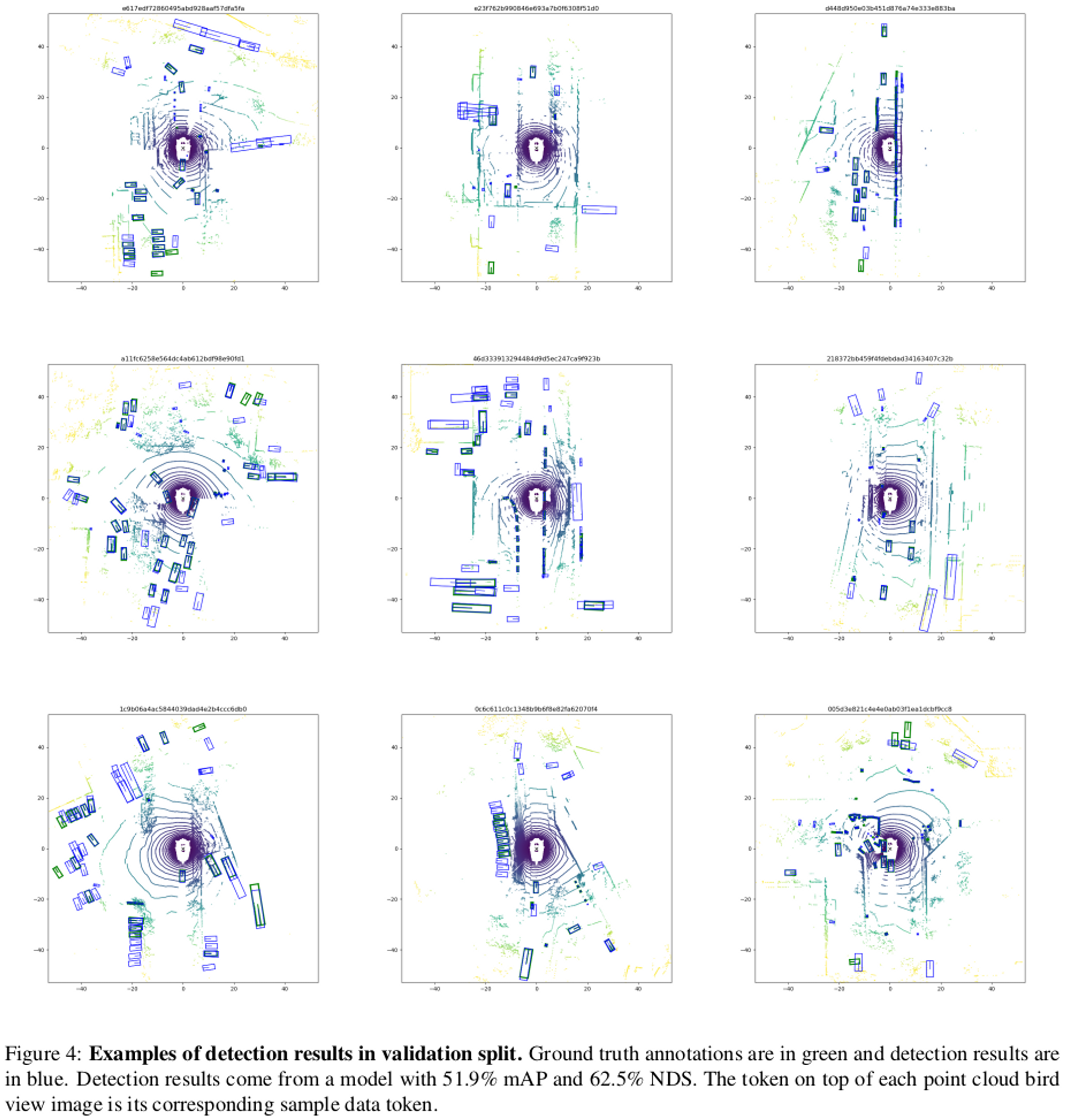
5. Conclusion
NS의 데이터 불균형 문제를 해결하기위해 여러 기법을 적용해 WAD 챌린지에서 최고의 성능을 얻었다. 코드를 공개해 다른 이들의 연구를 촉진시켰다.
