NumPy의 몇 가지 장점
빠르고 메모리를 효율적으로 사용하여 벡터의 산술 연산과 브로드캐스팅 연산을 지원하는 다차원 배열 ndarray 데이터 타입을 지원
반복문을 작성할 필요 없이 전체 데이터 배열에 대해 빠른 연산을 제공하는 다양한 표준 수학 함수를 제공
배열 데이터를 디스크에 쓰거나 읽을 수 있다. (즉 파일로 저장한다)
선형대수, 난수발생기, 푸리에 변환 가능, C/C++ 포트란으로 쓰여진 코드를 통합
NumPy 주요 기능
1) ndarray만들기
ndarray 객체는 arange()와 array([])로 만들 수 있음.
2) 크기 (size, shape, ndim)
ndarray.size
ndarray.shape
ndarray.ndim
reshape()
size 행렬 내 원소의 개수
shape 행렬의 모양
ndim 행렬의 축(axis)의 개수
reshape() 메서드는 행렬의 모양을 바꿔줌. 단, 모양을 바꾸기 전후 행렬의 총 원소 개수(size)가 맞아야 함.
3) type
NumPy: numpy.array.dtype
파이썬: type()
NumPy의 원소는 꼭 동일한 데이터 type이여야함
4) 특수 행렬
단위행렬
0 행렬
1 행렬
5) 브로드캐스트
ndarray 객체에 상수 연산
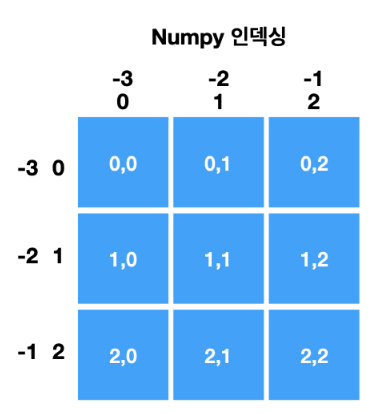
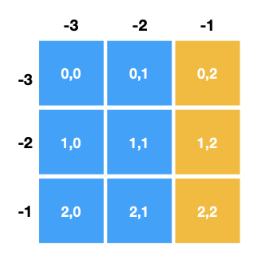
6) 슬라이스와 인덱싱
이미지와 관련된 파이썬 라이브러리
matplotlib
PIL
이미지 파일을 열고, 자르고, 복사하고, rgb 색상 값을 가져오는 등 이미지 파일과 관련된 몇 가지 작업을 수행
간단한 이미지 조작
이미지 조작에 쓰이는 메서드
open : Image.open()
size : Image.size
filename : Image.filename
crop : Image.crop((x0, y0, xt, yt))
resize : Image.resize((w,h))
save : Image.save()
Pandas
특징
NumPy기반에서 개발되어 NumPy를 사용하는 애플리케이션에서 쉽게 사용 가능
축의 이름에 따라 데이터를 정렬할 수 있는 자료 구조
다양한 방식으로 인덱싱(indexing)하여 데이터를 다룰 수 있는 기능
통합된 시계열 기능과 시계열 데이터와 비시계열 데이터를 함께 다룰 수 있는 통합 자료 구조
누락된 데이터 처리 기능
데이터베이스처럼 데이터를 합치고 관계 연산을 수행하는 기능
(1) Series
Series는 일련의 객체를 담을 수 있는, 1차원 배열과 비슷한 자료 구조입니다. 따라서 배열 형태인 리스트, 튜플, 딕셔너리를 통해서 만들거나 NumPy 자료형(정수형, 실수형 등)으로도 만들 수 있음.
(2) DataFrame
DataFrame은 표(table)와 같은 자료 구조입니다. Series는 한 개의 인덱스 컬럼과 값 컬럼, 딕셔너리는 키 컬럼과 값 컬럼과 같이 2개의 컬럼만 존재하는데 비해, DataFrame은 여러 개의 컬럼을 나타낼 수 있습니다. 그래서 csv 파일이나 excel 파일을 DataFrame으로 변환하는 경우가 많음.
통계 관련 메서드
count(): NA를 제외한 수를 반환.
describe(): 요약 통계를 계산.
min(), max(): 최소, 최댓값을 계산.
sum(): 합을 계산.
mean(): 평균을 계산.
median(): 중앙값을 계산.
var(): 분산을 계산.
std(): 표준편차를 계산.
argmin(), argmax(): 최소, 최댓값을 가지고 있는 값을 반환.
idxmin(), idxmax(): 최소, 최댓값을 가지고 있는 인덱스를 반환.
cumsum(): 누적 합을 계산.
pct_change(): 퍼센트 변화율을 계산.
