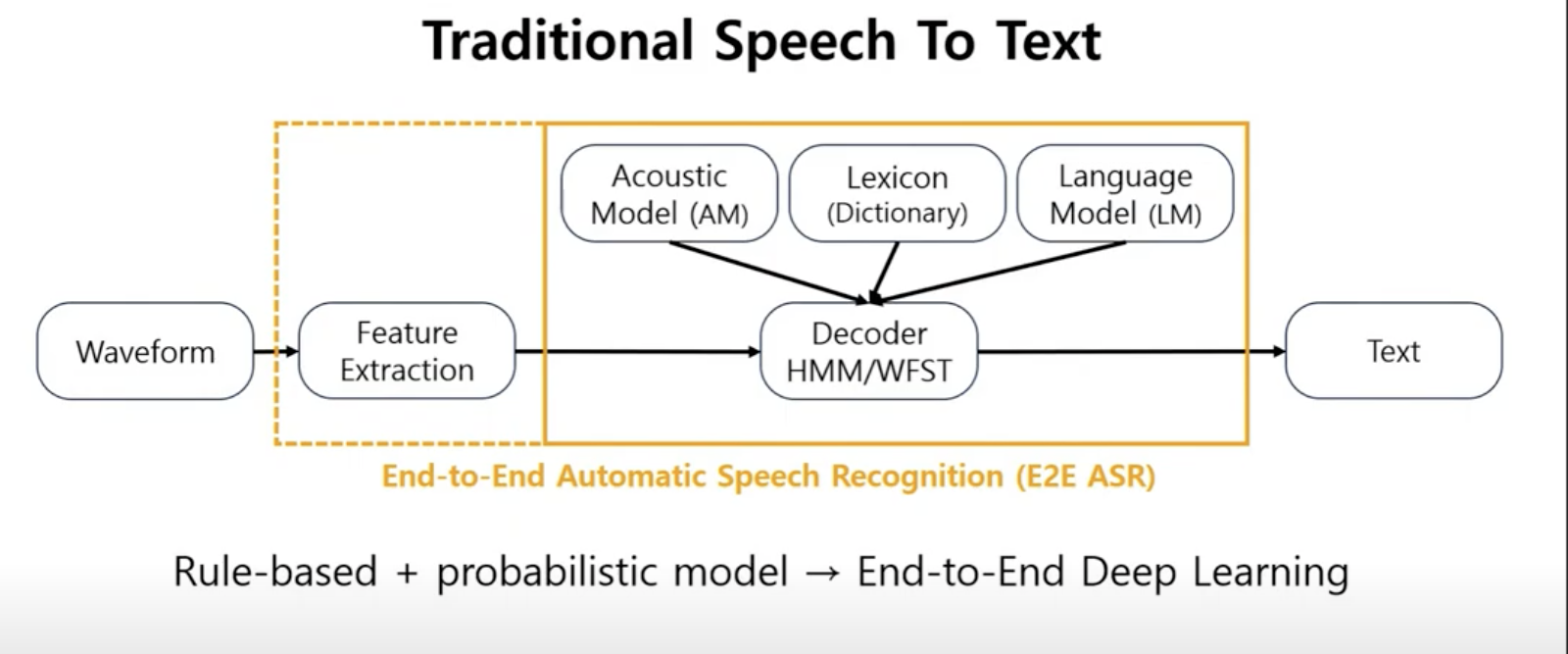
conventional ASR vs E2E ASR
기존 acoustic 모델은 waveform에서 feature extraction후
AM(acoustic model), PM(pronunciation model), LM(language model)을 이용해서 Text를 만드는 방식이었다. 이때 AM, PM, LM은 분리되어서 따로 학습된다.
E2E모델은 이와 다르게 acoustic feature를 입력 받아 바로 text로 변환하는 모델이다.
E2E 모델일지라도 여전히 필요한 것이 존재한다.
1. Feature Extraction
2. (external) Beam search Decoder
3. (external) Language model
모델 구조
총 5개의 layers로 구성되어 있다.
3개의 linear layers, bidirectional_rnn, 2개의 linear layers로 되어있다.
모델의 input은 spectrogram을 사용했고
loss는 CTCLoss를 사용했다.
(CTCLoss는 직접 구현할 필요없이 nn.CTCLoss를 사용하면 된다.)
앞에 3개의 layers는 다음과 같다.
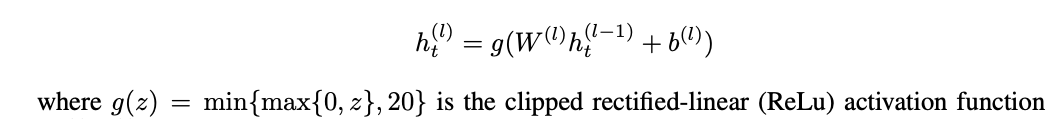
nn.functional.hardtanh를 이용하면 clipped function을 구현할 수 있다.
논문에서 4번째 layer는 bidirectional rnn을 사용했다.
더 많은 연산과 메모리가 필요하기 때문에 LSTM을 사용하지 않았다고 논문에 쓰여있지만 https://github.com/mozilla/DeepSpeech 에 나와있는 최근 버전 코드를 보면 전부 LSTM을 사용했다.
(4번째 layer를 rnn으로 만들어서 학습을 시켜보니 rnn의 고질적인 문제인 gradient vanishing 때문에 learning rate을 상당히 작게 주어야 학습이 되었고 따라서 학습 시간이 오래걸렸다. 하지만 lstm으로 바꾸니 rnn보다 훨씬 안정적이었다.)
5번째 layer는 forward units과 backward units을 합친 값을 input으로 받는 linear layer다.
6번째 linear layer를 통과한 후 softmax를 적용해 각 문자의 확률 분포를 얻는다.
아래는 논문에 적혀있는 5, 6 번째 layer에 대한 설명이다.
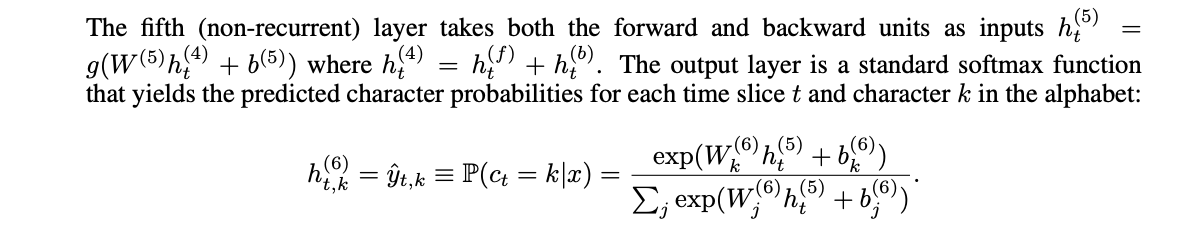
linear layer에는 Regularization을 위해 dropout rate을 5%~10% 사이 값을 줬고, rnn에는 적용하지 않았다.
모델 pytorch 구현
class FullyConnected(torch.nn.Module):
"""
Args:
n_feature: Number of input features
n_hidden: Internal hidden unit size.
"""
def __init__(self,
n_feature: int,
n_hidden: int,
dropout: float,
relu_max_clip: int = 20) -> None:
super(FullyConnected, self).__init__()
self.fc = torch.nn.Linear(n_feature, n_hidden, bias=True)
self.relu_max_clip = relu_max_clip
self.dropout = dropout
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.fc(x)
x = torch.nn.functional.relu(x)
x = torch.nn.functional.hardtanh(x, 0, self.relu_max_clip)
if self.dropout:
x = torch.nn.functional.dropout(x, self.dropout, self.training)
return x
class DeepSpeech(torch.nn.Module):
"""
DeepSpeech model architecture from *Deep Speech: Scaling up end-to-end speech recognition*
[:footcite:`hannun2014deep`].
Args:
n_feature: Number of input features
n_hidden: Internal hidden unit size.
n_class: Number of output classes
"""
def __init__(
self,
n_feature: int,
n_hidden: int = 2048,
n_class: int = 40,
dropout: float = 0.0,
) -> None:
super(DeepSpeech, self).__init__()
self.n_hidden = n_hidden
self.fc1 = FullyConnected(n_feature, n_hidden, dropout)
self.fc2 = FullyConnected(n_hidden, n_hidden, dropout)
self.fc3 = FullyConnected(n_hidden, n_hidden, dropout)
self.bi_rnn = torch.nn.RNN(
n_hidden, n_hidden, num_layers=1, nonlinearity="relu", bidirectional=True
)
self.fc4 = FullyConnected(n_hidden, n_hidden, dropout)
self.out = torch.nn.Linear(n_hidden, n_class)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
Args:
x (torch.Tensor): Tensor of dimension (batch, channel, time, feature).
Returns:
Tensor: Predictor tensor of dimension (batch, time, class).
"""
# N x C x T x F
x = self.fc1(x)
# N x C x T x H
x = self.fc2(x)
# N x C x T x H
x = self.fc3(x)
# N x C x T x H
x = x.squeeze(1)
# N x T x H
x = x.transpose(0, 1)
# T x N x H
x, _ = self.bi_rnn(x)
# The fifth (non-recurrent) layer takes both the forward and backward units as inputs
x = x[:, :, :self.n_hidden] + x[:, :, self.n_hidden:]
# T x N x H
x = self.fc4(x)
# T x N x H
x = self.out(x)
# T x N x n_class
x = x.permute(1, 0, 2)
# N x T x n_class
x = torch.nn.functional.log_softmax(x, dim=2)
# N x T x n_class
return x
출저 - https://pytorch.org/audio/stable/_modules/torchaudio/models/deepspeech.html
2.2 Language Model
3. Optimization
생략
4.1 Synthesis by superposition
training data를 늘리기 위해서 data synthesis를 사용했다.
특히 noisy enviroments에서 성능을 향상시키기 위해서
noisy speech = audio + noise
이러한 방식으로 데이터를 생성했다.
이때 주의할 점은 1000시간 clean speech를 가지고 1000시간 noisy speech를 만들려면 충분한 양의 noise tracks이 필요하다. 적당히 10시간 정도의 noise track을 반복해서 noisy speech를 만든다면 모델이 noise를 기억해서 합성된 데이터에서 이를 뺄수도 있기 때문이다.
따라서 하나의 single noise source를 이용하는 대신에 shorter clips를 여러개 사용해서 superimposing하는 방식을 사용했다.
4.2 Capturing Lombard Effect
noisy environments에서 ASR 모델을 학습시킬 때 "Lombard Effect"가 문제가 된다. speaker는 noise 환경에서 소리를 잘 전달하기 위해서 의도적으로 목소리를 키우게 된다. 조용한 환경에서 얻은 데이터셋에는 이러한 특징을 찾을 수 없다. Lombard effect를 training data에 적용하기 위해서 사람들의 목소리를 녹음할 때 의도적으로 noisy환경을 만들어서 녹음해서 이를 training set으로 사용했다.
