1.CPU bound
CPU(중앙처리장치)는 기계어 명령어를 기반으로 계산을 수행하는 컴퓨터의 핵심 장치이다. 대부분의 컴퓨터 작업은 CPU를 사용하지만, CPU-bound 작업은 특히 CPU 자원을 집중적으로 사용하는 작업을 말한다. 예를 들어, 암호화나 압축과 같은 수학적 알고리즘 계산, 대량 데이터 집계 작업 등이 이에 해당한다.
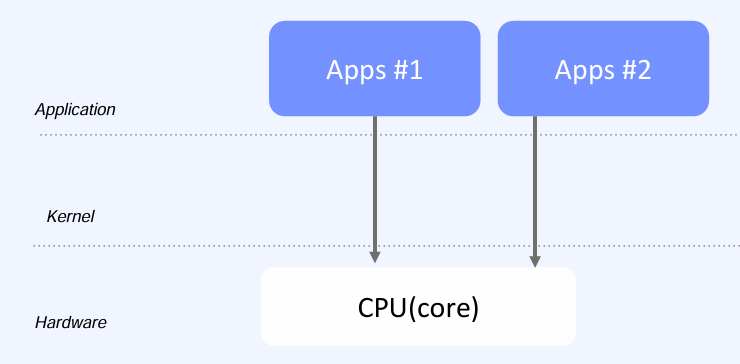
만약 하나의 CPU 코어로 두 개의 애플리케이션을 구동한다면 동시에 실행되는 것처럼 보이지만, 실제로는 한 번에 하나의 명령만 처리할 수 있다. 이로 인해 Context Switching이라는 과정이 발생하게 되며, 각 애플리케이션이 아주 짧은 시간 간격으로 번갈아 실행된다. 하지만 CPU-bound 작업에서는 이러한 빈번한 Context Switching이 성능 저하를 초래할 수 있다.
프로세스가 CPU에서 실행될 때 필요한 데이터는 CPU 레지스터에 저장되고, 이전에 진행된 명령어 정보와 캐시도 함께 저장된다. 같은 프로세스가 지속적으로 실행되어야 성능이 극대화되지만, Context Switching이 발생하면 CPU 레지스터가 초기화되면서 캐시 성능이 크게 저하되고 전체 오버헤드가 증가한다. 이러한 문제는 멀티코어 CPU를 통해 해결할 수 있다.
2.I/O bound
I/O(Input/Output)는 입출력 장치와 관련된 작업을 의미하며, 주요 예시로는 키보드 입력, 디스크 파일 복사, 네트워크를 통한 데이터 송수신 등이 있다. 어플리케이션 관점에서 클라이언트가 전달한 패킷을 네트워크 인터페이스 카드(NIC)를 통해 수신하고, 커널에서 네트워크 프로토콜 처리를 거쳐 패킷 수신이 완료될 때까지 CPU는 I/O 대기 상태에 놓인다. 이때 CPU는 일반적으로 블로킹 상태로 전환되어, 패킷 수신 완료까지 기다리게 된다.
웹 애플리케이션 서버의 경우, 클라이언트로부터 전달받은 HTTP 프로토콜을 처리하고 비즈니스 로직을 수행한 후 DB 쿼리 작업을 요청하는 등의 과정에서 I/O 작업이 빈번히 발생한다. 여기에는 데이터베이스의 디스크에서 데이터를 저장, 삭제, 조회하는 작업 등이 포함된다.
클라이언트의 많은 요청을 동시에 처리하는 방법
Thread: 프로세스 내에서 가장 작은 실행 단위로써 프로세스의 자원을 공유하며 경량화된 특징(생성과 종료가 빠름)을 가져 Context Switching 비용이 상대적으로 적어 동시성 처리에 최적화 되어있다.
클라이언트로부터 다수의 요청이 발생하여 동시에 I/O를 처리해야 할 경우, 전통적인 해결 방법은 웹 애플리케이션의 Thread 개수를 늘리는 것이다. 하지만 Thread가 많아지면 성능 면에서 CPU 컨텍스트 스위칭이 증가하며, 스레드가 무한히 증가할 경우 메모리가 부족해질 수 있다. 이러한 상황을 방지하기 위해 커널은 Out of Memory(OOM) 메커니즘을 통해 스레드를 종료시켜 시스템 다운을 예방한다.
또한, 요청마다 스레드를 생성하고 삭제하는 과정은 리소스를 많이 소모하므로, 스레드 풀(Thread Pool)을 활용하여 스레드를 공유하는 방법을 사용한다. 이 방법은 메모리 부족 문제를 자동으로 예방할 수 있으며, 리소스 사용을 최적화한다.
Spring MVC에서 기본 내장된 Tomcat 서버는 이러한 스레드 풀 기반으로 동작하여 효율적인 I/O 처리를 지원한다.
3.sync vs Async (작업의 순서)
3-1.Sync: 순차적인 작업의 실행을 말하며 일련의 작업들이 있다고 가정했을 때 먼저 요청한 작업이 완료될 때까지 기다렸다가 다음 명령을 순차적으로 실행하는 것을 의미한다.
3-2.Async: 요청한 작업의 종료를 기다리지 않고 다른 작업을 실행할 수 있는 흐름을 말한다. 이를 통해 요청한 쪽에서는 요청 결과와 무관하게 그다음 작업을 진행하는 것이 가능하다.(완료 순서는 보장되지 않음)
3-2-1.HTTP 요청을 통한 비동기 처리
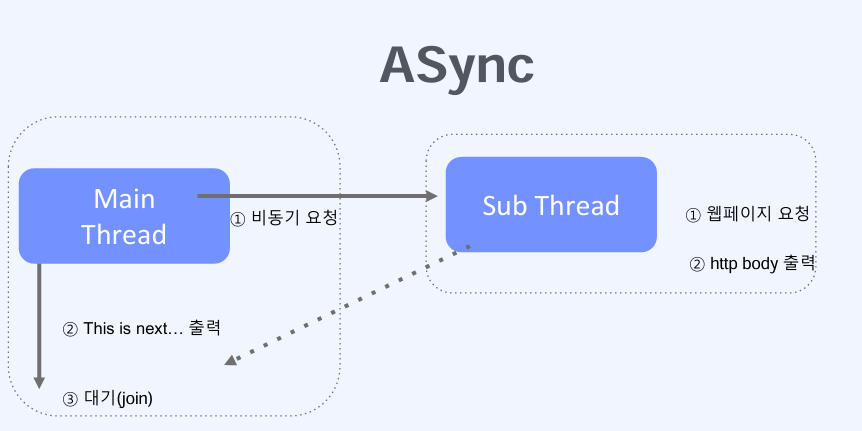
흐름도를 확인하면 서버에게 http 요청을 비동기로 보내면 accept() 메서드가 발동하기 전까지 join(메인 Thread의 종료를 대기)과 응답을 받으면 http body를 출력한다.
3-2-2.메시지 브로커(Kafka, RabbitMQ)를 통한 비동기 처리
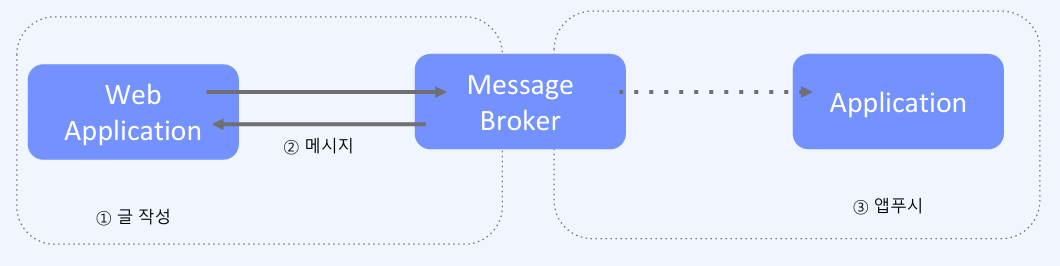
예를 들어, 알림을 팔로워들에게 전송할 때 전송자는 모든 메시지가 전달될 때까지 대기해야 하는 부담이 있다. 이때 메시지 브로커를 사용하면 생산자(전송자)와 소비자(알림 수신 시스템) 간의 처리 흐름을 분리하여, 전송자는 메시지 전송 후 즉시 다음 작업을 수행할 수 있고, 소비자는 큐에서 메시지를 순차적으로 받을수 있다.
4.Blocking vs Non-Blocking (작업의 상태)
주로 I/O 관련된 작업과 관련이 있고 대기를 하게 되면 Blocking, 대기를 하지 않고 바로 응답을 받게 되면 Non-Blocking이다.
4-1.Blocking: 예를들어 Socket으로 네트워크 데이터를 받을 때 실제 데이터가 올 때까지 accept() 메서드로 대기,디스크의 파일쓰기 I/O 작업에서 쓰기가 완료될 때까지 대기 등이 있다.
4-2.Non-Blocking: 일반적으로 클라이언트 요청당 Thread를 각각 생성되어 통신이 완료될때 까지 대기하게 되지만 Non-Blocking I/O 처리에서는 하나의 스레드가 여러 네트워크 요청을 번갈아 가며 처리할 수 있어 스레드 개수가 줄어들고 메모리 사용량이 줄어들어 자원이 더 효율적으로 사용된다.
5.I/O Multiplexing
Non-Blocking 방식에서 Polling 기반(반복된 I/O 요청 확인)으로 클라이언트의 요청을 반복적으로 확인하는 것은 I/O 자원을 낭비하고, 데이터가 없을 경우 불필요한 CPU 자원이 소모되는 단점이 있다. 이러한 문제를 해결하기 위해 커널이 I/O 요청 결과(새로운 클라이언트 연결 요청, 데이터 수신 등)를 이벤트 단위로 알려주는 I/O Multiplexing 방식이 사용된다. 이 방식에서는 다수의 소켓에 이벤트 등록이 가능하여, 하나의 스레드로 여러 I/O 작업을 효율적으로 처리할 수 있다.
동작 순서: 이벤트 등록 -> 대기 상태로 전환 -> 이벤트 발생 시 커널이 알림
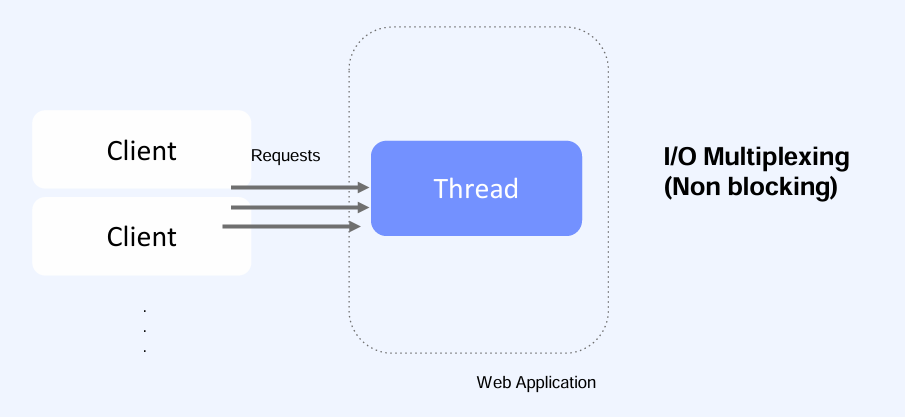
대량의 트래픽이 들어오는 상황에서 I/O Multiplexing을 사용하면 적은 thread로 많은 클라이언트 요청을 효과적으로 대응할수 있다. 일반적으로 연결을 담당하는 Thread와 비지니스 로직을 처리하는 Worker Thread가 있다.
