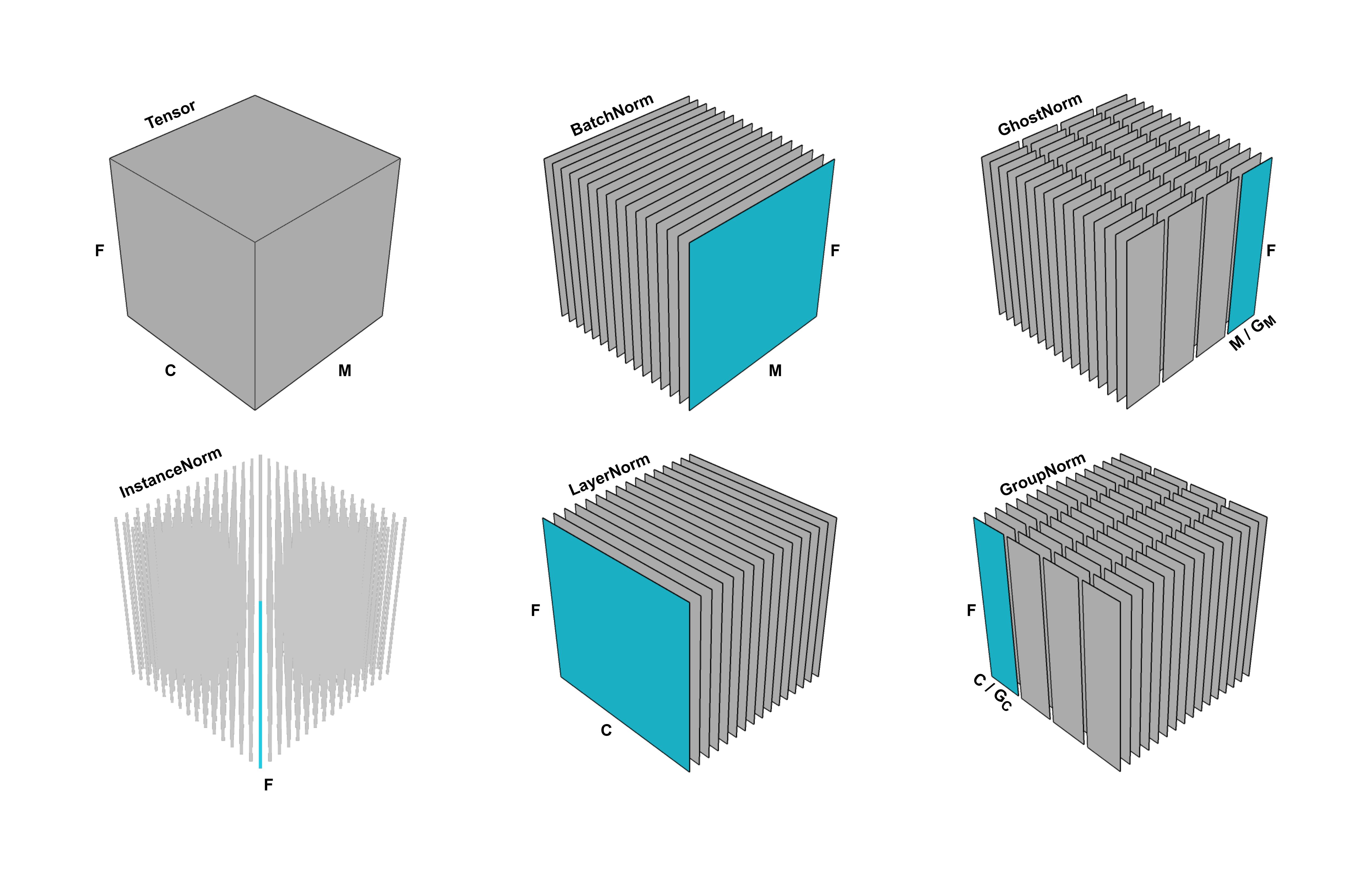
Batch vs Layer Normalization
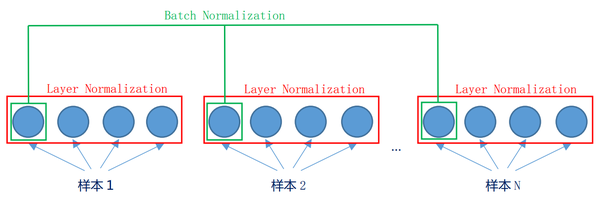
배치 정규화와 레이어 정규화는 서로 다른 "방향"으로 수행됩니다. 그림과 같이 배치 정규화의 경우, 하나의 미니 배치에서 서로 다른 이미지의 동일한 뉴런의 입력값이 정규화됩니다. 레이어 정규화에서는 미니 배치를 고려하지 않고 같은 레이어에 있는 서로 다른 뉴런의 입력 값을 정규화합니다.
-The Answer of Brad Liu (위 게시글의 Brad Liu 라는 분이 답해주신 글입니다)
Batch 는 데이터를 처리하는 단위다. 모델을 학습할 때, 모든 데이터를 한번에 처리하는게 아니라, 작은 그룹(mini batch) 로 나눠서 순차적으로 모델에 가중치를 업데이트 하는 역할을 맡고 있다.
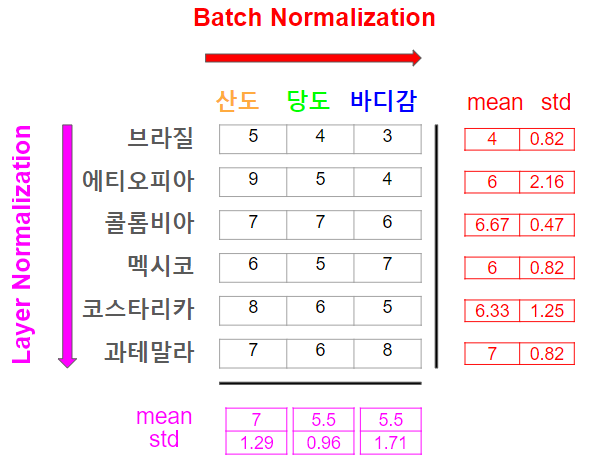
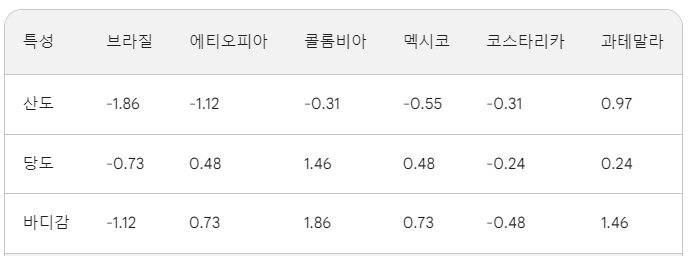
Batch Norm 과 Layer Norm 을 커피 원두 shop 에서의 예시로 비교해보겠다. 커피 원두 shop 에는 많은 종류의 원두가 있고, 각각의 원두는 고유의 특성 (산도, 당도, 바디감 등등) 을 갖고 있다.
"Batch Norm"
원두를 원두 바구니에 보관하는데, 각 바구니는 특정한 기준에 따라 분류된다. 예를들면 원산지, 가공방법 등으로 분류해서 보관한다고 생각하면 된다. 각 바구니가 "mini batch" 이다. 그리고 고객들에게 좀 더 퀄리티있고 일관된 원두를 제공해주기 위해, 각 바구니(mini batch) 내에서 원두들의 특성이 어떻게 분포하는지 평가를 해보려고 한다. 일단 각 바구니 내에서 원두들의 산도, 당도, 바디감 등등의 평균 값을 계산한다. 그리고 이 평균값으로 각 원두의 특성들(산도, 당도, 바디감 등 등)이 얼마나 떨어져 있는지 ( 표준편차 ) 를 계산한다. 이 과정을 거치면 각 바구니( "mini batch" ) 내의 원두들이 얼마나 일관된 특성을 갖는지 알 수 있다.
"Layer Norm"
이번에는 shop 전체에서 각각의 원두를 개별적으로 알아볼 것이다. 산도, 당도, 바디감 등의 평균 값을 계산하고 이 평균 값으로부터 각 원두의 특성들이 얼마나 떨어져있는지 ( 표준편차 ) 를 계산한다.
즉, Layer Norm 은 개별 원두가 고유적으로 갖을 수 있는 특징을 기반으로 Normalization 한다고 보면된다. 브라질, 에티오피아 산 커피는 원두가 단일적으로 갖는 특징은 아니다. 반면, Batch Norm 은 바구니 내에 각각의 특징들을 갖고있는 원두들끼리 얼마나 일관된 품질을 갖고있는가를 Normalization 하는 것이다.
그리고 위 값에서 를 계산해주면 완벽한 Normalization 된 값을 얻게된다. 계산이 절대 귀찮아서 그런 것은 아니지만 Gemini 님에게 계산을 부탁했는데 아래와 같이 나왔다. 계산이 정확한지 아닌지는 검산을 안 해봐서 모른다. 확인하고싶으면 각자가 알아서 검산해보길 바란다.
Batch Normalization 결과
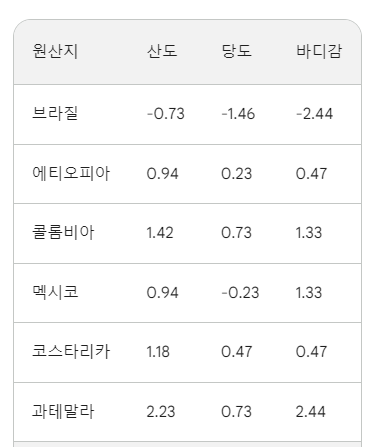
Layer Normalization 결과
Layer Normalization 구하는 수식
( 감마 ) : scaling 이라고도 읽으며, 보통 초기값은 1 ( 절대적이지 않음 )
( 베타 ) : shifting 이라고도 읽으며, 보통 초기값은 0 ( 절대적이지 않음 )
( 뮤 ) : 평균
( 시그마 ) : 표준편차
: 분산
( 입실론 ) : 분모가 0이 되는 것을방지하는 값, 는 1차원 벡터 내 뉴런 개수에 맞춰서 저장된다. 예를들어 layer 에 512개의 뉴런 ( feature ) 이 있다면, 초기 값은 보통 아래와 같이 조정됨.
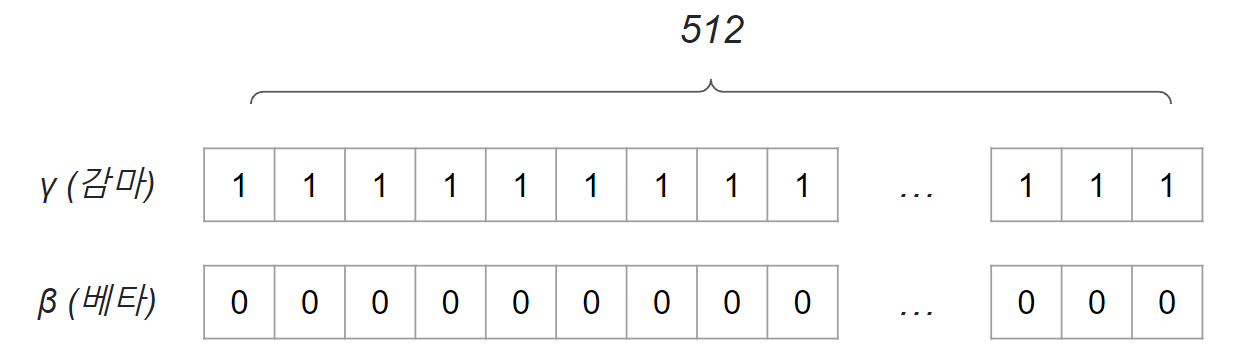
보통 관례적으로 초기에 스케일링() 을 1로 주고, 시프팅() 을 0으로 준다. 이 의도를 알필요가 있는데, 과 은 스케일링 및 시프팅 변화를 초기부터 적용하지는 않겠다는 의도이다.
스케일링() 은 정규화된 데이터의 범위 및 분산을 조절하는 역할을 하며, 시프팅() 은 정규화된 데이터의 평균을 조절하는 역할을 한다.
