Sel-Q 프로젝트에서는 클라이언트 상태를 관리하기 위해
Redux-Toolkit을, 서버 상태를 관리하기 위해React-Query를 사용하였습니다.결정하는 과정에서
어떤 고민을 했고어떤 이유로 라이브러리를 선정하고어떻게 활용했는지에 대해 이야기해 보려 합니다.
상태 관리란?
상태를 React 공식문서에서는 폼에 입력하면 입력 필드가 업데이트 되고 '구매'를 클릭하면 상품이 장바구니에 담는 것, 나아가 컴포넌트는 상호 작용의 결과로 변화하는 화면의 내용(state)를 기억하는 저장소라고 소개하고 있습니다.
컴포넌트는 기억 저장소이고, 상태(state)는 컴포넌트의 메모리라고 정리할 수 있습니다.
상태는 하나의 컴포넌트에서만 사용되기도 하지만, 컴포넌트 간 상태라 해서 prop을 통해 다른 컴포넌트로 전달하여 사용하기도 합니다. 이렇듯, 상태 관리는 컴포넌트에서만 이뤄지는 것이 아닌 페이지, 프로젝트 전역에서 사용되기도 합니다.
이전 상태 관리 방식
Sel-Q 프로젝트는 기존의 리액트로만 진행했던 프로젝트를 다양한 상태 관리 툴을 사용하여 프로젝트를 전체적으로 고도화시켰습니다. 이전에 리액트로만 진행했을 때는 아래와 같은 방식으로 데이터를 패칭해오고 data에 대한 상태뿐만 아니라 isLoading, error와 같은 API 상태를 추가하여 관리하고 있었습니다.
아래의 코드를 보면 이전의 코드가 얼마나 더러웠는지 한 눈에 파악하기 어려웠는지 확인할 수 있습니다.
const [data, setData] = useState([]);
const [isLoading, setIsLoading] = useState(true);
const [error, setError] = useState(null);
useEffect(()=> {
const fetchData = async () => {
try {
// 데이터 가져오기 전에 로딩 상태를 true로 설정
setLoading(true);
// 데이터를 가져오는 API 호출 (여기서는 예시로 axios를 사용합니다)
const response = await axios.get.('...');
// 성공적으로 데이터를 가져온 경우 상태 변수 업데이트
setData(response.data);
setError(null);
} catch(error){
setError(error);
setData(null);
} finally {
// 데이터 가져오기 완료 후 로딩 상태를 false로 설정
setLoading(false);
}
}
fetchData();
}, [])
if (loading) {
return <div>Loading...</div>;
}
return ( ... )UI 관련 로컬 상태는 빼고 데이터 패칭만 봐도 복잡한데 이후에 데이터를 추가했을 때 최신 데이터를 받아오기 위해 여러 번 패치를 해주어야 하고 이 과정에서 동일한 데이터를 반복 요청하고 성능 저하가 발생했습니다. 또한 에러 처리까지 하게 되면 디버깅하기도 굉장히 어려워지고 이는 좋지 못한 사용자 경험으로 이어졌습니다.
그리고 고도화를 거치면서 사용자 상태 관리가 추가되었습니다. 부모 컴포넌트에서 자식 컴포넌트로 Props Drilling을 통해 필요한 컴포넌트에 전달하게 되면 애플리케이션이 조금만 복잡해져도 상태 변화를 추적하기 상당히 어려워집니다.
그렇기에 Prop Drilling으로 컴포넌트 간 상태를 전달하는 것이 아닌 전역 상태 관리에 대한 필요성을 느끼게 되었습니다.
이전의 상태 관리 문제점
1. 복잡한 데이터 패칭
데이터 패칭 과정이 복잡하고, 여러 번의 패치를 통해 최신 데이터를 유지가 필요했고 이로 인해 동일한 데이터 반복 요청과 성능 저하되었습니다.2. 에러 처리의 어려움
데이터 패칭 과정에서 발생하는 에러를 일관성 있게 처리하기 어려웠고 에러 처리로 인한 디버깅이 어려웠습니다.3. API 호출 상태 관리
API 상태에 대한 관리를 컴포넌트에서 처리하니 호출 코드가 많고 복잡하였습니다.4. 전역 상태 관리의 필요성
사용자 상태 관리가 추가됨에 따라 애플리케이션이 복잡해지고 Prop Drilling으로 상태 공유하면 상태 변화 추적하기 매우 어려웠습니다.
위 문제들을 해결하기 위해 React Query와 Redux-Toolkit을 도입하였습니다. 각 라이브러리가 어떠한 장점들이 있길래 선정하였는지 설명드리겠습니다.
React Query 선택 이유
리액트 쿼리는 서버 상태 관리를 위한 대표적인 라이브러리입니다.
리액트쿼리(TanStack Query) 공식 홈페이지에 들어가자마자 강력한 비동기 상태 관리라고 소개하고 있습니다.
- 유용한 옵션과 간편한 인터페이스
- 리액트 훅과 유사한 간단한 사용법
- 캐싱, 동기화 등 다양한 기능 제공
위와 같이 쿼리의 기능 및 장점을 정리해 볼 수 있습니다. 이렇게 비동기 작업을 쉽게 다룰 수 있고 서버 상태를 선언적으로 처리하고 캐싱, 동기화를 통해 여러 번 패칭해던 것을 해결할 수 있습니다.
물론 이렇게 좋은 라이브러리를 사용한다고 해서 모든 문제가 해결된 것은 아닙니다. 쿼리를 사용하면서 시작은 좋았지만, 다양한 기능들을 제공한 만큼 복잡하고 다른 문제들도 발생하였습니다. 이것들은 아래에서 다뤄보도록 하겠습니다.
정리 - Server State 관리를 위한 React Query
커스텀 훅을 활용하여 비동기 데이터 처리와 생태 관리를 구현하였습니다. 이를 통해 Client와 Server State의 분리가 가능해졌습니다.
API 호출과 관련된 코드를 커스텀 훅으로 걷어낼 수 있었습니다.
캐싱, 무효화 등의 기능을 활용하여 상태를 간편하고 효율적으로 다룰 수 있게 되었습니다.
선언적 로딩, 에러 핸들링, 쿼리 무효화 등 높은 개발자 경험을 제공해 줍니다.
프로젝트 특성상 사용자 정보, 질문 데이터, 조회, 등록, 수정 등 서버쪽에서 관리하고 패칭, 캐싱, 동기화 등 서버의 상태를 업데이트할 일이 많았기에 리액트 쿼리에서 제공해 주는 기능들을 효율적으로 활용할 수 있다고 판단하였습니다.
Redux Toolkit 선택 이유
Redux는 전역 상태 관리를 위한 대표적인 라이브러리로, 애플리케이션에 중앙 저장소 역할을 합니다. Redux 공식 홈페이지에 가면, Redux는 예측 가능한 상태 컨테이너라고 소개하고 있습니다.
- 일관되게 동작하고 실행되어 예측 가능
- 상태와 로직의 중앙 집중화
- 개발자 도구를 통해 쉬운 상태 추적
위 장점을 모두 가진 Redux이지만 전에 경험했을 때 Store, Action, Reducer, Dispatch 등 많은 Boilerplate 코드가 필요했습니다. 이전에 Redux를 경험하며 개념을 공부했기에 익숙했고, Redux의 Boilerplate를 줄여주고 보다 간편하게 사용할 수 있는 Redux-Toolkit가 있었습니다.
정리 - Client State 관리를 위한 Redux Toolkit
- Boilerplate가 적은 Redux-Toolkit을 통해 보다 간편하게 사용할 수 있었습니다.
- Redux Toolkit을 통해 사용자의 전역 상태 관리, 인증 / 인가를 효율적으로 처리할 수 있었습니다.
- createAsyncThunk 함수를 통해 비동기 작업을 중앙 관리할 수 있었다. 이것을 통해 코드의 가독성과 유지 보수성이 향상되었습니다.
- Fulfilled, Rejected, Pending 액션을 생성을 통해 Redux 상태를 업데이트 할 수 있었습니다.
로그인 상태, 사용자 정보와 같은 전역 상태를 일관된 방식으로 예측 가능하게 업데이트가 가능했고 이를 관리할 때 상태와 로직을 중앙에서 관리할 수 있었다는 장점과 Boilerplate가 적고 익숙하여 개발 생산성을 향상시킬 수 있다고 판단하였습니다.
React Query 잘 쓰기(Feat. Query Key Factories)
React Query의 장점인 데이터 캐싱을 활용하기 위해 데이터를 캐시하고 의존성에 변화가 생기면 데이터를 다시 불러오기 위해 쿼리 키를 사용합니다. 필요에 따라서는 데이터를 업데이트하거나 특정 쿼리를 무효화할 수 있습니다.
Sel-Q 프로젝트에서도 거의 모든 페이지에서 질문 데이터가 사용되고 관리자 페이지에서는 사용자 정보, 문제 정보 등이 사용되고 질문 데이터에서는 카테고리별, 중요도별, 날짜별 필터링 기능이 있고 사용자 정보나 문제 정보에서도 각각 필터링 기능들이 존재합니다.
이렇게 많은 쿼리들을 업데이트하고 무효화할 때 관리하기 굉장히 번거롭고 쿼리키 이름 짓기도 유니크하게 지어야 하기 때문에 항상 고민이 되었습니다. 또한, 필터링 기능이 추가될 때면 수동으로 쿼리 키를 선언하였기 때문에 오류가 발생하기 쉽고 유지 보수하기 어렵웠습니다.
효율적으로 쿼리 키를 관리하기 위해 쿼리키 팩토리 라이브러리를 사용하는 대신 리액트 쿼리의 메인테이너인 도도가 제안하는 직접 쿼리키 팩토리를 구축하여 쿼리키를 객체로 구조화하기로 결정했습니다.
쿼리키 팩토리를 구조화할 때의 규칙을 설명드리면,
1. 쿼리 키는 배열로 사용할 것.
- React Query v4부터 모든 키는 배열이어야 합니다.
2. 가장 일반적인 것부터 구체적인 것으로 구성할 것.
- 위와 같이 구성하면, 세분화된 키로 해당되는 데이터를 무효화나 업데이트를 보다 유연하게 할 수 있습니다.
3. 각각의 기능 별로 하나의 쿼리 키 팩토리를 구성할 것.
- 각 엔트리와 쿼리 키를 생성하고 독립적으로 접근할 수 있기 때문에 유연성이 높아집니다.
아래는 셀큐 프로젝트 관리자 페이지에서 질문 데이터를 관리하기 위해 questionKeys라는 독립적인 쿼리키 객체를 만들고 전체 질문, 질문 상세, 질문 리스트를 key로 하였고 필터 조건이나 상세 질문의 id를 받아 쿼리 키를 생성할 수 있도록 구조화한 예시입니다.
export const questionKeys = {
all: ['questions'],
lists: () => [...questionKeys.all, 'list'] as const,
list: (filters: string) => [...questionKeys.lists(), { filters }] as const,
details: () => [...questionKeys.all, 'detail'] as const,
detail: (id: number) => [...questionKeys.details(), id] as const,
...
};
// 🚀 모든 질문 목록을 무효화합니다
queryClient.invalidateQueries({
queryKey: questionKeys.lists(),
});
// 🙌 하나의 질문을 미리 불러옵니다
queryClient.prefetchQueries({
queryKey: questionKeys.detail(id),
queryFn: () => fetchQuestion(id),
});Query Key Factory 패턴을 활용하여 쿼리 키를 독립적인 객체로 구조화하여 사용할 수 있었습니다. 이를 통해 쿼리 키 생성 시 보다 효율적으로 선언적인 쿼리 키를 생성할 수 있고 유지 보수성을 높일 수 있었습니다.
아키텍처로 보는 Sel-Q, 셀큐
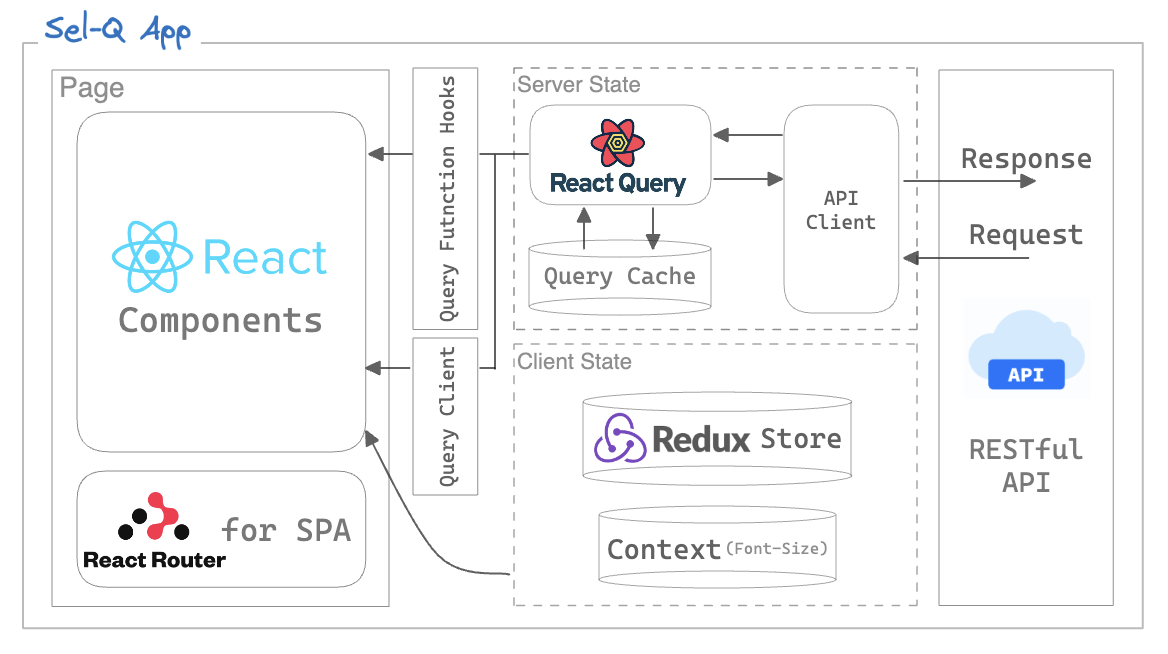
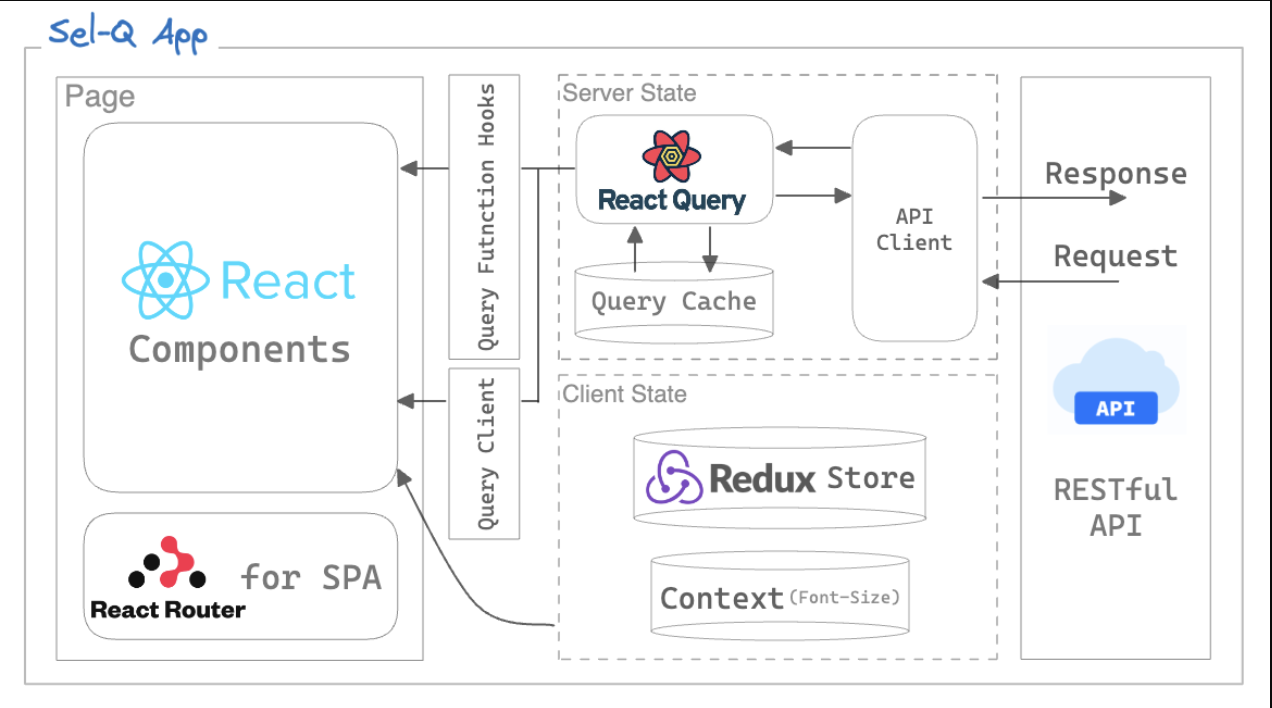
전체적인 구조와 요소들 간의 관계를 직관적으로 파악하기 위해 Sel-Q 프로젝트의 아키텍쳐를 다이어그램으로 시각화해보았습니다.
셀큐 프로젝트를 아키텍쳐를 보며 정리해보면 다음과 같습니다.
기본적인 API 통신은 RESTful한 API를 통해 React Query를 활용하여 서버 데이터를 요청하고 관리하고 있습니다. 또한, React Query의 핵심 기능 중 하나인 Query Cache를 활용하여 서버로부터 받은 데이터를 캐싱합니다.
클라이언트 상태 중 전역 상태인 사용자 로그인 정보 데이터는 Redux-Toolkit를 통해 관리합니다. 또한, API 요청 상태 및 전역적으로 사용되는 상태를 제외한 컴포넌트 상태는 로컬 state에서 관리합니다.
이렇게 클라이언트 상태와 서버 상태를 특성에 맞게 store에 선언된 상태를 관리하고 있고 각 컴포넌트는 레이어된 아키텍처를 통해 유기적으로 결합되어 있어 가독성이 좋고 유지 보수 가능하고 파악하기 쉽게 구성할 수 있었습니다. 프로덕트가 이렇게 상태를 관리함으로써 컴포넌트 간 의존성을 줄이고 유연하고 유지 보수하기 편한 구조로 만들기 위해 노력했습니다.
참고자료
- Redux 공식문서
- TanStack Query 공식문서
- TkDodo's blog Effective React Query Keys
- 카카오페이 프론트엔드 개발자들이 React Query를 선택한 이유
- Store에서 비동기 통신 분리하기 (feat. React Query)
- 우아콘2023, 프론트엔드 상태관리 실전 편
- React Query의 구조와 useQuery 실행 흐름 살펴보기
오류가 있거나 게시글 관련하여 피드백 주시면 감사드려요!
