ERD는 봐도봐도 헷갈리는 존재다
이번에 정리를 해놓는게 좋을 것같다
현재 re:code의 통계부분 ERD이다.
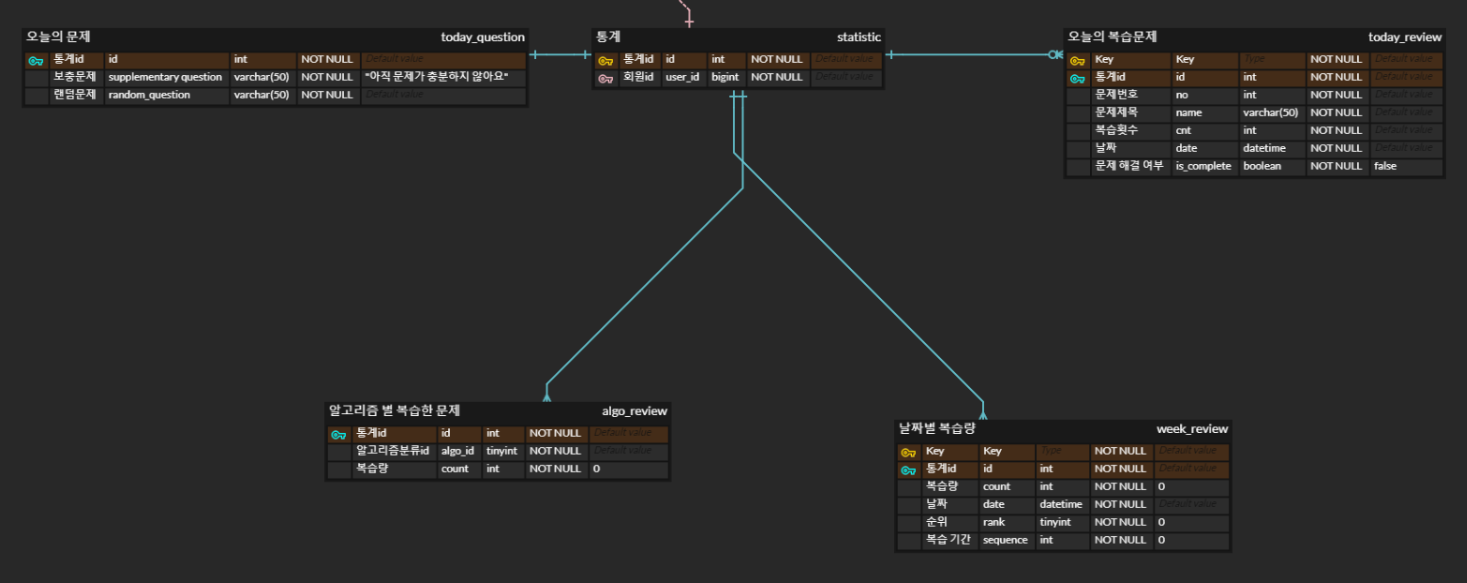
- 간단하게 명사로 표현가능한 엔티티(테이블) 만들기
- 1,2,3, 정규형 생각하며 테이블 분리+ 속성 만들기
- 식별, 비식별 생각하며 관계 맺기 (비식별 추천!)
+) ERD를 쉽게 짜려면 insert할 때를 상상해보자 난 이게 좀 효과가 있는 거같다
ERD란 Entity Relationship Diagram의 줄임말로 Entity개체와 Relationship관계를 중점적으로 표시하는 다이어그램이다.
ER그리고 ERD다이어그램을 그린다고 배웠는데, 짬이 좀 차니까 ER이고 뭐고 API명세서 다음은 바로 ERD로 들어간다.
ERD란 데이터모델링 중 하나인데, 내가 사용하는 Cloud ERD는 PK, FK, 도메인 등을 정하는 논리적 모델링이다.
요구사항 분석-> 개념적 데이터 모델링(ERD)-> 논리적 데이터 모델링(릴레이션 스키마 생성)-> 물리적 데이터 모델링(실제 테이블 생성) 단계 중에서 논리적 데이터 모델링에 속한다.
내가 고민하는 것은, 어떻게 하면 ERD를 빠르고 효과적으로 그릴 수 있을까이다. 그리고 사실 ERD그리다 보면 엔티티같은게 1,2,3정규화에 의해서 빠르게 분해되기도 하고 반정규화로 갑자기 엔티티x2 이벤트가 벌어지기도 한다.
그래서 간단하게 명사로 표현가능한 엔티티 만들기+ 1,2,3, 정규형 생각하기(쉽게 생각하자. 모든 컬럼은 pk에 종속되어야한다는 뜻이다 무조건 갑-을 이여야한다)
정규화란? DB 데이터들의 중복을 최대한 제거하여 이상현상을 방지하기 위한 기술
1정규화란? 속성 하나당 하나의 속성값만 가져야 한다 즉, 중복 금지
2정규화란? 복합키일 때, 특정 컬럼에만 종속된 컬럼이 존재하면 안된다.
예를 들어서 학생이름, 수강과목이 키일 때 학생이름이나 수강과목 중 하나만 알아도 나이를 알 수 있으면 안된다.
3정규화란? 갑-을 관계만 있어야지, 갑-을-정 관계가 있어선 안된다. 테이블이란 PK라는 갑에 묶인 모든 을관계여야 한다.
3정규형은 좀 굳이?싶어서 챗지피티한테 물어봤다.
Q. 예를 들어서 학번, 이름, 대학, 학과가 컬럼인 테이블이 있어
그런데 여기에서 pk는 학번인데 대학-학과가 종속성이 있어
굳이 대학, 학과를 따로 나눠야 돼?
3정규화를 거치지 않을 경우, 다양한 데이터 관련 문제들이 발생할 수 있습니다. 이러한 문제들은 데이터베이스의 성능 저하, 데이터 무결성 손상, 그리고 데이터 관리의 어려움으로 이어질 수 있습니다. 구체적으로 살펴보겠습니다:
중복 데이터의 증가: 3정규화를 거치지 않으면, 이행적 종속성으로 인해 데이터의 중복이 발생할 수 있습니다. 예를 들어, 대학 이름과 학과 이름이 여러 학생 레코드에 걸쳐 중복되어 저장될 수 있습니다. 이는 데이터베이스의 저장 공간을 비효율적으로 사용하게 하며, 중복된 데이터를 관리하는 데 드는 비용이 증가합니다.
업데이트 이상(Update Anomaly): 중복된 데이터가 있을 경우, 데이터를 업데이트할 때 일관성을 유지하는 것이 어려워집니다. 예를 들어, 특정 대학의 이름이 변경되었을 때, 해당 대학 이름이 저장된 모든 레코드를 찾아 업데이트해야 합니다. 만약 일부 레코드의 업데이트를 놓치게 되면, 데이터베이스 내에는 같은 대학에 대해 서로 다른 두 가지 이름이 존재하게 되어 데이터의 일관성이 손상됩니다.
삽입 이상(Insertion Anomaly): 새로운 데이터를 삽입할 때, 필요 이상의 정보를 입력해야 하는 경우가 발생할 수 있습니다. 예를 드어, 어떤 학과가 아직 학생이 없는 상황에서 해당 학과 정보만을 데이터베이스에 추가하고 싶어도, 학생 정보 없이는 학과 정보를 단독으로 저장할 수 없는 구조가 됩니다.
삭제 이상(Deletion Anomaly): 특정 정보를 삭제할 때, 원치 않는 추가적인 정보까지 함께 삭제될 위험이 있습니다. 예를 들어, 마지막 남은 학생의 레코드를 삭제할 때, 해당 학생이 속한 학과 정보까지 데이터베이스에서 사라질 수 있습니다.
검색 성능 저하: 데이터의 중복과 비효율적인 구조는 데이터베이스의 검색 성능에도 영향을 미칠 수 있습니다. 중복 데이터를 통해 불필요하게 큰 데이터베이스 크기는 검색 쿼리의 처리 시간을 늘릴 수 있습니다.
이러한 문제들은 데이터의 무결성을 손상시킬 뿐만 아니라, 데이터베이스 관리와 유지보수를 복잡하게 만듭니다. 따라서, 데이터베이스 설계에서는 3정규화를 비롯한 정규화 과정을 적극적으로 고려하는 것이 중요합니다.
오호.. 업데이트 이상, 삽입 이상, 삭제 이상 진짜 오랜만에 들어본다 근데 듣고보니 구구절절 옳은 말이다. ERD짤 때 이런 부분들도 생각해봐야겠다.
식별, 비식별 관계란?
식별은 부모 테이블의 키를 자식테이블이 PK로 사용하는 관계고 비식별은 자식과 부모가 관계가 없다. 식별관계는 DB에서 부모-자식 간의 관계를 보장해주지만 IT는 언제 요구사항이 변할 지 모른다. 확장성을 위해선 비식별을 더 권장하는 것같다.
식별 관계의 장점
데이터의 정합성 유지를 DB에서 한번 더 할 수 있다
자식 테이블에 데이터가 존재한다면 부모 데이터도 반드시 존재한다고 보장할 수 있다
식별 관계의 단점
요구사항이 변경되었을 경우 구조 변경이 어렵다
비식별 관계의 장점
변경되는 요구사항을 유동적으로 수용할 수 있다
부모 데이터와 독립적인 자식 데이터를 생성할 수 있다
비식별 관계의 단점
데이터 정합성을 지키기 위해서는 별도의 비즈니스 로직이 필요하다.
자식 데이터가 존재해도 부모 데이터가 존재하지 않을 수 있다
즉, 데이터 무결성을 보장하지 않는다
