Elasticsearch의 기본 개념과 동작 원리

Elasticsearch란?
Elasticsearch(ES)는 Apache Lucene 기반 분산 검색 엔진이다.
REST API를 이용해 데이터 처리를 수행할 수 있다.
역색인(Inverted Index) 구조로 데이터를 저장하며, 입력이 들어오면 score에 따라 지정한 갯수만큼의 검색 결과를 반환한다. (정렬 기준을 지정하지 않으면 score로 따라 정렬한다.)
역색인에 대해 간략히 설명해보자면, RDB 였다면
| id | text |
|---|---|
| 1 | hello world |
| 2 | hello elastic |
이렇게 저장될 데이터를
| term | id |
|---|---|
| elastic | 2 |
| hello | 1, 2 |
| world | 1 |
이렇게 저장해서 "hello"가 포함된 document id를 찾을 수 있도록 저장하는 것이다.
특징은
- 오픈 소스이고,
- 입력에 대해 실시간으로 데이터를 분석하여 결과를 반환하며,
- 기술 문서와 커뮤니티 등이 잘 구성되어 있고,
- 버전업이 매우 빠른 편이다
.. 등등이 있다.
용어는
기본적인 NoSQL 용어와 비슷하다. RDB와 간단히 비교해보자면
| ES | RDB |
|---|---|
| Index | Table |
| Shard | Partition |
| Document | Row |
| Field | Column |
이렇게 되겠다.
ES는 Index 단위로 검색을 요청하고, 같은 Index가 여러 Shard로 쪼개져서 분산 저장된다.
그리고 Indexing 이란, 데이터를 검색 가능한 형태로 처리하여 저장하는 것을 의미한다.
Elasticsearch의 동작 원리
Elasticsearch는 Lucene 기반 분산 검색 엔진이라고 했다.
(Lucene은 Java로 이루어진 정보 검색 라이브러리 오픈소스이다.)
Lucene을 통해 ES가 어떻게 동작하는지 알아보겠다.
Lucene은 Indexing 요청이 들어오면 역색인을 생성하는데, 최초에는 메모리 버퍼에 저장한다.
Indexing, Update, Delete 등의 작업이 수행되면 변경 관련 정보들을 메모리에 저장해두었다가 주기적으로 Disk에 flush한다.
Lucene의 flush + a = ES의 refresh
여기서 Flush된 Document가 ES의 검색 대상이 된다.
+) ES의 검색 대상이 되려면 Lucene의 IndexReader가 open된 시점에 Indexing이 완료되어야 하기 때문에,
변경이 발생한 Index를 검색에 반영하려면, DirectoryReader.openIfChanged()를 호출해서 새 IndexReader를 열고, 기존 것을 닫아야 한다.
Lucene의 Flush는 페이지에 데이터를 넘겨준 것을 의미하므로, 실제로 Disk에 저장되는 것을 보장하지는 않는다. 따라서 실제 Disk와 동기화를 위해 Lucene은 주기적으로 fsync() System Call을 호출하는데, 이것을 commit이라고 한다. (비싼 작업!)
Lucene의 commit + a = ES의 flush
이렇게 해서 Disk에 저장된 역색인, Document 내용 등을 Segment라고 한다.
Segment는 Lucene의 검색 대상이 된다.
Segment는 immutable하다.
따라서, Update 하려면 새로 생성 후, 주기적으로 merge를 수행한다. Delete 시에는 Flag만 남겨두는데, 장애 발생 시 복구를 위해 삭제 시에도 이력은 보존되어야 하기 때문이다.
Elasticsearch의 구조를
종합적으로 살펴보면 아래와 같다.
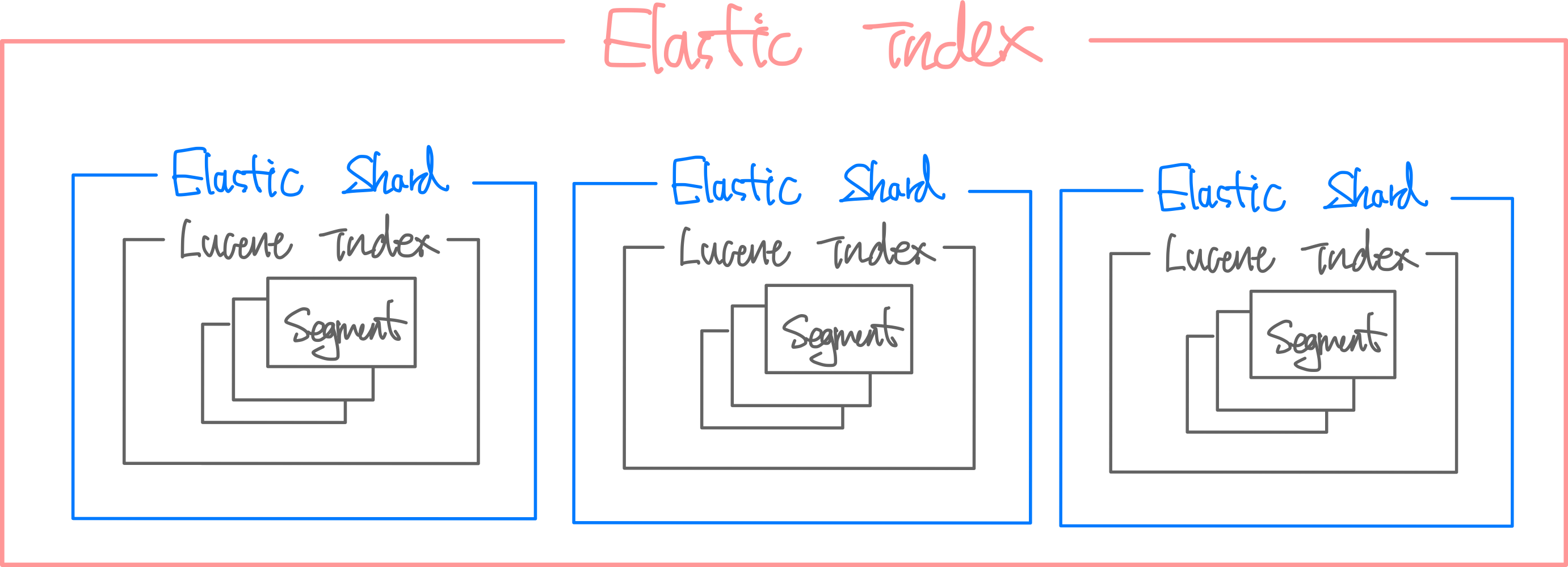
Segment 여러 개로 Lucene Index를 구성하고, Lucene은 Lucene Index 내에서만 검색 가능하다.
... 추가 예정
