아파치 카프카 입문 1강 - Kafka 기본개념 및 생태계
본 내용은 https://youtu.be/VJKZvOASvUA 강의 내용임을 밝힙니다.
Aphache kafka 입문 1강
before Kafka
- end to end 연결방식의 아키텍쳐
- 데이터 연동의 복잡성 증가
- 각기 다른 데이터 파이프라인 연결구조
- 확장의 어려움
kafka란?
모든 시스템으로 실시간 처리가 가능하며
데이터가 갑자기 많아지더라도 확장이 용이한 시스템
링크드인 데이터 관련팀에서 개발함.
After kafka
- 프로듀서와 /컨슈머 분리
- 메시지 데이터를 여러 컨슈머에게 허용 : 데이터가 kafka 에 들어가면 여러번 사용가능하게 함.
- 높은 처리량을 위한 메시지 최적화
- 스케일 아웃 가능 (무중단 가능!)
kafka broker
- 실행된 카프카 애플리케이션 서버 중 1대
- 3대 이상의 브로커로 클러스터 구성
- 주키퍼와 연동: 주키퍼 역할은 메타데이터(브로커 id, 컨트롤러 id) 저장
- n개의 브로커 중 1대는 컨트롤러 기능 수행
- 컨트롤러: 각 브로커에게 담당 파티션 할당 수행, 브로커 정상 동작 모니터링 관리

Record
- 객체를 프로듀서에서 컨슈머로 전달하기 위해 kafka 내부에 byte 형태로 저장할 수있도록 직렬화/ 역직렬화하여 사용
- 기본 제공 직렬화 class : StringSerializer,shortSerializer 등
- 커스텀 직렬화 class 를 통해 Custom Object 직렬화/역직렬화 가능
- Key는 Null ,Value 는 JSON으로 된 자체 형식으로 사용 중
Partition

- 메시지 분류 단위
- n 개의 파티션 할당 가능
- 각 파티션마다 고유한 오프셋(offset)을 가짐
- 큐 형태이나, 여러개이므로, 메시지 처리순서는 파티션 별로 유지 관리됨.
Producer & Consumer
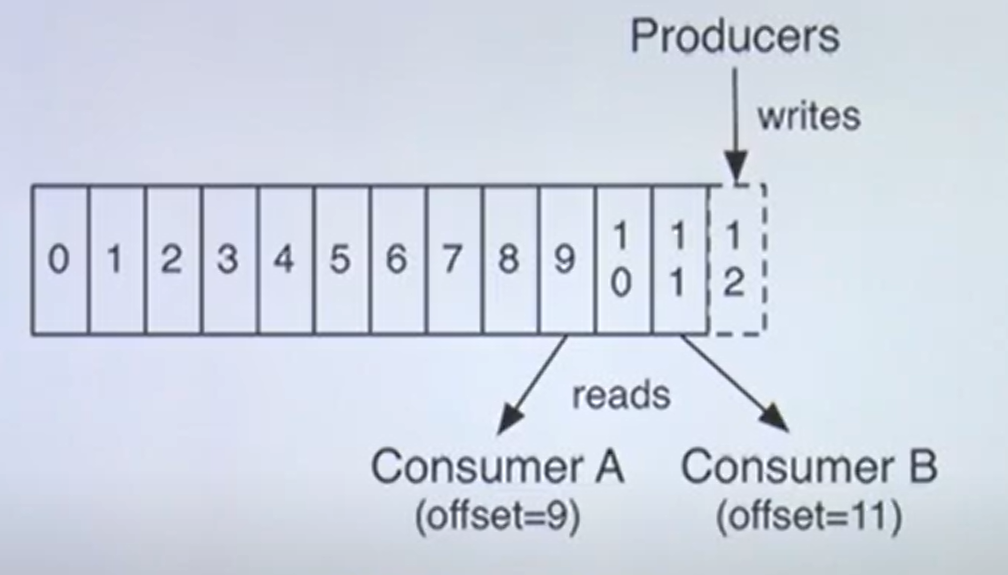
1. 프로듀서는 레코드를 생성하여 브로커로 전송
2. 전송된 레코드는 파티션에 신규 오프셋과 함께 기록됨
3. 컨슈머는 브로커로부터 레코드를 요청하여 가져감(polling)
(주의: 브로커가 컨슈머로 보내는게 아님!)
Kafka log and segment
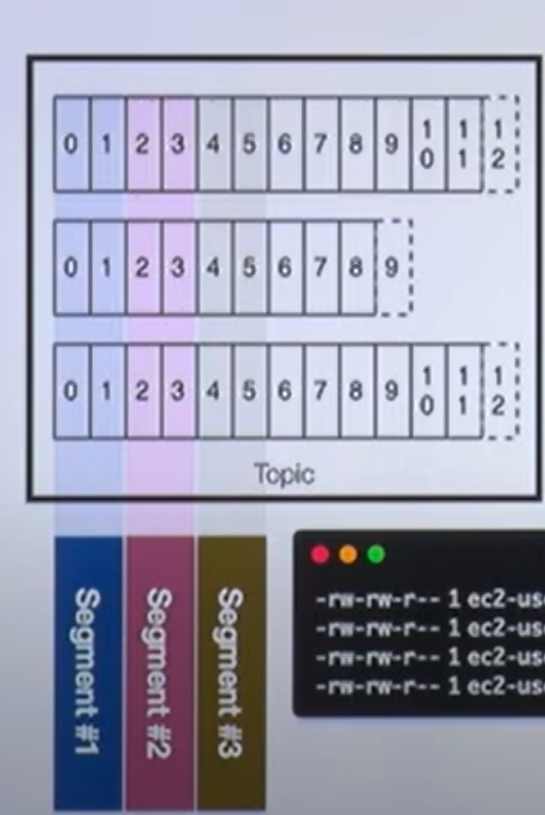
- 실제로 메시지가 저장되는 파일 시스템 단위
- 메시지가 저장될때는 세그먼트 파일이 열려있음
- 세그먼트는 시간 또는 크기 기준으로 닫힘
- 세그먼트가 닫힌 이후 일정 시간(또는 용량)에 따라 삭제(delete) 또는 압축(compact)
예시)
파티션이 3개인 토픽
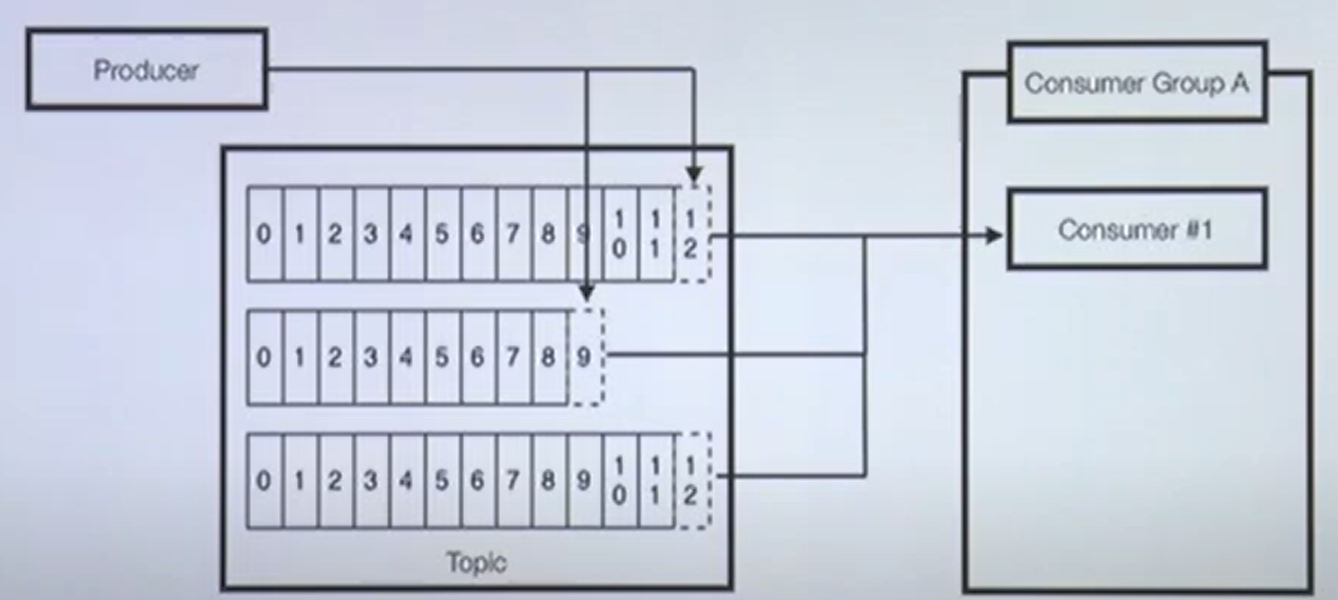
- 1개의 프로듀서가 토픽에 레코드를 보내는 중
- 1개의 컨슈머가 3개의 파티션으로 부터 polling 중
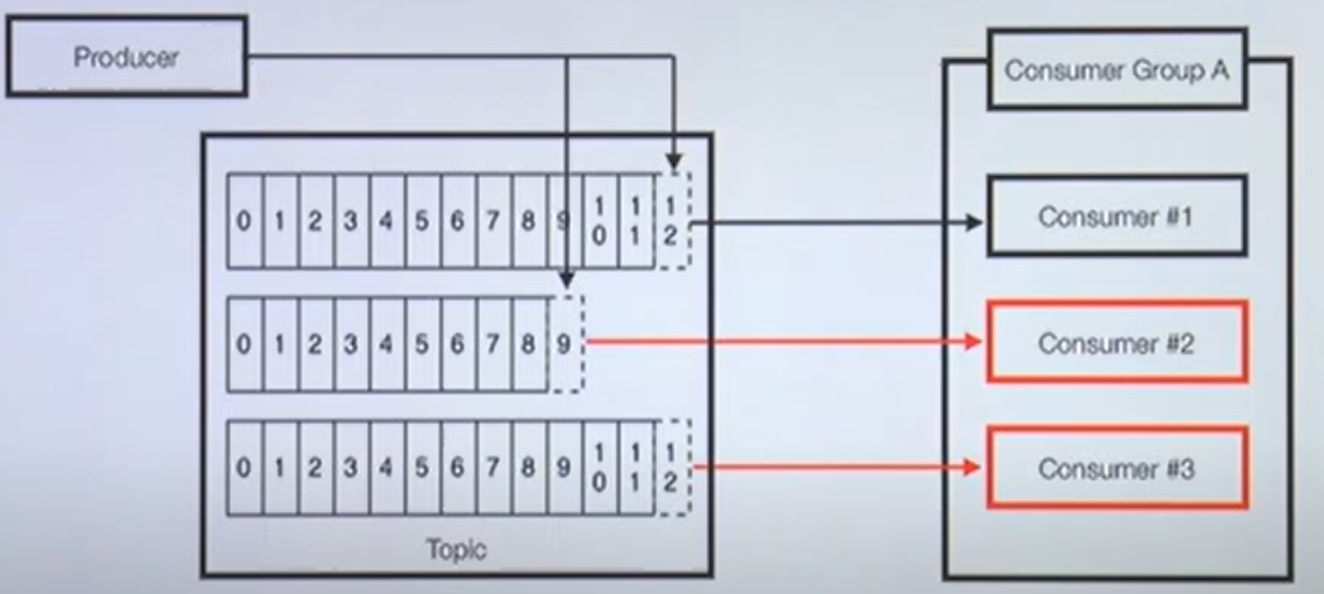
- 3개의 컨슈머로 이루어진 1개의 컨슈머 그룹이 토픽으로부터 polling 중
- 각각의 파티션에 컨슈머가 1개씩 할당된다. 1:1매칭
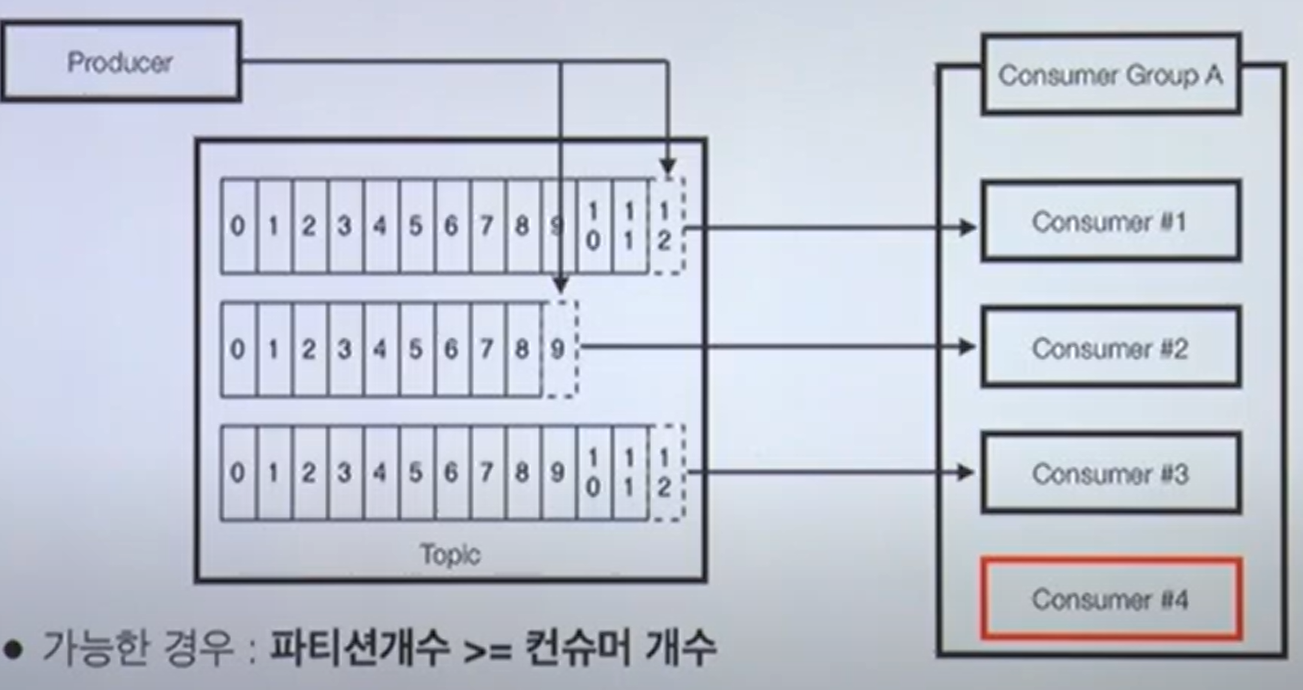
- 불가능: 파티션 개수 < 컨슈머 개수
- 남은 컨슈머는 파티션을 할당 받지 못하고 대기 중
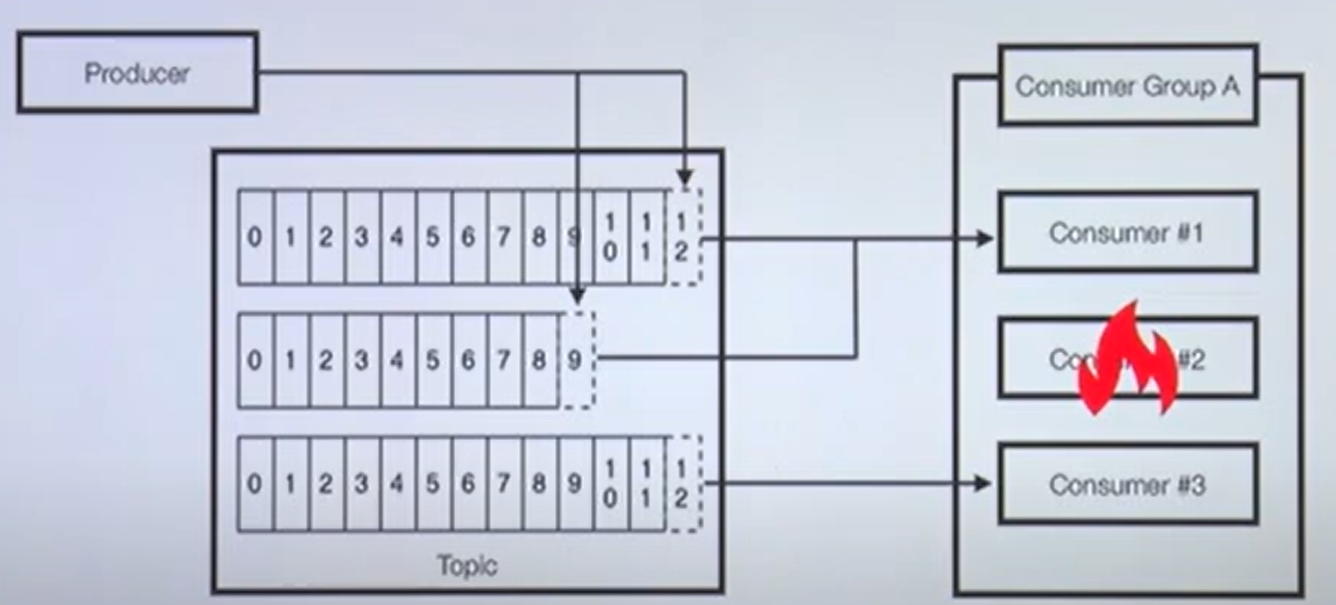
- 컨슈머중 한개가 장애가 난 경우에 대한 대비 가능
- 리밸런스 발생 : 파티션 컨슈머 할당 재조정
- 나머지 컨슈머가 파티션으로 부터 polling 수행
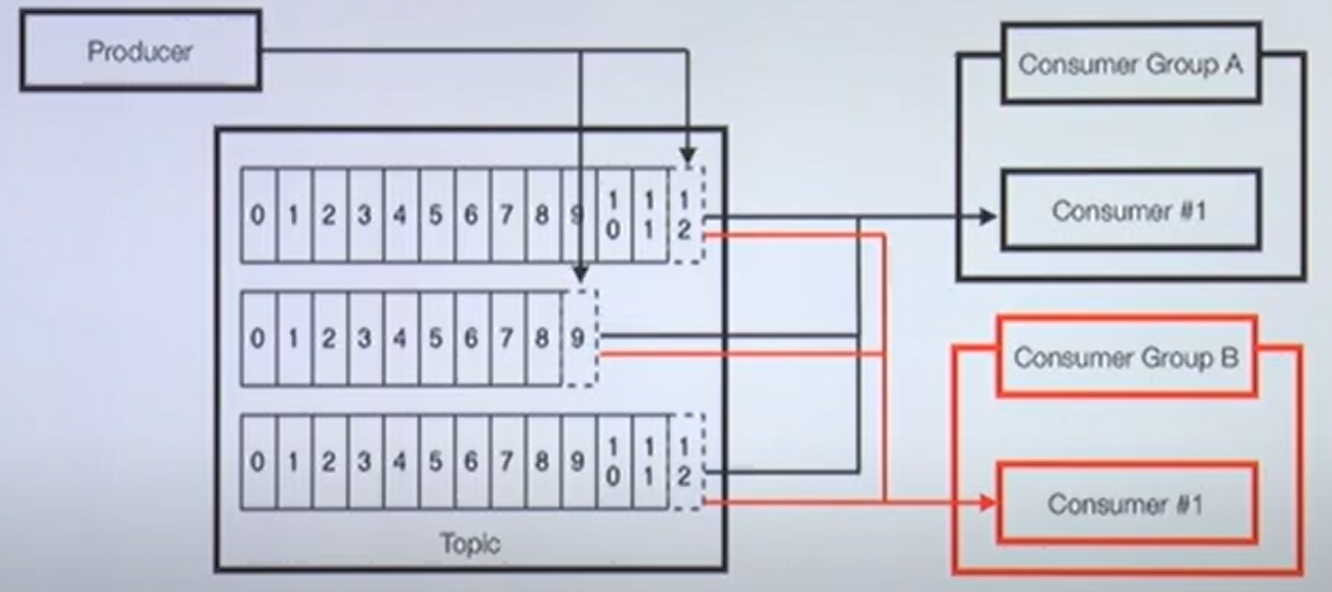
- 목적에 따른 컨슈머 그룹을 분리 할수있다. (consumer A 와 B 둘다 동시에 처리가능)
- 장애 대응하기 위해 재처리 목적으로 임시 신규 컨슈머 드룹을 생성하여 사용하기도 한다.
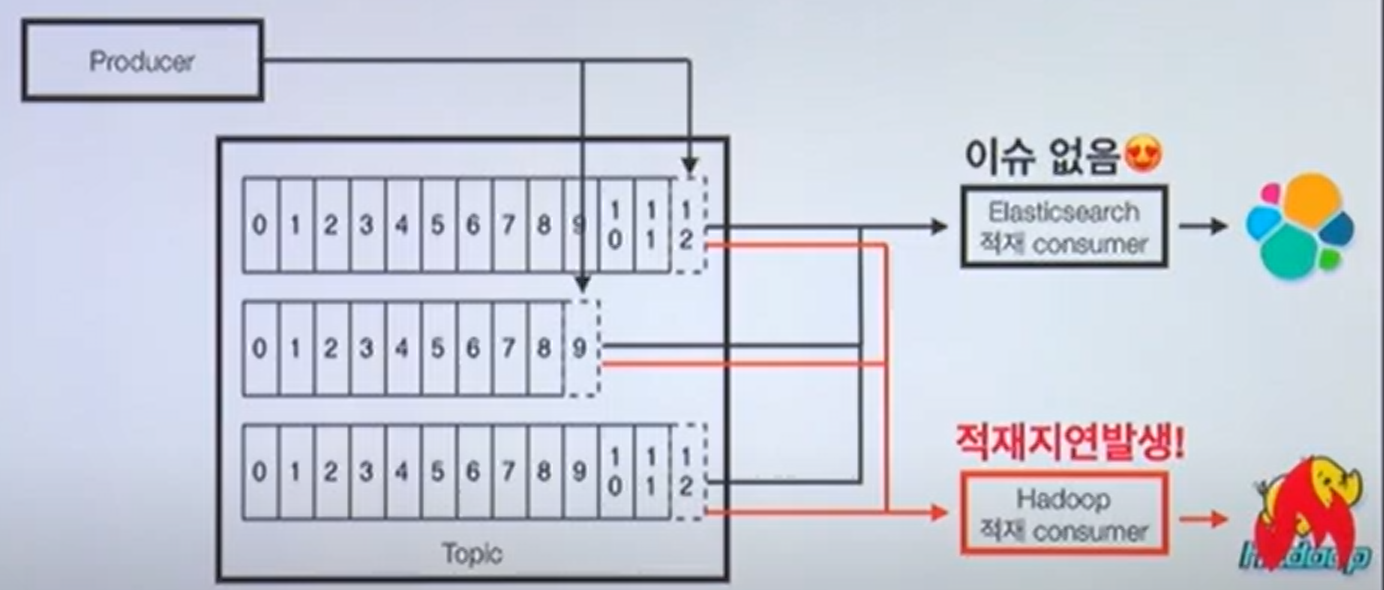
-컨슈머 그룹간 간섭(Coupling) 줄임
- 하둡에 이슈가 발생해 컨슈머의 적재 지연이 발생하더라도 엘라스틱서치에 적쟇라는 컨슈머 동작에는 이슈가 없음
- 하둡 장애시 엘라스틱서치에 적재하다가, 하둡 복구시 적재하던 중간 부터 하둡에 적재하면 된다.
->
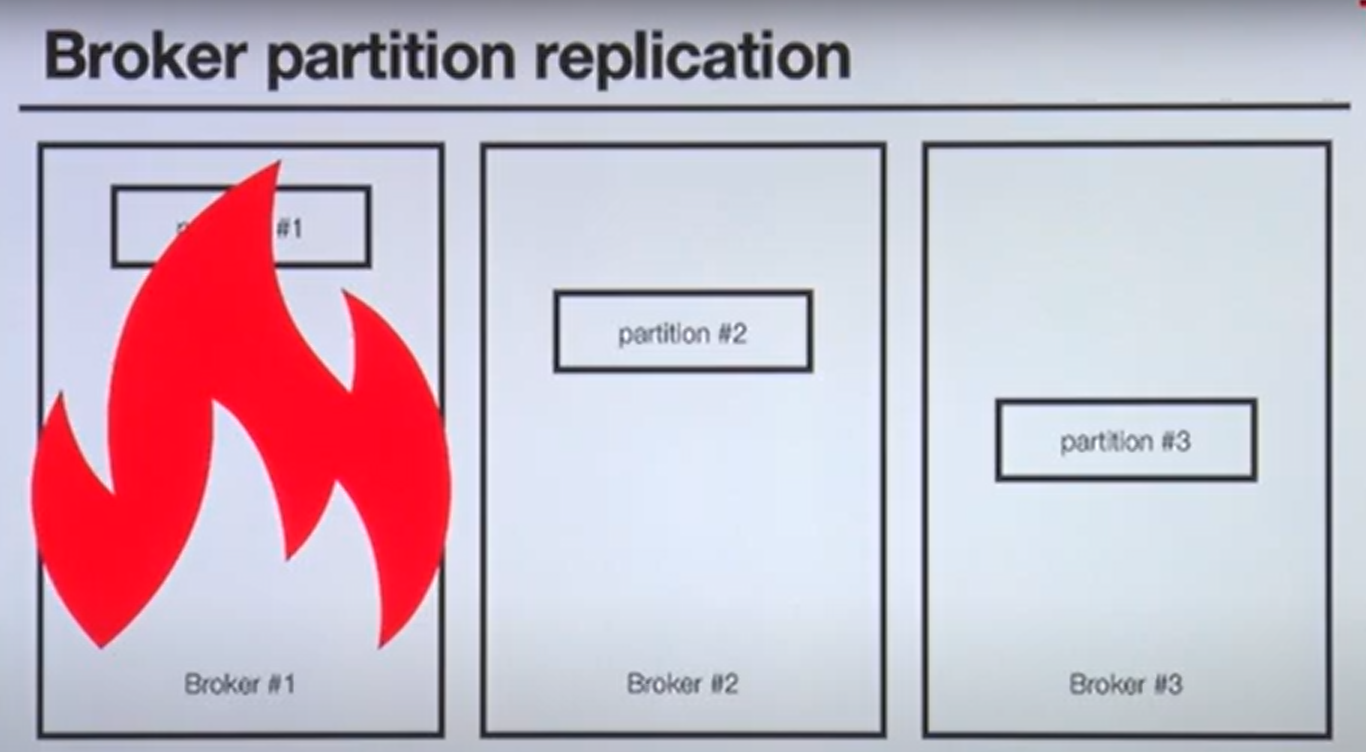
Q> Kafka broker 이슈에 대응하기위해 사용할수있는 방법은?
A> Partition 을 다른 Broker 에 복제하여 이슈에 대응한다.
1번 Broker 에 이슈가 생기면 다른 Broker에 복제된 데이터를 사용한다.

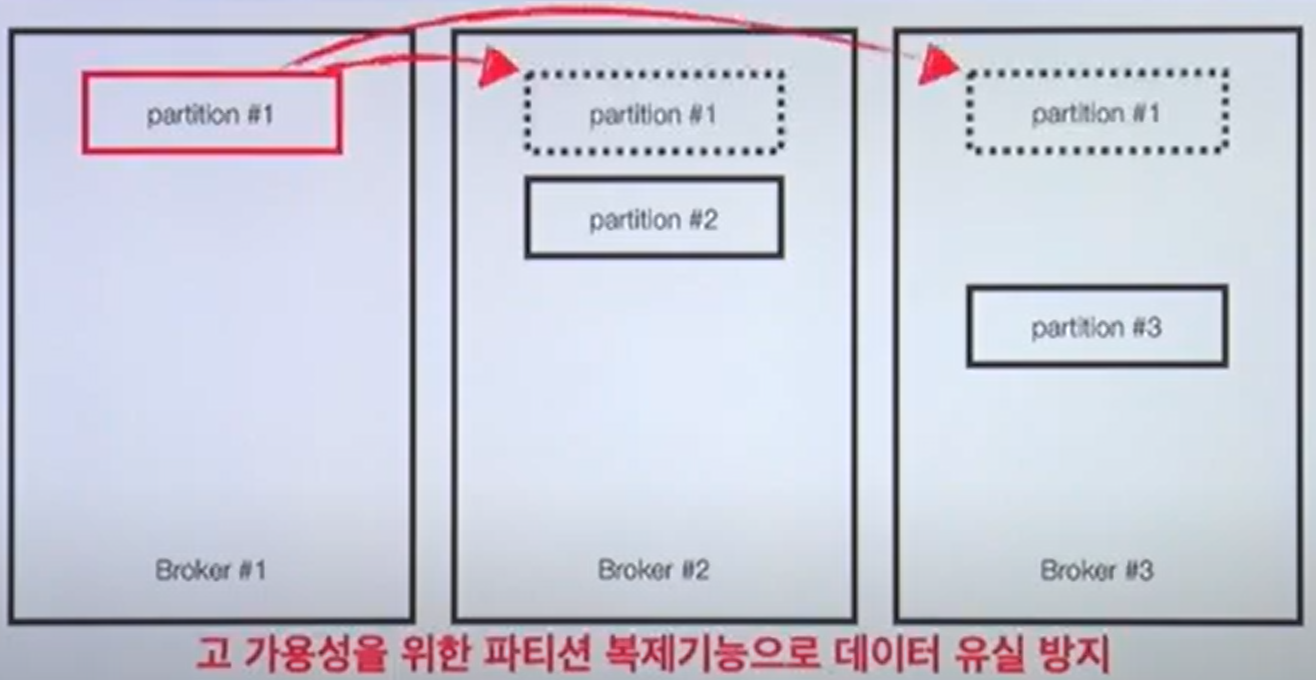
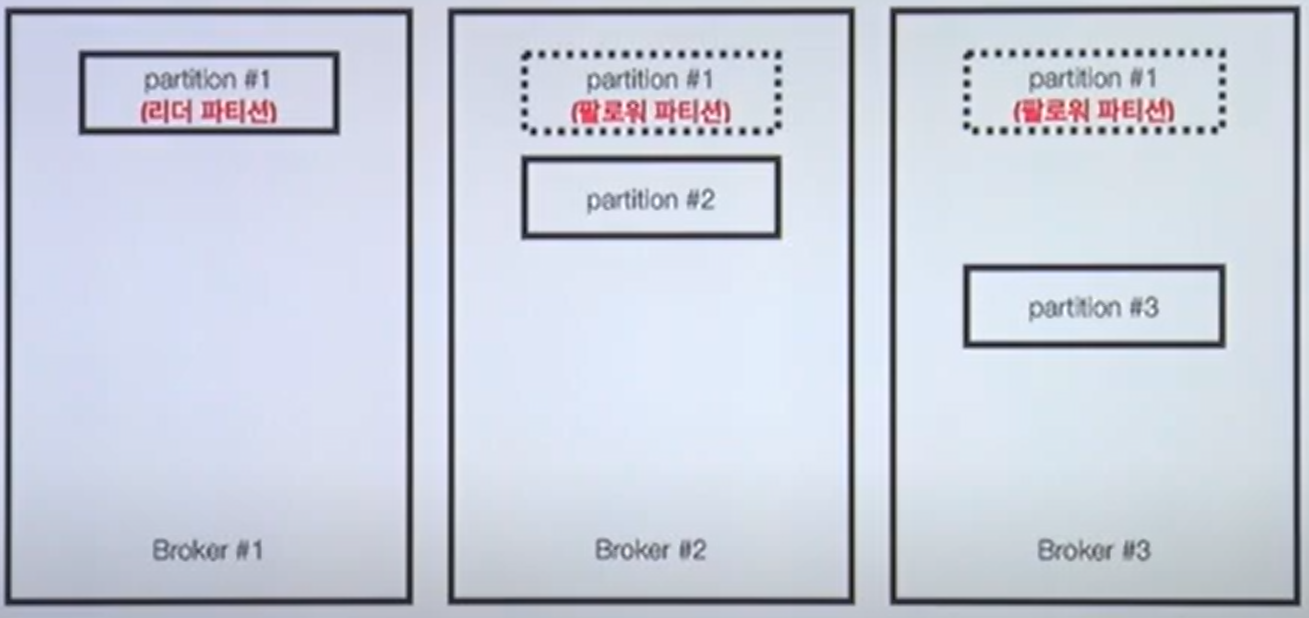
리더 파티션: Kafka 클라이언트와 데이터를 주고받는 역할
팔로워 파티션: 리더파티션으로부터 레코드를 지속 복제(복제하는데 시간걸림). 리더 파티션 동작이 불가능할경우 나머지 팔로워중 1개가 리더로 선출됨.
특정 파티션의 리더, 팔로워가 레코드가 모두 복제되어 sync가 맞는 상태
=> ISR(In-Sync Replica)
-ISR이 아닌 상태에서 장애가 나면
=> unclean.leader.election.enable
default는 false 인데, false면 장점: ISR이어도 리더만 보므로, 데이터가 유실안됨. / 단점: 리더가 복구될때까지 기다려야함.
true면 장애 안난 것중 leader를 선출해라
장점: 장애나도 리더가 있으므로, 컨슈머가 데이터 가져올수있음 / 단점: ISR이 아닌경우 데이터가 유실되어 있을 수있음.
KafKa 핵심요소 정리
- Broker: 카프카 애플리케이션 서버단위
- Topic : 데이터 분리단위, 다수 파티션 보유
- Partition : 레코드를 담고 있음, 컨슈머 요청시 레코드 전달
- Offset: 각 레코드당 파티션에 할당된 고유 번호
- Consumer : 레코드를 polling 하는 애플리케이션
- Consumer group : 다수 컨슈머 묶음- Consumer offset : 특정 컨슈머가 가져간 레코드의 번호
- Producer : 레코드를 브로커롤 전송하는 애플리케이션
- Replication : 파티션 복제 기능
- ISR :리더+ 팔로워 파티션의 sync가 된 묶음 - Rack-awareness :Server rack 이슈에 대응
Kafka Client

- Kafka 와 데이터를 주고 받기위해 사용하는 Java Library
- Producer,Consumer,Admin, Stream 등 Kafka 관련 API 제공
- 다양한 3rd Party library 존재
- Kafka broker 버전과 client 버전 하위호환 확인 필요
Kafka Streams

- 데이터를 변환 하기 위한 목적으로 사용하는 API
- 스트림 프로세싱을 지원하기 위한 다양한 기능 제공
- Stateful 또는 Stateless 와 같이 상태기반 스트림 처리 가능- Stream api 와 DSL(Domain Specific Language) 를 동시 지원
- Exactly-once 처리, 고가용성 특징
- kafka security(acl,sasl 등) 완벽 지원
- 스트림처리를 위한 별도 클러슽(ex) yarn 등) 불필요
Kafka Connect
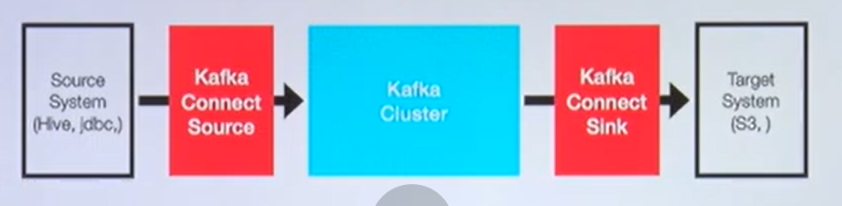
- kafka Client 로 kafka에 데이터를 넣는 코드를 작성할때도 있지만, Kafka Connect 를 통해 data 를 import/Export 할수있음
- 코드 없이 configuration 으로 데이터를 이동시키는 것이 목적
- Standalone mode, distribution mode지원- REST api interface를 통해 제어
- Stream 또는 Batch 형태로 데이터 전송 가능
- 커스텀 connector를 통한 다양한 plugin 제공(File,S3,Hive,Mysql etc..)
Kafka Mirror maker

- 특정 카프카 클러스터에서 다른 카프카 클러스터로 Topic 및 Record를 복제하는 Standalone tool
- 클러스터간 토픽에 대한 모든 것을 복제하는 것이 목적
- 신규 토픽, 파티션 감지기능 및 토픽설정 자동 Sync 기능- 양방향 클러스터 토픽 복제
- 미러링 모니터링을 위한 다양한 metric(latency, count등) 제공
kafka 생테계를 지탱하는 application들
- 일부 오픈소스의 경우 라이센스 이슈 확인 필요
- confluent/ksqlDB: sql 구문을 통한 stream data processing 지원
- confluent/ Schema Registry : avro기반의 스키마 저장소
- confluent/ REST Proxy :REST api를 통한 consumer/producer
- linkedin/Kafka burrow : consumer lag 수집 및 분석
- yahoo/CMAK : 카프카 클러스터 매니저
- uber/uReplocator :카프카 클러스터간 토픽 복제(전달)
- Spark Stream : 다양한 소스(카프카 포함)로 부터 실시간 데이터 처리
