Cache란?
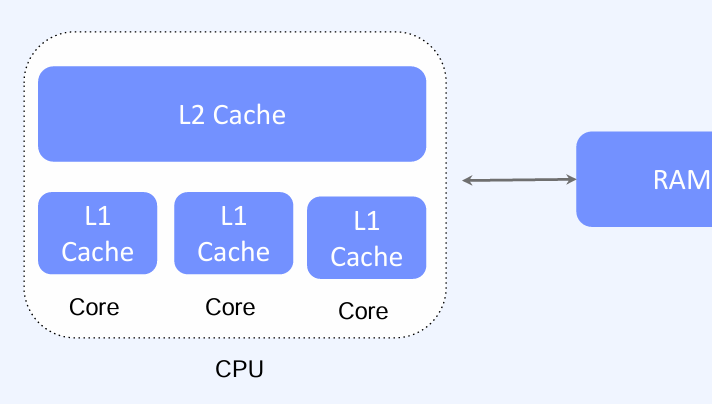
캐시는 데이터를 일시적으로 저장하는 고속 처리를 위한 임시 저장소이다. 원본 데이터에 접근하는 것보다 더 빠른 응답 속도로 데이터를 제공할 수 있어야 한다. 캐시는 다양한 용도로 활용되며, 대표적으로 CPU에서 사용한다. CPU는 연산을 위해 메인 메모리의 데이터를 빈번하게 읽고 쓰는데, CPU와 메인 메모리 간 속도 차이가 크기 때문에 CPU는 가까운 곳에 캐시를 두어 데이터를 임시로 저장하고 빠르게 연산을 진행한다. 일반적으로 CPU에는 각 코어별로 L1 Cache가 있고, 각 코어가 공유하는 L2 Cache가 있다.
웹 애플리케이션에서도 캐시는 데이터베이스의 부담을 줄이기 위해 사용된다. 데이터베이스에 부하를 주는 무거운 쿼리나, 변경이 적고 접근 빈도가 높은 데이터를 캐시 서버에 저장하여 빠르게 처리할 수 있다. 데이터베이스뿐만 아니라, 외부 API 요청에 대해서도 변경이 적고 접근 빈도가 높은 경우 캐시에 저장하여 활용할 수 있다.
Cache 용어
- Cache Hit: 캐시 서버에 요청을 보냈을 때, 해당 데이터가 이미 캐시에 있어 바로 응답하는 경우
- Cache Miss: 캐시에서 데이터를 찾지 못해, 원본 데이터베이스나 외부 API에 접근해야 하는 경우
Cache Hit 비율이 낮다면 임시 저장소를 따로 관리하는게 오히려 비용만 증가하고 효과가 없다.
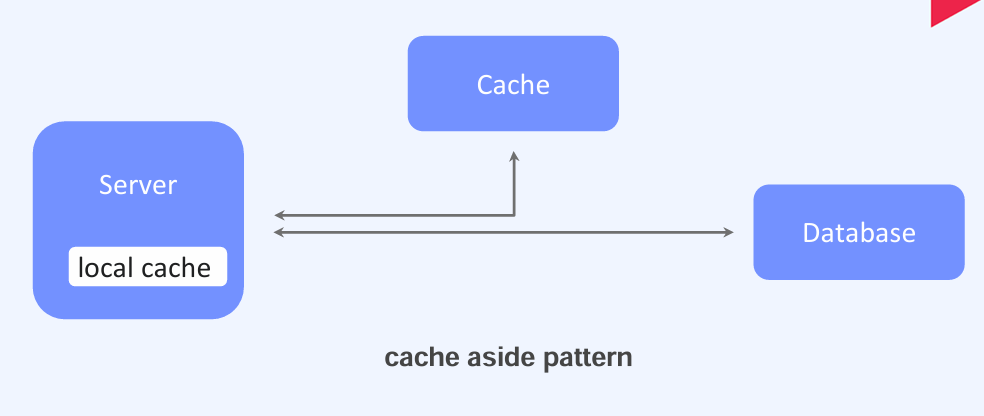
Cache Pattern
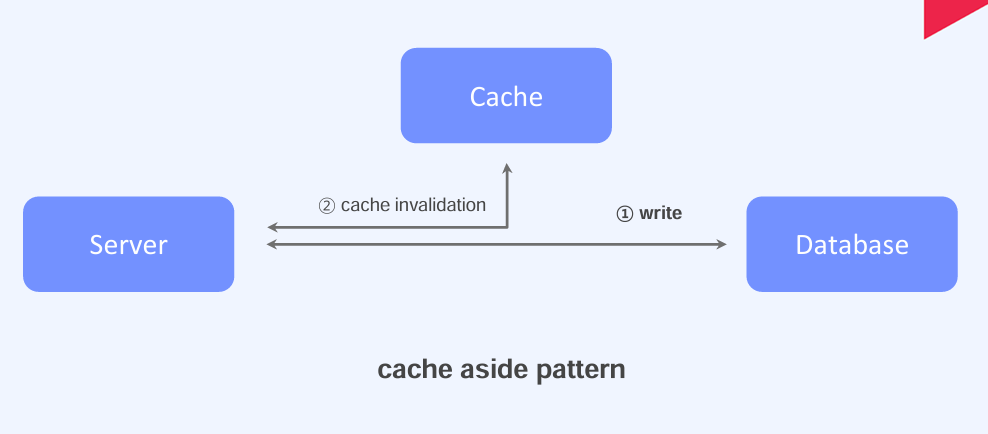
- Cache aside pattern: 데이터를 캐시에 저장할 때 TTL(Time-To-Live)을 설정하여 특정 시간 동안만 임시 저장한다. 이는 캐시 메모리가 부족할 수 있는 상황에 대비한 것이다. 또한, 원본 데이터베이스의 데이터가 변경된 경우 캐시의 데이터가 오래된 정보일 수 있기 때문에, 적절한 TTL 값을 설정하는 것이 중요하다. 데이터베이스에 쓰기 작업을 할 때는 Cache Invalidation (캐시 무효화)를 사용하여 일관성을 유지하는 전략을 함께 사용한다.
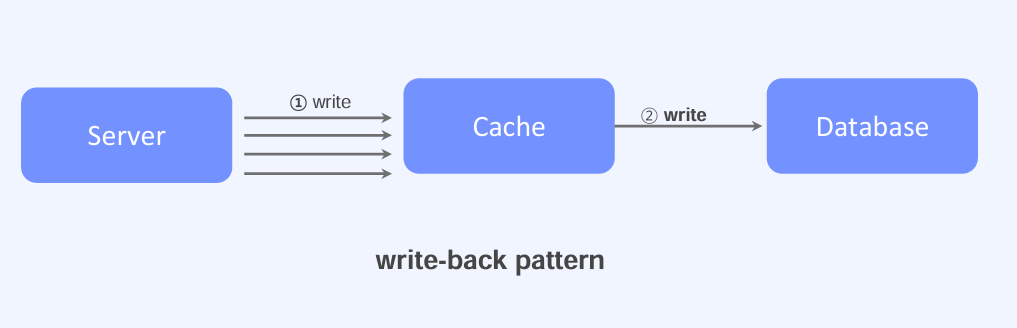
- Write-back pattern: 버에서 쓰기 작업을 데이터베이스가 아닌 캐시에 먼저 진행한다. 다수의 쓰기 작업이 캐시에 모이면, 이를 데이터베이스에 일괄적으로 적용한다. 쓰기 작업이 많은 경우 데이터베이스의 부하를 줄이고 클라이언트에게 빠른 응답을 제공할 수 있다. 그러나, 가용성 설정에 따라 캐시 데이터가 유실될 가능성이 있고, 복잡도가 높은 데이터의 경우 Write-Back 패턴을 구현하기 어려울 수 있다.
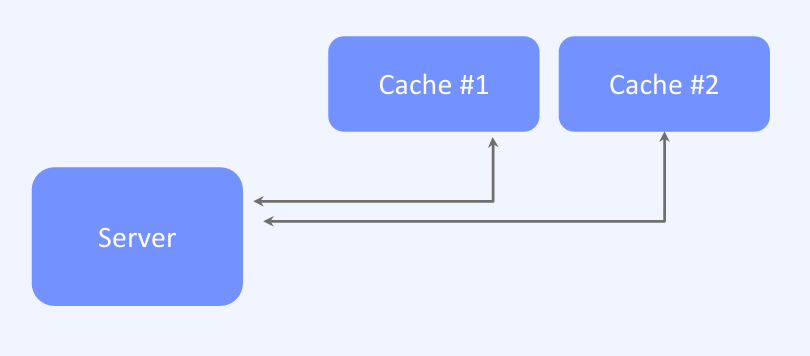
- local-distributed cache: 로컬 캐시와 분산 캐시를 함께 운영하는 경우이다. 어플리케이션 서버에서 메모리를 로컬 캐시로 사용하고, 별도의 서버에서는 분산 캐시(Redis)를 운용한다. 대규모 E-Commerce 서비스를 운영할 때 2단계 캐시를 사용하는 경우가 많다. 이는 Cache Aside Pattern과 유사한 전략으로, 데이터베이스로부터 1차적으로 Redis에 데이터를 저장하고, 각 어플리케이션 서버는 분산 캐시에서 가져온 데이터를 로컬 캐시에 저장하여 활용한다.
- Microservices Architecture (MSA): 도메인별로 여러 개의 캐시 서버를 나누어 운영하는 방식이다. 데이터 특성에 따라 캐시 서버를 적절히 분산하여 효율성을 극대화한다. 각 마이크로서비스가 독립적으로 캐시를 운용하여 성능을 최적화할 수 있다.