※ 모든 글은 다음의 목차로 이루어져있습니다.
1. 코딩에 대한 기본적인 지식이 있는 분들/혹은 상세한 설명 없이 단지 코드를 사용하기 만하고 싶은 분들을 위한 간략한 요약문
2. 코딩에 대한 아무런 지식이 없는 초보자를 위한 입문글
💡 이 글에서 다루는 프로젝트 파일
src/dataProcessors/from_google_spread_sheet.py
본 프로젝트는 [요리][사냥] [낚시][장비뽑기] 등의 기능에 대해서 구글 스프레드 시트에서 지문을 불러와 사용하고 있습니다. 이해를 돕기 위해 제공되는 예시 시트는 아래에서 확인하실 수 있습니다.
해당 시트는 공개용으로 만들어진 페이지로 얼마든지 복제해가서 사용하셔도 좋습니다.
다만 모든 예시 지문의 저작권은 저희에게 있으며 따로 사용시 지운 후 새로이 작성해주시기 바랍니다.
1. 빠른 실행을 위한 간단한 설명
- 사용할 시트의 이름을 src/dataProcessors/from_google_spread_sheet.py 상단의 SHEET_NAME 에 적는다. 위의 예시 시트의 이름은 'bot-data-example'이므로 해당 시트를 이용하면 아래와 같은 코드가 나옵니다.
SHEET_NAME = "bot-data-example"-
시트에 authentification 시 만들어둔 구글 드라이브 api 용 계정을 사용자로 추가합니다. (자세한 내용은 [1]Authetification 의 구글 인증 링크 참조)
-
새로운 시트를 추가할 경우 src/dataProcessors/from_google_spread_sheet/DataProcessingService/generate_sheet_data 함수 아래편에 코드를 추가한다.
cooking_raw_data = google_api.get_all_data_from_sheet(SHEET_NAME, "요리")
cooking_data = self.get_cooking_list(cooking_raw_data)
user_raw_data = google_api.get_all_data_from_sheet(SHEET_NAME, "플레이어 데이터")
user_data = self.get_user_data_dict(user_raw_data)
comment_raw_data = google_api.get_all_data_from_sheet(SHEET_NAME, "활동 랜덤 스크립트")
comment_data = self.get_comment_list(comment_raw_data)
#### 새로운 시트를 추가할 경우 이 아래에 넣어주세요 ####코드 작성을 위한 함수를 간단히 설명하면 다음과 같습니다.
google_api.get_all_data_from_sheet(SHEET_NAME, "page_name"):
시트의 특정 페이지(시트)의 모든 데이터를 list[dict]의 형태로 불러옵니다.
이때 dict는 구글 시트의 최상단 row1의 목차를 그대로 가져옵니다. 그대로 사용하셔도 좋고, 저처럼 아래쪽에서 데이터를 가공하셔도 좋습니다. 저는 장비가챠 및 몬스터의 등급을 분류하는 코드를 사용하였기 때문에 한번 더 가공을 거쳤습니다.
구글 시트 데이터 구조 참고 페이지 : https://www.analyticsvidhya.com/blog/2020/07/read-and-update-google-spreadsheets-with-python/
- 불러온 데이터를 sheet_data 에도 추가한다.
예를 들어 새로운 데이터 시트 이름이 "채집" 이고 이를 "채집"이란 이름으로 저장하고 싶을 경우,
gathering_raw_data = google_api.get_all_data_from_sheet(SHEET_NAME, "채집")
를 선언한 후
sheet_data = dict(
장비=equipment_data,
사냥=hunting_data,
낚시=fishing_data,
요리=cooking_data,
플레이어=user_data,
코멘트=comment_data,
채집=gathering_raw_data
)에도 가장 밑에 추가해줍니다.
- update_tweet 에서 sheet_data["데이터목록이름"]으로 필요한 때에 데이터를 불러온다.
elif task_name == "[낚시]":
print("낚시 시작")
user_bites = sheet_data["플레이어"][user_id].떡밥
fishing_comments = sheet_data["코멘트"]["낚시_멘트"]예를 들면 위에서 [낚시] 키워드에서 sheet_data["코멘트"]["낚시 멘트"]를 불러오면 bot-data-example 시트의 코멘트 페이지의 "낚시 멘트" 행의 데이터를 쭉 불러옵니다.
- 아직 시트의 데이터가 업데이트될 때마다 자동으로 데이터를 업데이트하는 기능은 없기 때문에 시트에 변경된 데이터를 저장하고 싶다면 봇을 정지 후 재가동해야합니다.
💡주의!
데이터 시트의 header는 띄어쓰기를 포함하면 안됨!
띄어쓰기가 필요할 경우 _ 를 이용하여 띄어쓰기를 표현해줍니다.
시트를 새롭게 변경하여 데이터를 업데이트하고 싶으실 경우 봇을 재가동해야합니다.
- 유저 데이터 업데이트를 확인하기 위해 다음 페이지로 간다.
2. 입문자를 위한 자세한 설명
데이터와 관련해서는 어렵게 설명하면 한없이 어렵게 설명할 수 있기 때문에 최대한 간결하게 필요한 것들만을 설명하는 것으로 이 페이지를 구성하고자 합니다.
제 프로젝트는 다음의 목적을 최우선으로 작성되었습니다.
- 누구라도 편하게 수정 및 추가가 가능한 코드
- 성능을 일부 포기하더라도 범용성이 넓은 코드
위의 두 원칙은 제 코드가 python 코딩 convention (전통인데 기본 구조라고 이해하시면 됩니다.)에서 일부 벗어난 지점이 있는 것에 대한 변명입니다. 사실 변명이라고 해도 왜 이런 선택을 했는지 설명할 기회가 되면 설명하여 여러분이 코드를 익히는데 도움이 되고자 합니다.
구글 스프레드 시트로부터 데이터를 얻어오는 과정은 크게 아래와 같습니다.
- 허용된 시트로부터 데이터 받아오기
- 데이터를 사용하기 편한 방식으로 가공하기
이에 대한 설명을 [요리] 키워드를 중심으로 설명하겠습니다.
1. 허용된 시트로부터 데이터 받아오기.
1의 과정은 이미 [1] Authetification에서 일부 다뤘습니다. gcp의 dash board에 들어가면 구글 인증시 만들어진 계정 계정이 있을텐데요
ex.
server-dice@server-burangza.iam.gserviceaccount.com해당 계정을 사용할 시트의 공유하기에서 이메일로 추가하면 됩니다.
이렇게 연결한 시트는 만들어둔 google_api 를 통해 불러오는데 다음의 코드를 통해 특정 스프레드의 시트에 속한 데이터를 모두 불러올 수 있습니다.
google_sheet = self.client.open(spread_name)
# Extract and print all of the values
sheet = google_sheet.worksheet(sheet_name)
raw_data = sheet.get_all_records()구글 시트의 코드는 트위터 api와는 조금 다르게 api 로 모든 것을 해결하는게 아니라는 점이 조금 낯서게 느껴질 수도 있습니다. 하지만 구조를 살펴보면 그렇게 어렵지 않습니다.
구글 api 는 트위터보다 안전하게 만들어졌습니다. 트위터는 하나의 api 로 모든 명령을 수행하지만 구글 api 는 트위터보다 커다란 프로젝트로 프로젝트의 포함관계를 명확히 명시하다보니 저런식으로 코드가 구성됩니다.
하나의 스프레드 시트는 여러개의 work sheet를 가지고 각각의 work sheet에는 우리가 작성한 데이터가 작성되어있습니다. 그러니까 그 데이터에 접근하고 싶다면 api 로부터 spread sheet>work sheet> data 로 순차적인 접근을 하라는 것이 해당 api 의 목적이고 그에 따라 작성된 코드가 위의 코드입니다.
각각의 하위 데이터에 접근하려면 그 상위 데이터를 선언해야하는 구조입니다. 낯설 수 있지만 이 구조가 익숙해지면 대부분의 데이터 베이스와 api 를 이해하실 수 있을 것이고 그 구조를 이해하면 백엔드 프로그래머를 노려보셔도 좋습니다.
💡 요약
- 구글 api 는 트위터와 다르게 철저한 계층 구조를 가진다. 특정 시트의 데이터에 접근하기 위해선 api > 파일 > 시트 > 데이터 순서로 접근해야한다.
- 구글 스프레드 시트 api 와 관련된 정보를 더 알고 싶다면 아래의 링크를 확인하세요!
https://github.com/burnash/gspread
2. 데이터를 사용하기 편한 방식으로 가공하기
이렇게 접근한 데이터는 각 열을 맨 첫줄에 명시된 이름의 특성을 갖는 물체들로 인식하여 물체들의 list로 값을 돌려줍니다. 무슨 뜻인지 모르겠다면 아래의 예시를 보세요.

data-bot-example에 저장된 시트의 내용을 api는 다음과 같은 목록을 우리가 지정한 'raw_data'라는 이름 안에 저장합니다.
- 이름: 고수가재버거, 음식 설명: 고수와~, 들어간 재료: 고수, 가재, 빵
- 이름: 타비오카라면, 음식 설명: 타피오카의~, 들어간 재료: 타피오카, 라면
- 이름: 마라아이스크림, 음식 설명: 얼큰한 아이스크림, 들어간 재료: 마라, 붕어
그리고 각각의 음식은 0부터 차례대로의 순번을 갖습니다. 다시 정리하면 아래와 같습니다.
- 이름: 고수가재버거, 음식 설명: 고수와~, 들어간 재료: 고수, 가재, 빵
- 이름: 타비오카라면, 음식 설명: 타피오카의~, 들어간 재료: 타피오카, 라면
- 이름: 마라아이스크림, 음식 설명: 얼큰한 아이스크림, 들어간 재료: 마라, 붕어
이렇게 저장된 음식들은 dict이라는 데이터 형태로 저장됩니다. dict 는 dictionary 의 줄임말입니다.
사전이 이름과 정의를 모아둔 책인 것처럼, dict 이라는 구조형은 '이름'과 '내용'을 담고 있는 구조입니다.
정리하면 저 위의 데이터들에서 이름은 '이름, 음식 설명, 들어간 재료'가 되겠고, 그 내용이 자세한 설명들이 되겠습니다. 그리고 이러한 dict 구조에서 특정한 값을 가져올 때는 대괄호를 사용합니다.
예를 들어, 고수가재버거의 음식 설명을 가져오고 싶다면, 우리가 raw_data라고 선언한 전체 구조의 0번째에 들어있고, 그 중에서도 음식 설명을 읽어오고 싶은 것이니 아래의 코드로 불러오면 됩니다.
raw_data[0]["음식_설명"]그럼 이제 이 목록들 중에서 랜덤하게 하나의 음식을 가져오고 싶다면 어떻게 해야할까요? 이전에 배웠던 randint 라는 함수를 기억하나요? 우리는 randint를 이용하여 아래의 논리 순서로 코드를 작성할 것입니다.
- 전체 요리 목록 개수 중 랜덤한 숫자 1을 가져온다. = 목록의 랜덤한 색인을 가져온다.
- 해당 색인에 해당하는 음식을 가져온다.
- 가져온 음식을 트윗으로 보낸다.
이때, 우리가 사용하는 예제 시트에서는 음식이 단 3개 뿐이므로 randint 의 범위를 직접 (0, 2) 라고 작성해도 큰 문제가 없습니다. 하지만 만약 시트의 내용이 매우 많아져서 세기 힘들어 진다면? 혹은 시트를 지속적으로 시트를 추가할 예정이라면?
시트를 수정할 때마다 숫자를 계속 바꿀 건가요? 그럴 순 없습니다. 그래서 우리는 새로운 도구를 사용할 겁니다. len()이라는 함수입니다.
len() 는 list의 개수를 알려주는 함수입니다. 즉, len(raw_data)는 숫자 3을 돌려줍니다. 이를 이용해서 코드를 짜면 아래와 같습니다.
value = randint(0, len(raw_data) - 1)
dish = raw_data[value]
result_comment = comment_list[randint(0, len(comment_list) - 1)]
return f'[{dish["음식명"]}]\n들어간 재료: {dish["들어간_재료"]}\n{dish["음식_설명"]}\n\n한줄평: {result_comment}'💡 요약
- 구글 스프레드 시트에 저장된 데이터는 dictionary(사전) 구조의 배열(list)로 저장된다.
- list 는 0부터 시작하는 색인을 가지며, dictionary는 특성의 이름(=key)로 접근 가능하다.
- 두 데이터 구조 모두 대괄호[]를 통해 데이터에 접근한다.
- 예를 들어, raw_data에서 마라아이스크림의 재료를 가져오고 싶다면 아래와 같이 코드를 작성한다!
raw_data[2]["들어간_재료"]
이제 위의 코드를 키워드를 감지하는 elif 구문 안에 넣어서 아래와 같이 코드를 완성하면 봇은 [요리]라는 키워드를 받았을 때 구글 스프레드 시트의 랜덤한 요리 결과를 보내줍니다.
value = randint(0, len(cooking_data) - 1)
dish = cooking_data[value]
result_comment = comment_list[randint(0, len(comment_list) - 1)]
reply_comment = f'[{dish["음식명"]}]\n들어간 재료: {dish["들어간_재료"]}\n{dish["음식_설명"]}\n\n한줄평: {result_comment}'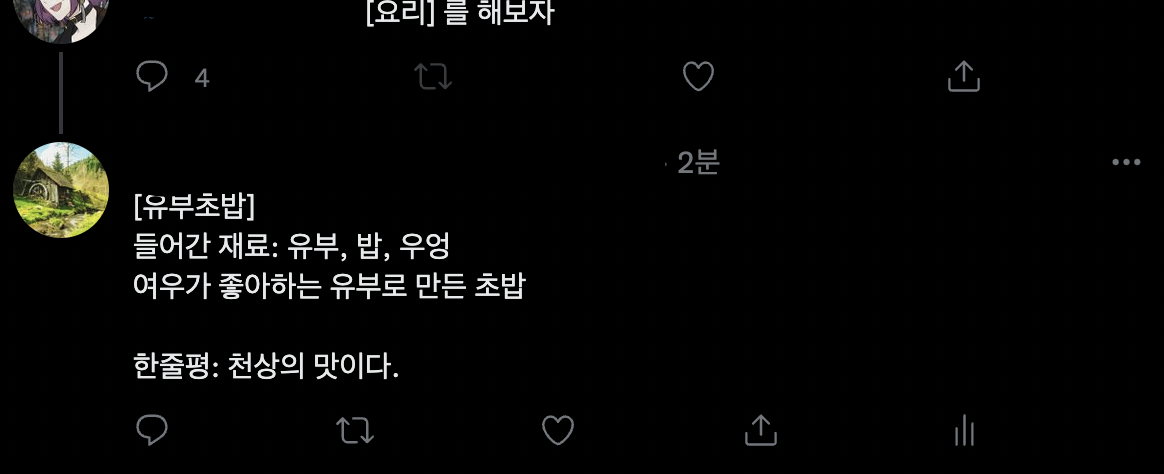
여기까지 오셨다면 이제 구글 스프레드 시트와 연동하여 보다 다채로운 문장들을 구사하실 수 있게 되었습니다. 다음 글에서는 마지막으로 플레이어의 데이터를 저장하고 처리하는 기능에 대해 이야기해보도록 하겠습니다!😎
