오늘은 Telemetry에 대해 기록해보자.
📘 Telemetry란?
다수의 마이크로 서비스가 동작하는 환경에서 장애, 운영 이관 등의 실행중인 프로세스에서 발생하는 이벤트의 흐름을 파악하는데 오랜 시간이 소모된다.
Telemetry는 서비스들을 모니터링하고, 서비스별로 발생하는 이슈들에 대응할 수 있도록 환경을 구성하는 역할을 한다.
📜 Monitoring이란?
Monitoring이란 인프라 및 응용 프로그램의 성능이나 효율성을 확인하는 작업이다.
Monitoring을 위해서는 Metric 수집, Logging, Tracing 영역에서의 데이터 수집 및 분석이 필요하다.
Monitoring은 각 대상에게서 수집한 Metric을 통해 대상 리소스의 사용률 등을 수치로 표현하는 기능을 수행한다.
모니터링 방식엔 Push방식과 Pull방식 2가지로 나뉜다.
✏ Push 방식
- 각 서버에 클라이언트를 설치하고 이 클라이언트가 메트릭 데이터를 수집해서 서버로 보내면 서버가 모니터링 상태를 보여주는 방식이다.
대표적인 방식은 graphite, influxDB가 있다.
✏ Pull 방식
- 서버가 각 클라이언트를 알고 있어야 하는 것이 아니라 서버에 클라이언트가 떠 있으면 서버가 주기적으로 클라이언트에 접속해서 데이터를 가져오는 방식이다.
대표적인 방식은 Prometheus 가 있다.
✏ Push vs Pull
-
데이터의 정확성
Pull base의 경우 Metric이 발생하는 port를 항상 Listening인 상태로 유지해 직접 접근이 가능하기 때문에 데이터의 정확성이 높다.
Push base의 경우에는 Metric을 보낼 때만 임시적으로 수집서버와 연결을 한다. -
데이터의 양 조절
Pull base의 경우 수집하는 서버에서 targets을 지정해 Metric을 수집하기 때문에 문제가 없지만 Push base의 경우 지정된 서버 외에도 Metric을 보낼 수 있다.
Whitelist와 같은 방법으로 제한을 할 수 있지만 기능을 지원하지 않는 시스템이 대부분이다. -
보안 측면
Push base에서 Metric을 전송할 때 client 서버에서 TLS를 통해 연결하고 Metric을 전송하는 일은 복잡하고 쉽지 않다.
이에 비해 Pull의 경우 HTTP로 안전하게 Metric을 수집할 수 있다. -
HA 측면
Data-Backend에서 장애가 발생하더라도, Pull 방식에선 수집 Host에 영향이 없으나 Push 방식에선 데이터 전송 재시도 등 Host에 영향이 생긴다.
Pull 방식이 더 유리해보여 Prometheus로 테스트를 진행해보았다.
📜 Logging이란?
Logging은 MSA에서 발생하는 Log들을 수집해서 보여준다.
Log는 실행중인 프로세스에서 발생하는 이벤트의 흐름을 의미하며 MSA에서는 실행중인 서비스들의 수가 모놀리식 아키텍처에 비해 많기 때문에 장애와 같은 이벤트 발생 시 파악하기 힘드며 root cause를 찾기 어렵다.
중앙 집중형 로깅 패턴 사용으로 위의 문제점을 해결한다.
- 중앙 집중형 로깅 패턴이란?
스크립트로 중앙 서버로 모든 로그를 복사하여 관리하는 로깅 방식으로 로그의 저장과 처리를 서비스 실행 환경에서 분리한 패턴이다.
각 서비스에서 발생한 로그들은 한 곳에 모아진 후 중앙의 데이터 저장소로 보내지고, 로깅 도구를 이용하여 로그를 분석하고 처리한다.
✏ Logging 고려 사항
-
저장소 측면
마이크로 서비스에서 로그를 저장소에 저장할 경우 쌓여진 로그가 디스크를 가득 채우기 때문에 어플리케이션 설계 시 로그에 대하여 재활용 기법을 사용해야 한다.
어플리케이션 내부에 로그를 저장할 경우 컨테이너가 종료되거나 재시작될 경우 사라질 수가 있기 때문에 로그를 어플리케이션 서버 외부 저장소에 저장해야 한다. -
보안 측면
로그 스트림의 경우 개인 정보를 포함할 수 있기에 로그 파일이 ACL을 통해서 로그 관리자만 로그를 확인할 수 있도록 권한을 제어한다.
로그 암복호화를 통하여 로그 자체를 보호하는 방법도 있으나 대량의 로그 발생 시 성능에 있어 영향을 끼친다.
📜 모니터링 구조
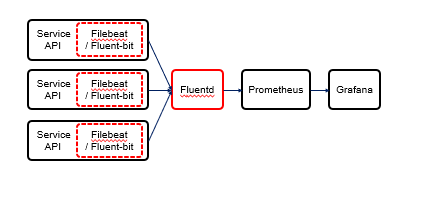
Logstash는 Elastic 사에서 개발한 툴이므로 Elasticsearch, Kibana 등의 다른 Elastic 툴과의 통합이 용이하다.
하지만 Fluentd는 CNCF 재단에 속한 프로젝트로서 클라우드 네이티브 시스템, 마이크로 서비스, Prometheus와 같은
다른 CNCF 프로젝트와 함께 사용하기 용이하다는 점이 다르다. Elastic 사의 시스템과도 통합을 지원한다.
fluentd도 kibana를 붙일 수 있고, logstash자체의 기능이 fleuntd보다 못하기 때문에 logstash보다 fluentd가 더 나을거 같다.
또한 logstash exporter는 따로 없지만 fluentd exporter는 공식적으로 지원을 하기에 Promethus와 잘 맞을거 같다.
Fluentd가 플러그인도 다양하고 서버 리소스도 적게 사용되어서 더 유리하다.
Fluentd는 대용량 로그에 강해 실시간 성이 떨어지는 단점이 있는데 이 부분은
(R)syslog? 를 이용하면 되지 않을까 라는 생각했고
또한 Prometheus에는 단일 노드 사용으로 인한 HA 구성 및 scale-out 에 대한 문제점이 존재하는데 이를 해결해줄 오픈 소스로 Thanos 존재한다.
✏ 마무리
윈도우 환경에서 Fluent-bit를 통해 로그 파일을 Input으로 읽어 들인 후 Output을 이용하여
Prometheus Metric 정보로 내보냈다. 하지만 로그의 성공/에러 전반적인 수치 정도만
확인할 수 있었고 자세한 로그 내용이나 어디에서 문제가 되었는지는 확인할 수 없었다.
따라서 우리가 사용하는 의도와는 다른 방향이기 때문에 FIuent-bit를 사용하는 것이 아닌
Grafana에서 지원하는 Promtail과 Loki를 통해 로그 정보를 파악하는 것이 좋다고 판단하였고
Promtail, Loki 연동 테스트하여 정상적으로 로그 정보가 잘 출력되는 것을 확인했었다.
