Redis 기초
아래 링크의 강의를 기반으로 정리한 문서입니다.
[우아한테크세미나] 191121 우아한레디스 by 강대명님
Redis?
자주사용되는 데이터를 미리 올려놓는 저장소
Remote에 있는 In-memory Data Structure
Supported Data Structure
- String: Key-value
- List
- SET
- Sorted-set
- Hash
Cache
Cache쓰는 이유
나중에 요청된 결과를 미리 저장해두었다가 빠르게 제공하기 위해 쓴다
Dynamic Programming의 핵심은 이전 연산 결과(값)를 저장했다가 나중에 또 쓰는 것이 핵심
- CPU Cache
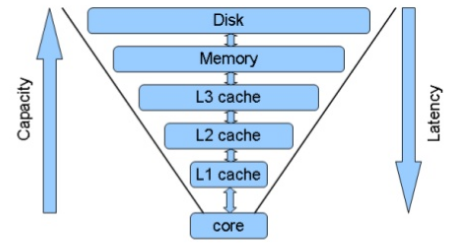 속도와 용량의 반비례 관계
속도와 용량의 반비례 관계
일반적인 DB 접근
Client → Web Server → DB
디스크 접근할 때 마다 속도가 느릴 수 있다.
파레토 법칙에 의해 전체 80%의 요청은 20% 사용자에 의해 처리된다.
그렇기 때문에 캐싱은 보다 적은 메모리지만 효율적으로 수행 가능
Cache 구조
- Look aside Cache
DB에 접근하기 전에 Cache에 데이터가 있는지 확인하고 DB에 접근하는 패턴 - Write Back
쓰기가 빈번한 DB일 경우 일단 Cache에 모든 데이터 저장하고 특정 시점에 DB에 저장
(Insert query를 한번씩 500번 날리는 거랑 500개를 한번에 날리는 거 속도 비교
후자가 더 빠름)
단점: DB에 저장하기 전에 캐시에 저장하므로 장애가 발생하면 데이터 모두 소멸
Redis는 Collection을 제공한다.
Collection을 사용하면 개발의 편이성, 난이도에 영향을 준다.
1. 만약 랭킹 서버를 구현할 경우 가장 간단한 방법?
- DB에 User's Score를 저장하고 Score를 정렬 후 읽기
- User가 많으면 (데이터가 많으면) 디스크에 접근하는 횟수가 많아지므로 속도에 문제가 있다. → In-Memory 기준으로 랭킹 서버 구현이 필요 Redis의 Sorted Set을 이용하여 구현
2. 친구 List를 Key-Value 형태로 관리한다면?
Redis의 경우 자료구조가 Atomic하기 때문에, 해당 Race Condition을 피할 수 있다.
(Light Requet에 따라 잘못된 결과를 발생할 수는 있다.)
3. 결론
→ Collection을 사용하면 개발 속도를 증가시키고, 다양한 문제를 해결할 수 있다.
Collection 주의사항
- 하나의 컬랙션에 너무 많은 아이템을 담으면 좋지 않음
(가능하면 10000개 이하) - Expire는 Collection의 Item 개별로 걸리지 않고 전체에 걸림
Redis 운영
- 메모리 관리
- O(N) 명령어 주의
- Replication
- 권장 설정

To be Cloud DevOps Engineer