
2.8 count
스트림의 총 요소 수를 계산하여 방출한다. Flux의 모든 요소를 읽은 후에 Mono<Long>으로 요소의 개수를 반환한다.
public Mono<Long> fluxCount() {
return Flux.range(1, 10)
.count()
.log();
}2.9 distinct
중복된 요소를 제거하고 고유한 요소만 방출한다.
public Flux<String> fluxDistinct() {
return Flux.fromIterable(List.of("a", "b", "a", "b", "c"))
.distinct();
}
2.10 reduce
스트림의 요소들을 축소하여 하나의 값으로 결합한다. 초기값과 함께 누적 함수가 적용된다.
// reduce 람다 함수는 i,j 2개의 파라미터로 1+2=3 결합후
// 다음 요소로 3+3=6 ... 이런 방식으로 결합한다.
public Mono<Integer> fluxReduce() {
return Flux.range(1,10)
.reduce((i, j) -> i+j)
.log();
}
2.11 groupBy
요소를 주어진 기준에 따라 그룹화하여 각각의 그룹을 개별 GroupedFlux로 방출한다. 각 그룹은 고유한 키와 그 키에 해당하는 요소들의 Flux로 구성된다.
// even과 odd로 그룹을 구성하고 각 key에 대해 비동기적 flatMap과
// 누적 함수인 reduce를 적용하여 출력
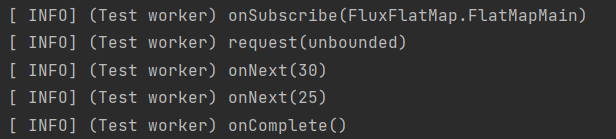
public Flux<Integer> fluxGroupBy() {
return Flux.range(1,10)
.groupBy(i -> (i % 2 == 0) ? "even" : "odd")
.flatMap(group -> group.reduce((i, j) -> i+j))
.log();
}
2.12 delaySequence / limitRate
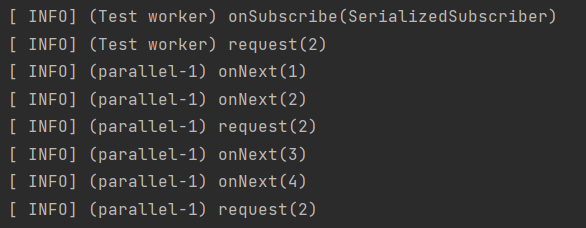
delaySequence는 전체 시퀀스의 방출을 특정 시간만큼 지연시킨다. 각 요소가 개별적으로 지연되는 것이 아니라 스트림 전체가 지정된 시간 후에 시작된다. limitRate는 데이터를 요청할 때의 속도를 제한하여 백프레셔(Backpressure) 를 처리한다. 특정 요소 수만큼 요청하도록 하여 생산자와 소비자 간의 데이터 흐름 속도를 조절할 수 있다.
Backpressure: 리액티브 스트림에서 구독자(Subscriber)가 발행자(Publisher)에게 처리할 수 있는 데이터의 양을 알려주어 데이터의 가용성을 보장하는 메커니즘
public Flux<Integer> fluxDelayAndLimit() {
return Flux.range(1, 10)
.delaySequence(Duration.ofSeconds(1))
.log()
.limitRate(2);
}
2.13 sample
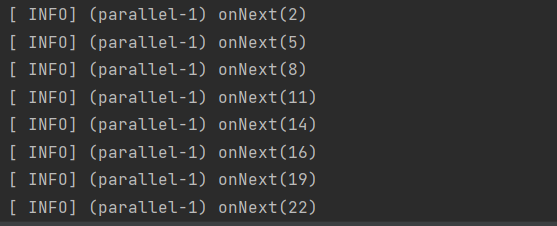
지정된 주기마다 마지막으로 방출된 요소만 방출한다. 일정 시간 동안 들어온 요소들 중 마지막 요소만을 선택하여 방출한다.
// 각 요소를 0.1초씩 딜레이 시켜
// 0.3초마다 마지막 요소를 출력한다. (ex.2 5 8 11 14)
public Flux<Integer> fluxSample() {
return Flux.range(1,100)
.delayElements(Duration.ofMillis(100))
.sample(Duration.ofMillis(300))
.log();
}
3.Scheduler
리액터(Reactor) 라이브러리에서 비동기 작업을 처리할 때 사용할 스케줄러를 지정하는 데 사용된다. 스케줄러는 작업이 어떤 스레드에서 실행될지를 결정한다.
3-1. immediate()
현재 호출 스레드에서 즉시 작업을 실행하는 스케줄러이다. 별도의 스레드가 생성되지 않고 호출된 스레드에서 작업이 수행된다.
오버헤드가 거의 없으며, 작업이 호출된 스레드에서 바로 실행되고 단일 스레드에서 실행되는 작업에 적합하다.
public Mono<String> Monoimmediate(){
return Mono.just("Hello")
.subscribeOn(Schedulers.immediate())
.log();
}3-2. single()
단일 스레드에서 실행되는 스케줄러이다. 모든 작업이 동일한 스레드에서 순차적으로 실행된다.
public Flux<Integer> FluxSingle(){
return Flux.range(1,10)
.subscribeOn(Schedulers.single())
.log();
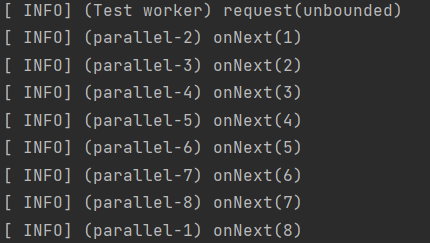
}3-3. parallel()
CPU 코어 수를 기준으로 병렬로 작업을 실행하는 스케줄러이다. 다중 스레드로 병렬 처리를 수행하여 높은 처리량을 제공한다.
public Flux<Integer> FluxMulty(){
return Flux.range(1,10)
.subscribeOn(Schedulers.parallel())
.delayElements(Duration.ofMillis(300))
.log();
}
3-4. boundedElastic()
기본적으로 제한된 크기의 스레드 풀을 사용하지만, 필요에 따라 풀의 크기를 늘려서 더 많은 작업을 처리할 수 있다. 이는 대기 시간이 긴 블로킹 작업을 처리할 때 효율적으로 사용된다.
public Flux<Integer> fluxMapWithSubscribeOn() {
return Flux.range(1, 10)
.map(i -> i * 2)
.subscribeOn(Schedulers.boundedElastic())
.log();
}