pandas
[초기 설정]
터미널 내 pip install matplotlib 입력
- csv 파일 시각화
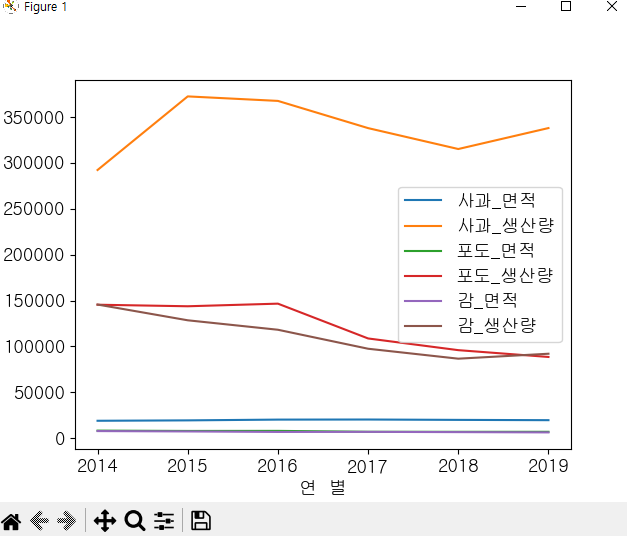
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
plt.rcParams['font.family'] = 'New Gulim' #글꼴 지정
plt.rcParams['font.size'] = 13 # 글자 크기
df_fruit = pd.read_csv('과실별생산량.csv', index_col = 0)
df_fruit.plot() #plot()함수 : 그래프 그림
plt.show()
- csv 파일 특정 내용만 시각화
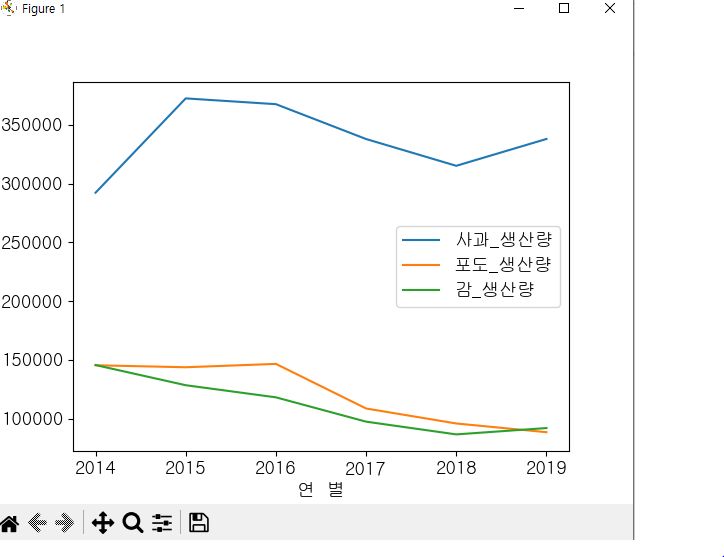
# pip install matplotlib
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
plt.rcParams['font.family'] = 'New Gulim' #글꼴 지정
plt.rcParams['font.size'] = 13 # 글자 크기
df_fruit = pd.read_csv('과실별생산량.csv', index_col = 0)
df_fruit[['사과_생산량','포도_생산량','감_생산량']].plot()
plt.show()
- csv 파일 박스 그래프
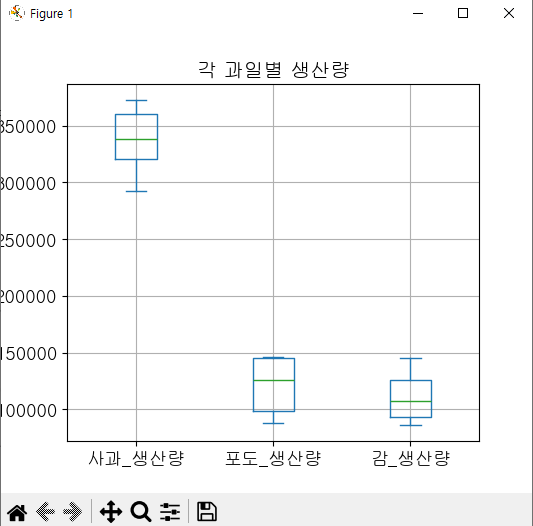
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
plt.rcParams['font.family'] = 'New Gulim' #글꼴 지정
plt.rcParams['font.size'] = 12 # 글자 크기
df_fruit = pd.read_csv('과실별생산량.csv', index_col = 0)
df_fruit.plot(y=['사과_생산량','포도_생산량', '감_생산량'], kind="box",
figsize = (12,8), title = '각 과일별 생산량',
grid = True, fontsize = 13,
ylabel = '과일별 생산량')
plt.show()
"""
figsize(가로,세로): 인치 1인치=72px
수치형 데이터의 통계 정보확인에 이용. box그래프는 데이터의 분포를
한눈에 보여줌.
[방법2]
df_fruit.boxplot(column=['사과_생산량','포도_생산량', '감_생산량'],
figsize = (12,8), grid = True, fontsize = 13)
[방법3]
df_fruit.plot.box(y=['사과_생산량','포도_생산량', '감_생산량'],
figsize = (12,8), grid = True, fontsize = 13)
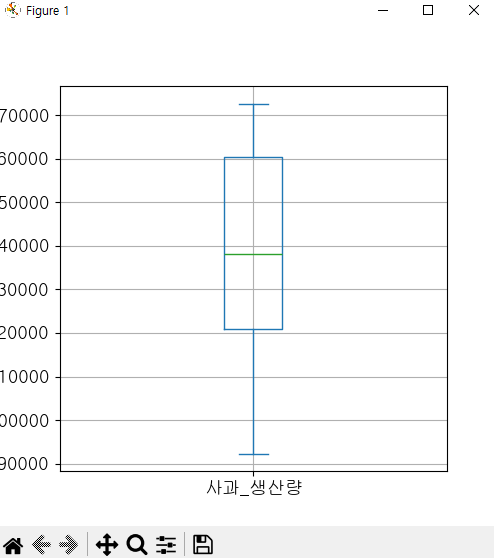
"""
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
plt.rcParams['font.family'] = 'New Gulim' #글꼴 지정
plt.rcParams['font.size'] = 12 # 글자 크기
df_fruit = pd.read_csv('과실별생산량.csv', index_col = 0)
df_fruit['사과_생산량'].plot(kind = 'bar', figsize = (5,5),
grid = True, fontsize = 13)
plt.show()
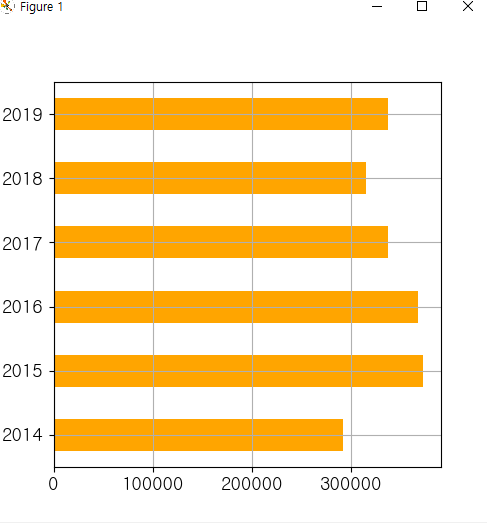
- 컬러 설정하여 그래프화
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
plt.rcParams['font.family'] = 'New Gulim' #글꼴 지정
plt.rcParams['font.size'] = 12 # 글자 크기
df_fruit = pd.read_csv('과실별생산량.csv', index_col = 0)
df_fruit['사과_생산량'].plot(kind = 'barh', figsize = (5,5),
grid = True, fontsize = 13,
color="orange")
plt.show()
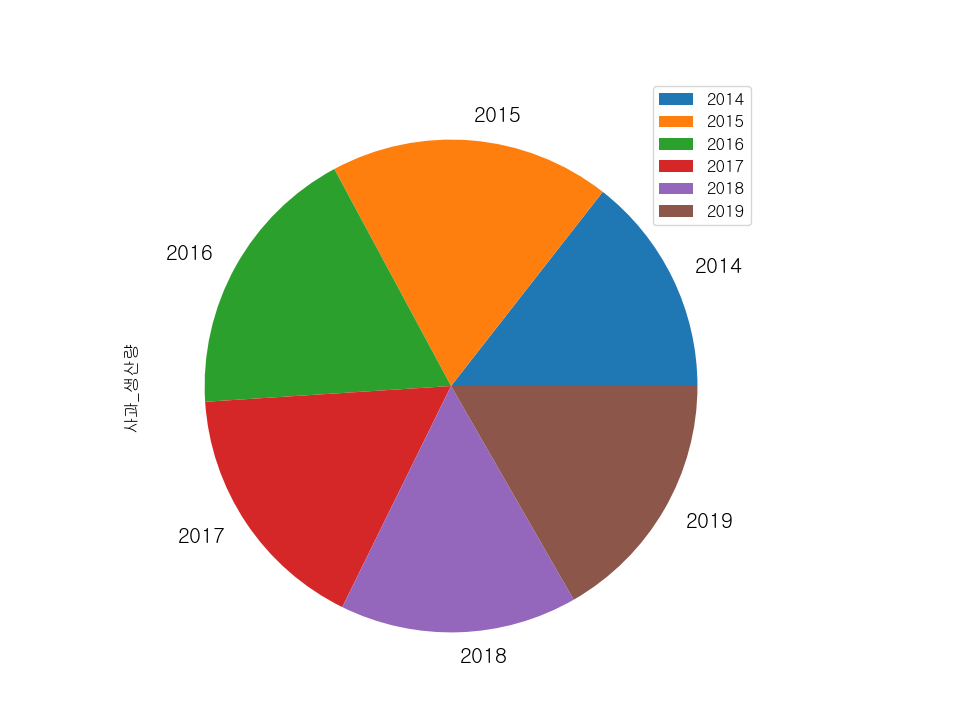
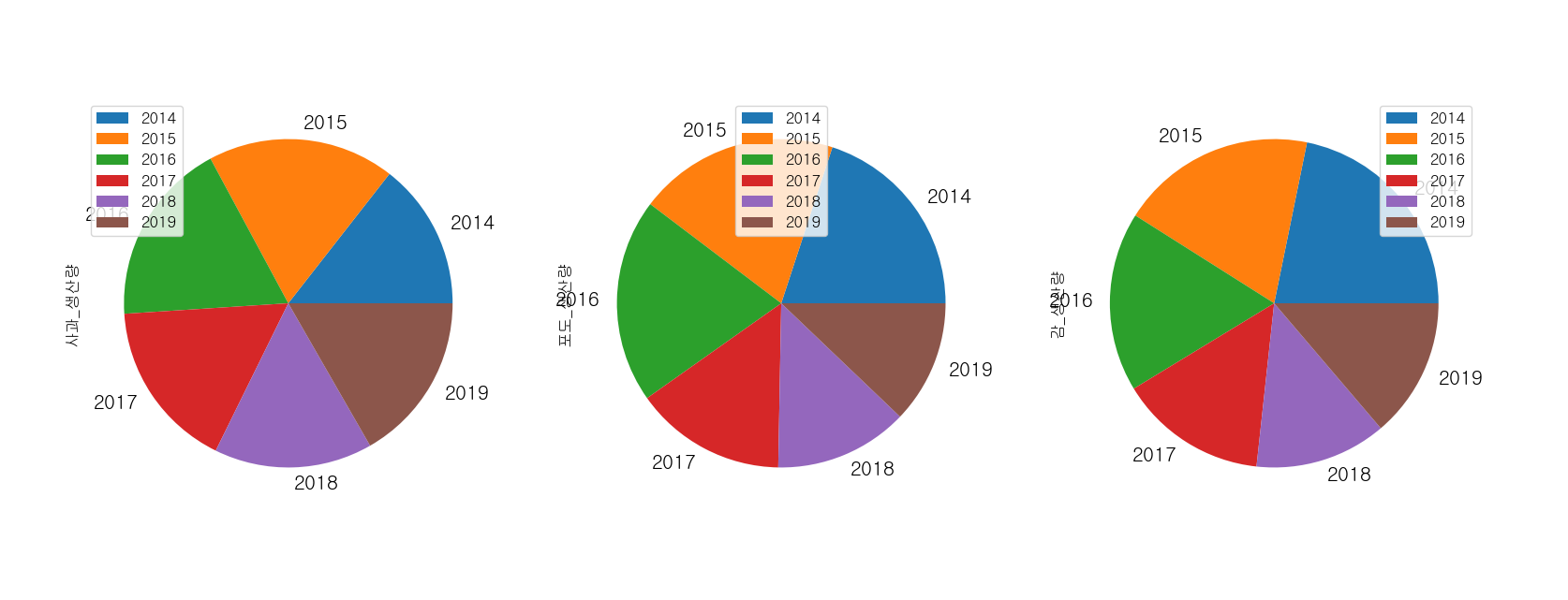
- 바둑판식 그래프화
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
plt.rcParams['font.family'] = 'New Gulim' #글꼴 지정
plt.rcParams['font.size'] = 12 # 글자 크기
df_fruit = pd.read_csv('과실별생산량.csv', index_col = 0)
df_fruit.plot(kind="pie",figsize = (20,8), grid = True, fontsize = 10,
subplots=True)
df_fruit[['사과_생산량','포도_생산량','감_생산량']].plot(kind = 'pie',
figsize = (20,8), grid = True,
fontsize = 15, subplots = True)
df_fruit.plot(y='사과_생산량', kind = 'pie', figsize = (20,8),
grid = True, fontsize = 15)
plt.show()
#matplotlib의 subplots는 여러 개의 그래프를 바둑판식으로 배열하여 나타내줌
- hist 그래프
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
# matplotlib 자체 내장
import matplotlib.font_manager as fm
plt.rcParams['font.family'] = 'New Gulim' #글꼴 지정
plt.rcParams['font.size'] = 12 # 글자 크기
#hist 그래프
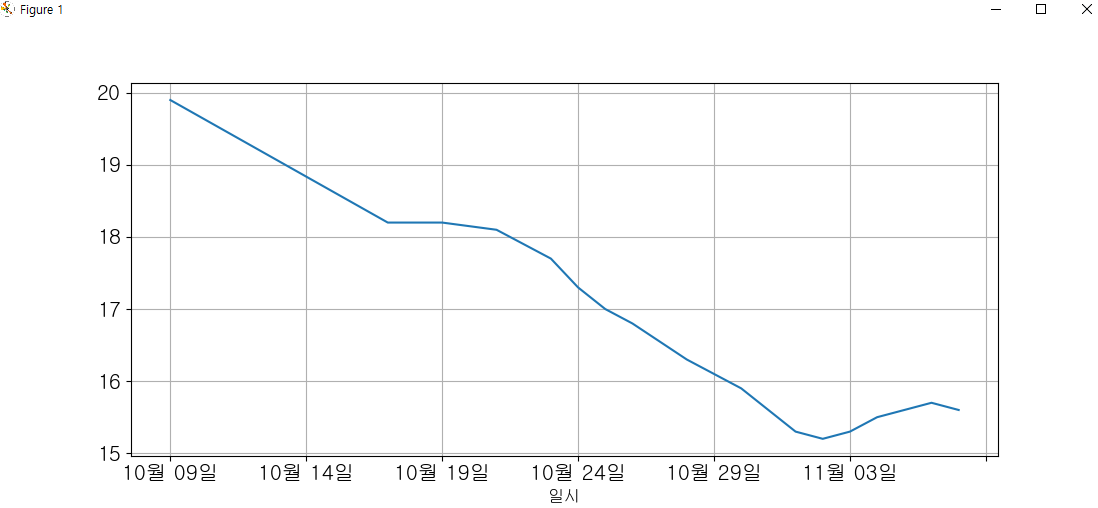
df_jeju = pd.read_csv('2022제주_기후.csv', encoding = 'euc-kr', index_col = 0)
df_temp = df_jeju['평균기온(°C)'].interpolate()
df_temp.plot(figsize = (12,8), grid = True, fontsize = 15)
plt.show()
"""
히스토그램은 데이터가 많고 연속적인 경우에 적합
"""
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
plt.rcParams['font.family'] = 'New Gulim' #글꼴 지정
plt.rcParams['font.size'] = 12 # 글자 크기
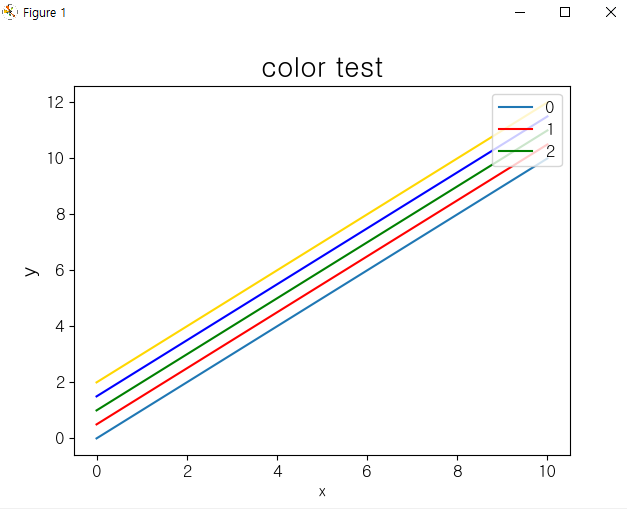
x = np.linspace(0,10,10)
y = x
plt.title('color test', size = 20)
plt.xlabel('x', size = 10)
plt.ylabel('y', size = 15)
plt.plot(x,y, label = 0)
plt.plot(x,y+0.5, 'r', label = 1) #red
plt.plot(x,y+1, 'g', label = 2) #green
plt.plot(x,y+1.5, color = '#0000ff') #blue
plt.plot(x,y+2, color = 'gold') # gold
plt.legend(loc = 'upper right') # 범례 위치
plt.show()- 그래프 노출 세부 설정
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
#import matplotlib.font_manager as fm
plt.rcParams['font.family'] = 'New Gulim' #글꼴 지정
plt.rcParams['font.size'] = 12 # 글자 크기
x = np.linspace(0,10,10)
y = x
fig = plt.figure(figsize = (12,5))
############################
plt.subplot(131)
plt.title('1번', fontsize = 15)
plt.xlabel('X', size = 12)
plt.ylabel('Y', size = 12)
plt.plot(x,y,ls = '-.' , marker = '*', ms = 10, color = 'r',
lw = 2, mfc = 'b', label = 'y=x')
plt.legend(loc = 'best')
############################
plt.subplot(1,3,2)
plt.plot(x,y+0.5, 'ro') #red marker 'o' = circle
plt.title('2번', fontsize = 15)
plt.legend(labels = ['y=x+5'])
############################
plt.subplot(133)
plt.plot(x,y+2,ls = ':', marker = 'v',c = 'gold', ) #
plt.title('3번', fontsize = 15)
plt.legend(labels= ['y=x+0.5'], bbox_to_anchor= (0,-0.2,1,0.2),
mode= 'expand', shadow= True, loc= 'lower center')
plt.suptitle('legend & line & mark test', size= 30)
plt.tight_layout()
print(fig)
plt.show()- 도트형 그래프화
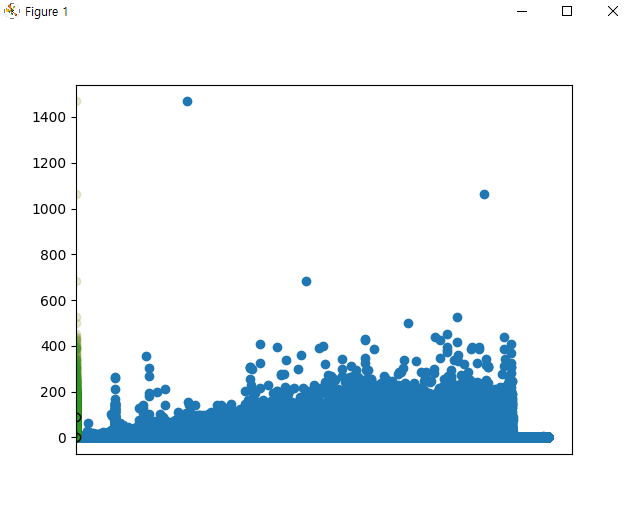
import pandas as pd
import matplotlib.pyplot as plt
ns_df = pd.read_csv('ns_202104.csv', low_memory=False)
plt.scatter(ns_df['번호'], ns_df['대출건수'])
plt.scatter(ns_df['도서권수'], ns_df['대출건수'], alpha=0.1)
temp = ns_df[['대출건수','도서권수']]
plt.boxplot(temp)
average_borrows = ns_df['대출건수']/ns_df['도서권수']
plt.scatter(average_borrows, ns_df['대출건수'], alpha=0.1)
plt.show()
"""
alpha 인자를 사용하여 마커의 투명도를 지정할 수 있습니다.
0은 완전히 투명하고 1은 완전히 불투명함을 의미
"""

비전공자 QA의 자기개발 공부노트