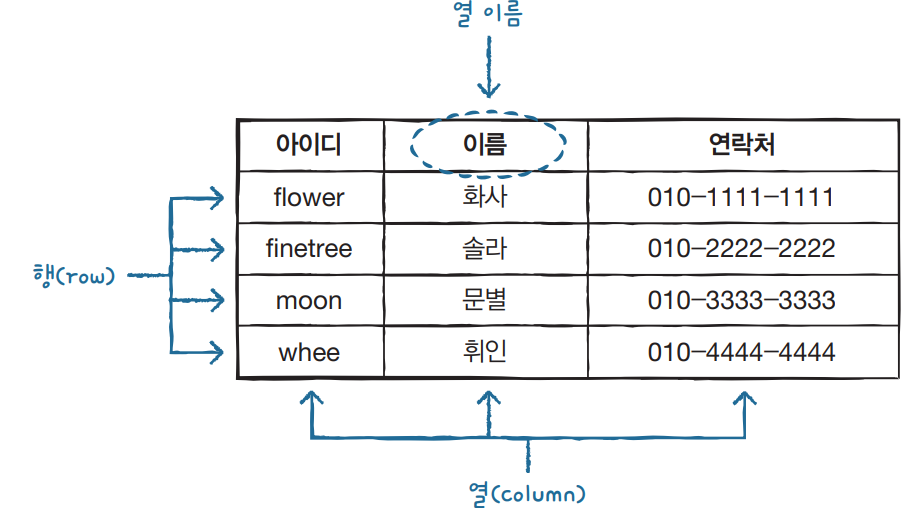
1. 관계형 DB vs NoSQL DB
관계형 데이터베이스
(RDBMS; Relational DataBase Management System)
- 관계형 모델을 기반으로 하는 가장 보편화된 데이터베이스 관리시스템
- 데이터를 저장하는 테이블의 일부를 다른 테이블과 상하 관계로 표시하며 상관관계를 정리
- RDBMS에는 SQL Server, MySQL, PostgreSQL, MariaDB 등이 있음
관계형 데이터베이스의 단점
- 저장하고자 하는 데이터의 형태가 변화하면 그에 맞춰 테이블 구조(스키마)를 변경해야 함
- column별로 데이터 타입 (문자열, 정수, 실수) 등이 정해져 있어 해당 데이터 타입에 맞지 않는 데이터는 삽입할 수 없음
→ 테이블 형태가 아니며, 형태가 자주 바뀌는 데이터를 저장하기에는 적합하지 않음
예시 (JSON과 같은 Key - Value 형태의 데이터):
{
"product": {
"id": "12345",
"name": "iPhone14",
"brand": "Apple",
"price": 999.99,
"description": "고급 기능을 갖춘 하이엔드 스마트폰입니다.",
"specs": {
"screenSize": "6.2 inches",
"processor": "Octa-core",
"ram": "8 GB",
"storage": "256 GB",
"battery": "4000 mAh"
},
"reviews": [
{
"user": "John",
"rating": 4,
"comment": "카메라 화질이 인상적이네요"
},
{
"user": "Sarah",
"rating": 5,
"comment": "배터리가 오래가요"
}
]
}
}관계형이 아닌 데이터베이스 (NoSQL)
NoSQL은 전통적인 RDBMS와 다른 DBMS를 지칭하기 위한 용어
- 데이터 저장에 고정된 테이블 구조가 필요하지 않음
- 조인(Join) 연산*을 사용할 수 없으며, 수평적으로 확장이 가능한 DBMS
*Join 연산: RDBMS에서 여러 테이블의 데이터를 결합하여 데이터를 조회하는 연산
2. NoSQL 데이터베이스의 분류 및 특징
- 키-값(Key-Value) DBMS
- Unique한 (중복값이 없는) 키(Key)에 하나의 값(Value)을 가지고 있는 형태
- 키 기반 Get / Put / Delete 제공
- 예시: Redis, DynamoDB
| Key | Value |
|---|---|
| ID | 12 |
| Name | 홍길동 |
| Gender | Male |
1-1) Redis
- Redis는 Key-Value(키-밸류) 구조의 비정형 데이터를 메모리에 저장하여 사용할 수 있는 NoSQL DB로, 모든 데이터를 메모리에 저장, 관리하므로 빠른 처리를 보장
- 기본적으로는 Key-Value 저장 구조이며, List / Set / Hash 등의 다양한 저장방식 제공
활용 사례
- 캐시(Cache) Layer로 Redis 활용
-
캐싱: 애플리케이션 성능을 개선하기 위해 자주 액세스하거나 계산 비용이 많이 드는 데이터를 별도의 레이어 (fast-access layer)에 저장하는 것
-
자주 요청되는 데이터를 Redis에 캐싱하면, 데이터 요청이 데이터베이스를 거치지 않고 Redis에서 직접 제공되므로 지연 시간을 줄이고 전반적인 응답 시간 개선 가능
-
데이터베이스가 과부화되는 것을 방지
→ 실시간으로 대용량 데이터를 처리해야 할 때 활용 가능
-
1-2) DynamoDB
- AWS가 제공하는 완전 관리형 Serverless NoSQL
- 대용량 트래픽 처리 가능한 어플리케이션을 개발하면서 개발 리소스를 줄일 수 있음
특징: Primary Key로 Partition Key, Sort Key 활용
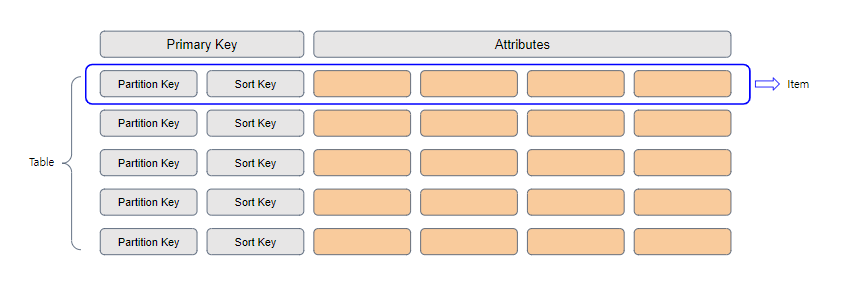
Partition Key: Primary Key로써 테이블 생성 시 필수 입력 사항
해당 값을 이용하여 DynamoDB를 파티셔닝하여 들어오는 데이터를 각 파티션에 나눠서 적재
Sort Key: Primary Key지만 테이블 생성 시 선택 입력 사항
****파티션 내의 항목을 오름차순 또는 내림차순으로 정렬하는 데 사용
정렬 키의 값에 따라 다양한 항목을 효율적으로 쿼리할 수 있음
Global Secondary Index (GSI):
Partition Key와 Sort Key의 조합만으로 데이터를 조회하기 비효율적일 때 이용하는 인덱스
Attribute 중 하나를 Partition Key로 사용하여, Attribute + Sort Key 두 개를 인덱스로서 활용할 수 있음
(column 여러 개를 primary key로 이용하는 composite primary key와 비슷)
-
DynamoDB 활용 예시
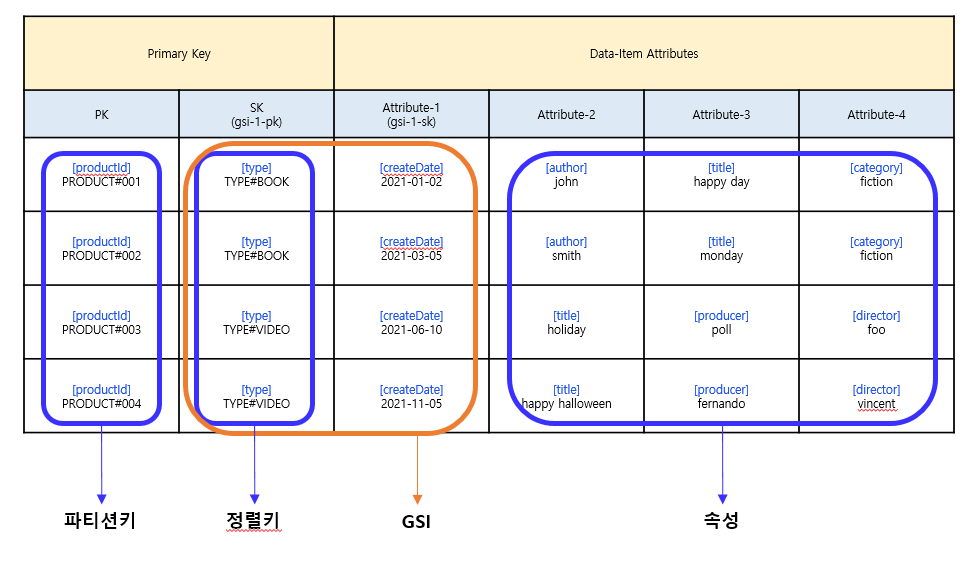
- Partition Key엔 카디널리티가 높은 속성인 Product 고유 ID 지정
- Sort Key엔 해당 Product의 타입(BOOK, VIDEO 등) 지정
- GSI를 두어 GSI-PK는 테이블의 Sort Key로 지정, GSI-SK는 CreateDate로 지정
이렇게 구성하면 물품 고유 ID로 파티셔닝이 될 것이고, GSI를 두었기 때문에 TYPE# 별로 물품 목록이 조회가 가능하며 생성 날짜 별로 선택/범위 조회가 가능
- 문서 저장(Document Store) DBMS
-
문서(Document) 타입의 데이터를 저장하는 DBMS
-
문서 타입은 XML, JSON과 같이 구조화된 데이터 타입으로, 복잡한 계층 구조 표현 가능
-
예시: MongoDB, Couchbase
-
MongoDB 활용 사례 (LINE 알림 센터)
MongoDB를 선택한 이유
- 문서 데이터베이스(document database)
-
알림의 데이터 형태가 문서 데이터베이스에 적합하기 때문
-
하나의 알림을 표현하기 위한 데이터 (JSON)
{ "owner": "-", "notificationId": "-", "serviceType": "-", "categoryType": "-", "notificationType": "-", "templateType": "-", "itemKey": "-", "originsCount": 1, "origins": [ { "createdTimeMsec": -, "createdDate": -, "sender": {-}, "landing": "-", "component": { "profile": {-}, "preview": {-}, "buttons": {-}, "icon": {-}, "like": {-} }, "searchKeys": {-}, "messageArguments": {-} } ] }
알림 데이터가 문서 데이터베이스에 적합한 이유
-
각 알림 데이터는 상호 간 독립적
중복되는 데이터가 없으며, 별도 정규화*가 필요 없음
(정규화: 관계형 데이터베이스에서 중복되는 데이터를 방지하기 위해 테이블을 여러 개로 나누는 것)
-
알림 관련 스펙은 형태가 변하거나 예상치 못한 기능이 추가되는 등의 변화 가능성이 큼
-
따라서 데이터 추가 및 변경이 자유로워야 하기 때문에 스키마리스(schemaless) 구조가 좋음
-
알림 관련 스펙 추가 예시
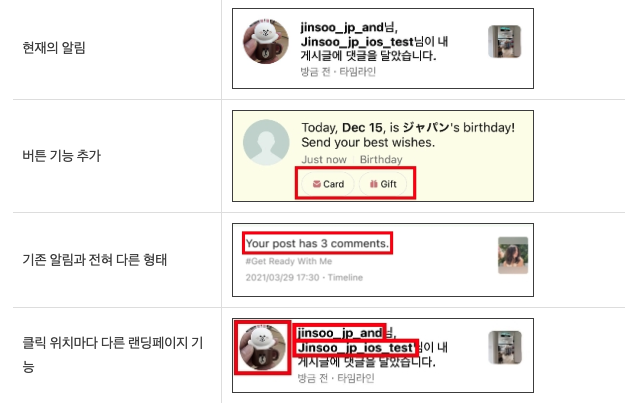
→ 위와 같이 다양한 기능을 계속 추가하기 위해서는 데이터 구조 변경이 불가피한데,
스키마리스 구조는 이와 같은 스펙 추가 및 변경을 자유롭게 할 수 있도록 함
-
-
다양한 데이터 타입과 그 타입에 맞는 다양한 쿼리를 지원
→ 추후 어떤 스펙이 신규로 요구될지 모르는 상황에 대응할 수 있는 유연함을 제공
- 그래프(Graph) DBMS
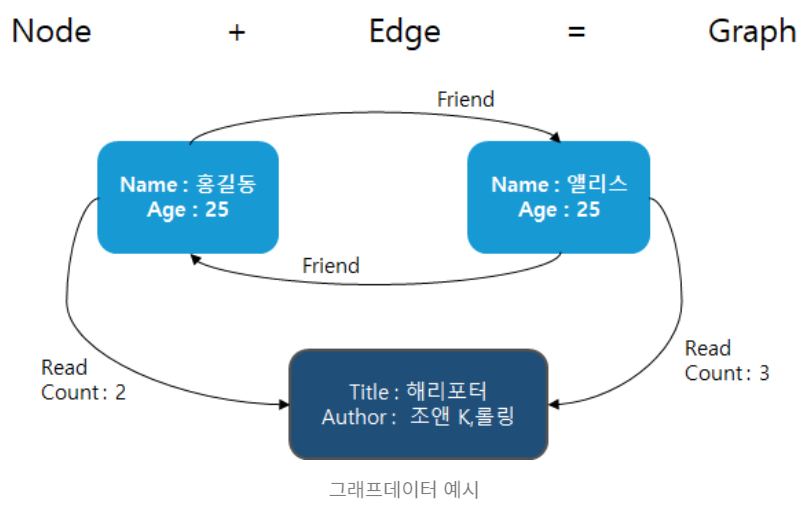
- 노드와 엣지로 구성된 그래프로 데이터를 표현하는 DBMS
- **노드(node):** 추적 대상이 되는 사람, 기업, 계정 등 의 실체를 대표한다. 관계형 데이터베이스의 **레코드, 관계, 로우,** 도큐먼트 데이터베이스의 **도큐먼트**와 개념이 거의 동등하다.
- **엣지(edge):** 노드를 다른 노드에 연결하는 선이며 **노드 간의** **관계를 표현**한다.- 노드 간 관계를 구조화하여 저장

- 예시: Neo4j, AWS Neptune
- 컬럼 기반 데이터 저장(Column Family Data Store) DBMS
- Key 안에 (Column, Value) 조합으로 된 여러 개의 필드를 갖는 DBMS
- 테이블 기반, 조인 미지원, 컬럼 기반으로 구글의 Bigtable 기반으로 구현
- 예시: HBase, Cassandra
레퍼런스
