.png)
🐶 시스템 구조
우리 알려줄게 시스템은 컴퓨터 공학과 관련된 질문을 기계독해를 이용하여 답을 알려주는것을 목표료 한다.
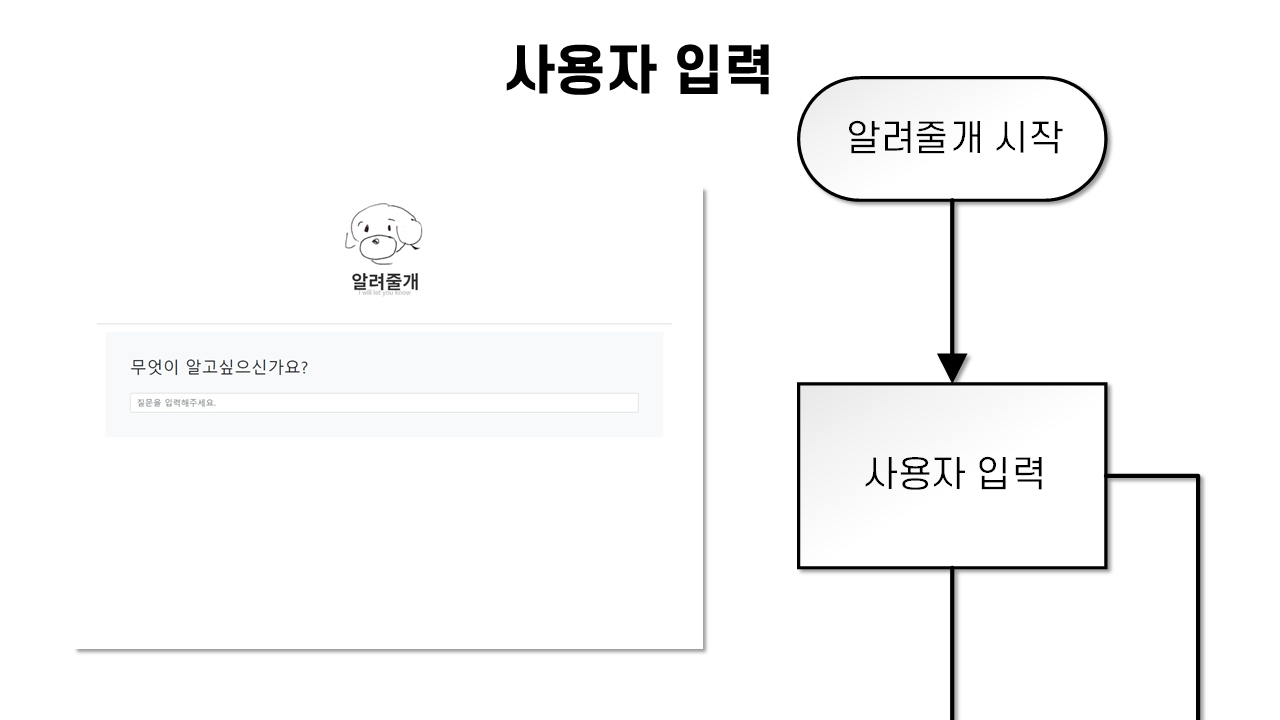
우선 사용자가 궁금해 하는 질문을 받게 된다.
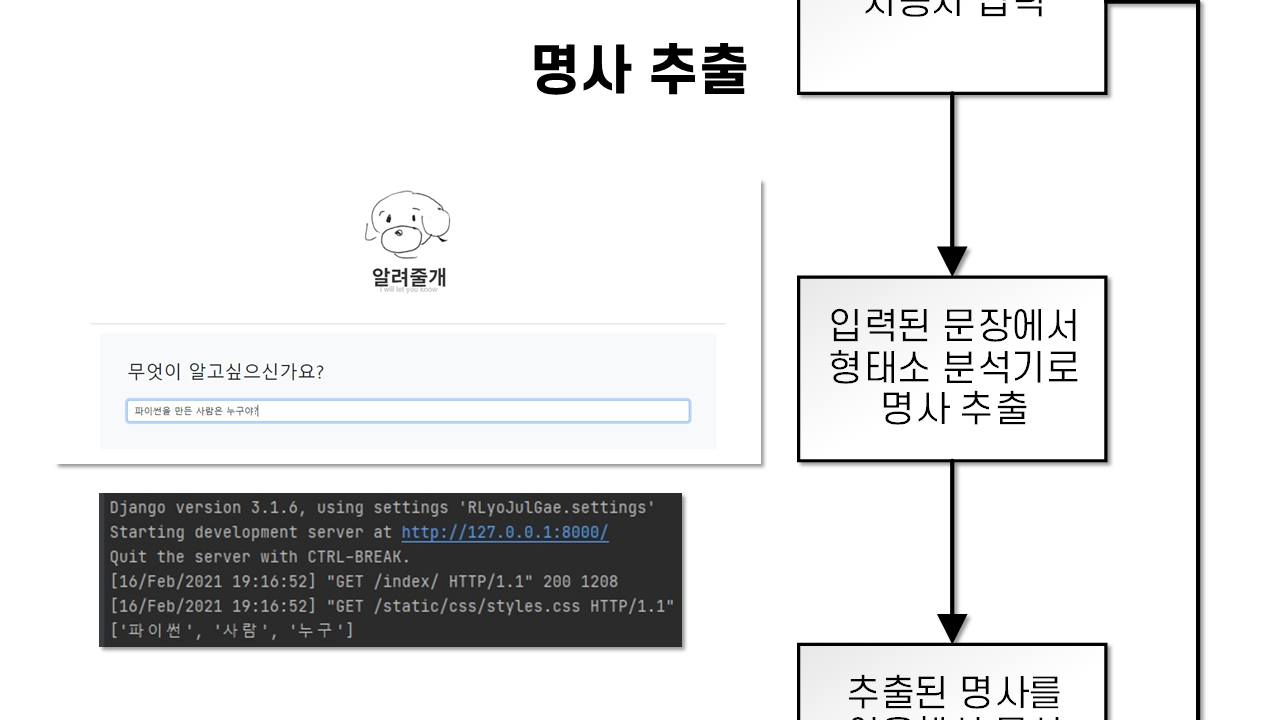
질문을 받게 된다면 우선 질문을 찾기 전 질문의 답이 있을만한 문서를 검색해햐 하는데 검색을 위해서 입력된 질문중 명사를 추출하여 검색 키워드를 만들게 된다.

전 단계에서 추출된 명사를 이용하여 BM25 알고리즘을 이용, 문서를 검색하게 된다.
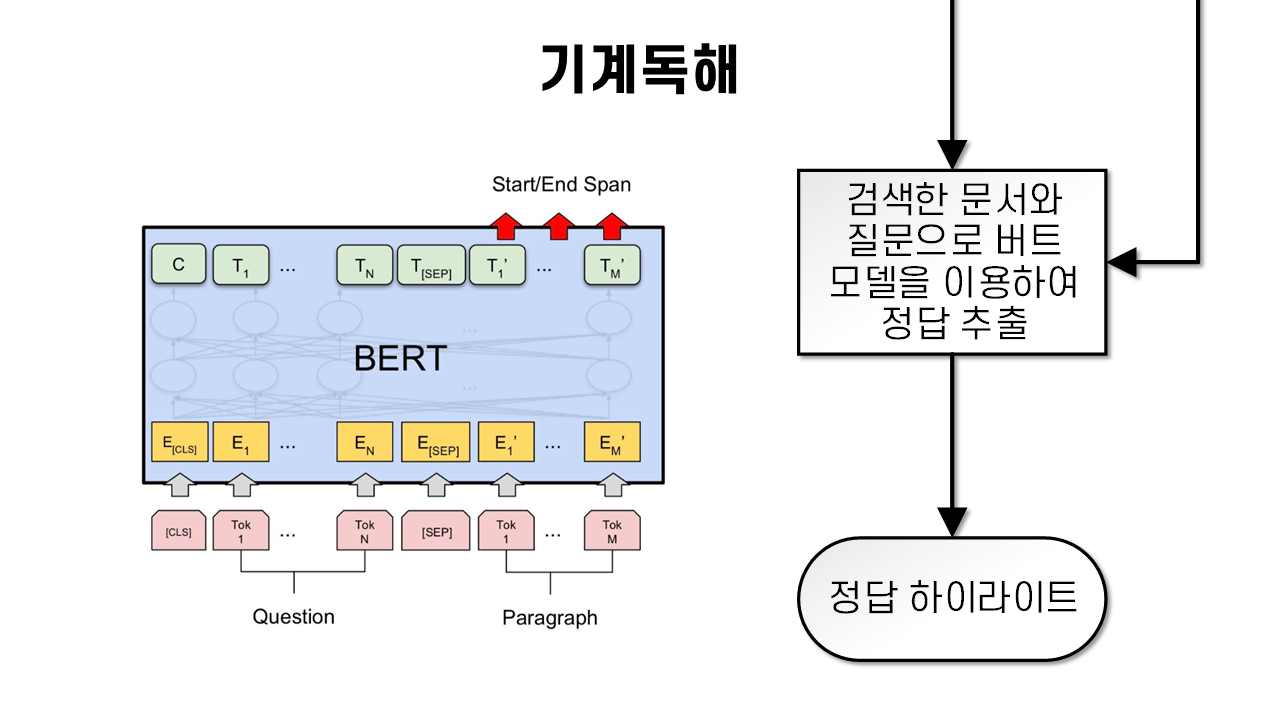
기존 제작해둔 버트 기계독해 모델을 이용하여 사용자가 입력한 질문 문장과 정답이 있을만한 문단을 입력하여 정답의 위치를 찾아내게 된다.
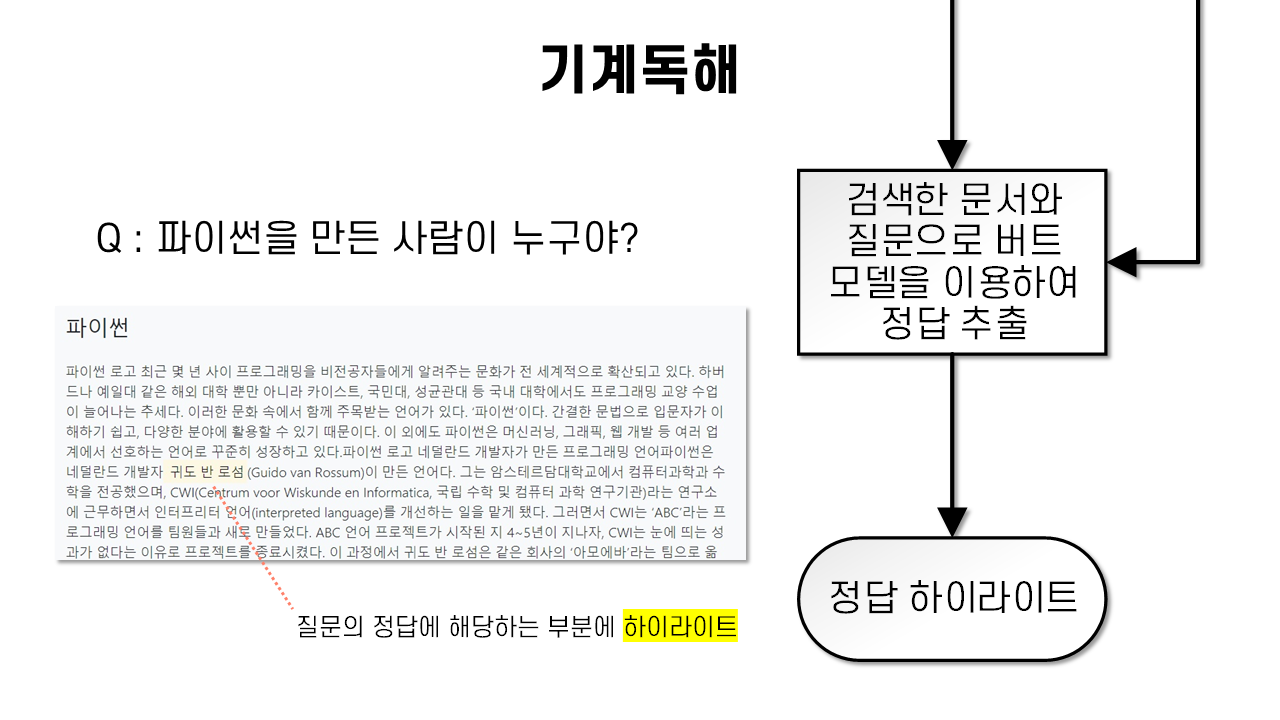
찾아낸 위치를 프론트엔드에서 하이라이트를 넣음으로써 질문에 대한 답을 빠르게 찾을수 있도록하였다.
⚓ 데이터 수집
관련된 데이터를 어디서 구할지 찾다가 네이버 지식백과에서 크롤링 하는 방향으로 가게 되었다.
from bs4 import BeautifulSoup
import requests
from tqdm import tqdm1
import unicodedata
import json
import pandas as pddocs = set()URL 구조가 카테고리id 디와 cid 로 목록이 분류 되어있고
게시글 아이디로 상세 게시글을 볼수 있게 되어있어서
우선 게시글 아이디들을 가져온다음에 상세 게시글에서 전부 크롤링하는 방향으로 크롤링 하게 되었다.
cid = 40942
categoryId = 32827targetAdress = "https://terms.naver.com/list.nhn?cid=" + str(cid) + "&categoryId=" + str(categoryId) + "&page="
maxRange = 1400for i in tqdm(range(1, maxRange)) :
webpage = requests.get(targetAdress + str(i))
soup = BeautifulSoup(webpage.content, "html.parser")
if int(soup.find(attrs={'class':'paginate'}).find('strong').text) != i:
break;
for data in soup.find(attrs={'class':'content_list'}).find_all(attrs={'class':'title'}) :
target = data.find('a').get('href')
start = int(target.find("docId="))
end = int(target.find("&cid"))
docs.add(int(target[start + 6:end])) 8%|███████████▍ | 114/1399 [00:30<05:48, 3.68it/s]datas = list()targetAdress = "https://terms.naver.com/entry.nhn?docId="+ str(docId) + "&cid=" + str(cid) + "&categoryId=" + str(categoryId)
webpage = requests.get(targetAdress)
soup = BeautifulSoup(webpage.content, "html.parser")
#제목
title = unicodedata.normalize("NFC", soup.find(attrs={'class':'size_ct_v2'}).get_text(strip=True))title'인공위성이란 인간에 의해 지구 또는 다른 천체의 주변을 회전하도록 만들어진 물체를 말한다.\n\t\n\t나아가 넓은 의미에서 보면, 궤도 비행을 하는 우주 왕복선, 우주 정거장, 스페이스 캡슐 또한 인공위성이라 할 수 있다.\n\t\n\t인공위성은 주로 로켓을 통하여 궤도에 진입하고 이후엔 만유인력에 따른 회전력으로 궤도상에서 지구주위를 회전한다.'for docId in tqdm(docs):
targetAdress = "https://terms.naver.com/entry.nhn?docId="+ str(docId) + "&cid=" + str(cid) + "&categoryId=" + str(categoryId)
webpage = requests.get(targetAdress)
soup = BeautifulSoup(webpage.content, "html.parser")
#제목
title = unicodedata.normalize("NFC", soup.find(attrs={'class':'headword'}).get_text(strip=True))
#본문
main = unicodedata.normalize("NFC", soup.find(attrs={'class':'size_ct_v2'}).get_text(strip=True))
dic = {'source' : 'https://terms.naver.com','cid': cid, 'categoryId':categoryId, 'docId': docId,'title': title, 'main':main}
datas.append(dic)100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1705/1705 [10:24<00:00, 2.73it/s]df = pd.DataFrame(datas)df.to_excel('naver_tech_it4.xlsx')📑 문서검색
우선 기계독해를 하기위해서 필요한 지문을 검색하기위해서 검색어를 만들기 위해
질문 내용중에서 검색에 필요한 단어들만 추출하는것이 필요하여 주체를 찾아야 했다.
👴 낡고 오래된 방식

처음 생각한 방식은 한국어의 형태가 조사로 각각의 단어의 문법적 기능을 책정한다는 개념에서 착안하여 주격 조사인 '은', '는,' '이', '가' 와 목적격 조사인 '을', '를' 앞에 위치하는 단어를 추출 하는 방식을 사용했었다.
이 방식은 빠른 속도와 쉬운 개발이라는 장점이 있었지만.
만약 마지막이 정규식에 포함되는 글자를 가진 단어가 존재한다면 해당 단어는 추출 할수 없는 단점이 존재하여 형태소 분석기 쪽으로 개발 하게 되었다.
🌊 MeCab 형태소 분석기
❓ 왜 메캅을 사용했는가?
여러 한국어의 형태소를 분석해주는 분석기들이 존재하지만.
속도가 빠르고 안정적인 성능을 내주던 메캅을 사용하게 되었다.
형태소 분석기로 분석된 명사를 추출하여 문서 검색에서 사용하는것이 목표이다.
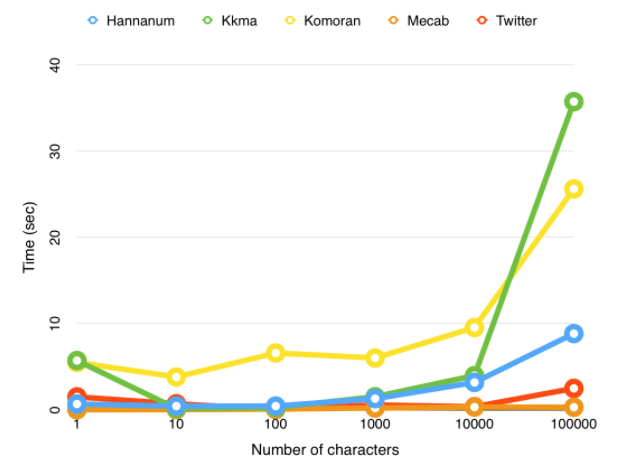
형태소분석기들에 관련된 블로그 주소
https://velog.io/@hsoh0423/%EC%B7%A8%ED%96%A5%EC%A0%80%EA%B2%A9-%ED%98%95%ED%83%9C%EC%86%8C-%EB%B6%84%EC%84%9D%EA%B8%B01
😓 도메인에 해당하는 고유명사를 분해하지 못함

하지만 메캅 형태소 분석기는 영어나 고유명사의 경우 명사쪽 분류가 되는것이 아니였기 때문에
사용자 사전 기능을 활용하여 이를 해결하게 되었다.
👥 사용자 사전

위에서의 문제를 해결하기 위해서 사용자 사전 추가를 하여 해결하게 되었다.
우리가 사용하는 데이터들이 네이버 지식 백과에 속해있고
아래의 데이터의 형태가 제목이 해당문서의 용어이고 본문이 해당문서를 설명하는 방식 이었기 때문에 제목부분을 사용자 사전에 넣는 방향으로 진행하게 되었다.

아래는 사용자 사전을 추가할때 썼던 코드
from tqdm import tqdm
import pandas as pd
import reexcel_data = pd.read_excel('naver_it2.xlsx', engine ='openpyxl')titles = excel_data[['title']]
print(titles)
print(type(titles)) title
0 MP4
1 HEIF(고효율 이미지 파일 형식)
2 iOS9
3 무선 디스플레이 전송 기술
4 캐리어 어그리게이션
... ...
33738 콜백
33739 CSS
33740 CMS
33741 광석라디오
33742 CISA
[33743 rows x 1 columns]
<class 'pandas.core.frame.DataFrame'># 괄호 내부는 사용하지 않기 위해서 정규식을 이용하여 표기
rea = re.compile("\([^\(\)]+\)")li = []
for title in titles['title']:
if (rea.search(title)):
m = rea.search(title)
if (m.start() < m.end()) :
li.append(title[:m.start()] + " "+ title[m.start() + 1:m.end() -1])
else:
li.append(title)text = "(고효율 이미지 파일 형식)"
m = rea.search(text)
print(m)<_sre.SRE_Match object; span=(0, 15), match='(고효율 이미지 파일 형식)'>if (m.start() < m.end()) :
text = text[m.start() + 1:m.end() -1]for title in titles['title']:
print(title)출력된 제목들 목록
MP4
HEIF(고효율 이미지 파일 형식)
iOS9
무선 디스플레이 전송 기술
캐리어 어그리게이션
찰스 시모니
URL
유심(USIM)
프로덕트 레드
칸아카데미
핫스팟
DNS한글 여부를 파악하기 위한 부분
from hanja import hangulhangul.is_hangul("1")Falsezong = []
for data in li4:
char = data[-1:]
if hangul.is_hangul(char) :
if (hangul.separate(char)[2] != 0):
zong.append("T")
else:
zong.append("F")
else:
zong.append("F")df2 = pd.DataFrame({'A': pd.Categorical(li4),'B': "0",'C': "0",'D': "0", 'E':"NNP", 'F':"*",
'G': pd.Categorical(zong), 'H': pd.Categorical(li4), 'I':"*", 'J':"*", 'K':"*", 'L':"*", 'M':"*"})df2.to_csv("userDic", header = False, encoding = 'utf-8', index = False)csv 파일로 저장하고 사용자 사전을 지정하였다.
메캅 품사 태그 설명
https://docs.google.com/spreadsheets/d/1-9blXKjtjeKZqsf4NzHeYJCrr49-nXeRF6D80udfcwY/edit#gid=6
메캅 사용법
https://velog.io/@kjyggg/%ED%98%95%ED%83%9C%EC%86%8C-%EB%B6%84%EC%84%9D%EA%B8%B0-Mecab-%EC%82%AC%EC%9A%A9%ED%95%98%EA%B8%B0-A-to-Z%EC%84%A4%EC%B9%98%EB%B6%80%ED%84%B0-%EB%8B%A8%EC%96%B4-%EC%9A%B0%EC%84%A0%EC%88%9C%EC%9C%84-%EB%93%B1%EB%A1%9D%EA%B9%8C%EC%A7%80
📚 사용자 사전이 추가된후

기존에 mp3 를 고유명사로 분류하지 못했던 것과는 달리 사용자 사전 추가로 mp3 를 고유명사로 분류 할 수 있게 되었다.
💽 문서 검색 알고리즘

문서 검색에서 사용되는 어려 알고리즘이 존재하는데 그중 BM25를 선택하게 되었다.
기존에 사용하던 TF-IDF 알고리즘은 문서들중 적게 쓰인 단어가 많이 있다면 높은 가중치를 주는 알고리즘의 형태인데 특정 단어가 많이 나타나는 경우에 오히려 문서 검색의 정확도가 낮아지는 경우가 발생하곤했다.
BM25는 특정 단어가 많이 나타나는 경우에 대한 영향력의 제한을 주는 알고리즘이다.
이 알고리즘을 이용하여 문서를 검색하게 되었다.
from rank_bm25 import BM25Okapi
bm25.get_top_n(토큰화 된 검색어, 검색할문서들, n=찾을 문서의 개수)위 라이브러리를 사용하여 BM25 알고리즘을 활용한 검색을 할수 있다.
🤖 기계독해
기계 독해는 컴퓨터에게 지문을 읽고 해석하여 문제를 해결할수 있도록 학습 시키는 것이 목표이다. 이것을 구현하기 위한 요소를 소개해 보고자 한다.
🇰🇷 KoQUAD
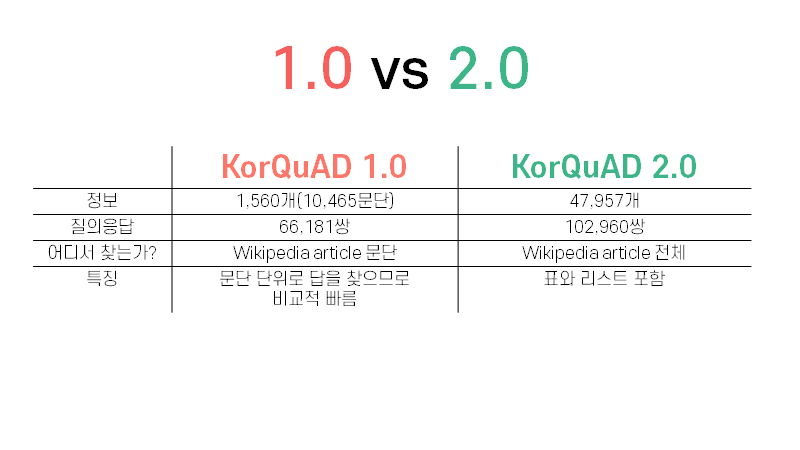
코쿼드 데이터 셋은 질문과 질문을 찾을 본문 그리고 답으로 이루어진 데이터 셋이다.
데이터 구조상은로 2.0은 표와 리스트를 포함하기 때문에 기본적인 버트 모델에서는 성능이 1.0 에 비해 잘나오지 못한다. 간단한 형태인 데이터를 고려하여 1.0으로 학습하게 되었다.
🦾 마인즈랩 기계독해 데이터
https://aihub.or.kr/aidata/86
이 데이터는 사용하지는 않았지만 사용할수 있을것같아서 첨부.
🧈 버트로 기계독해
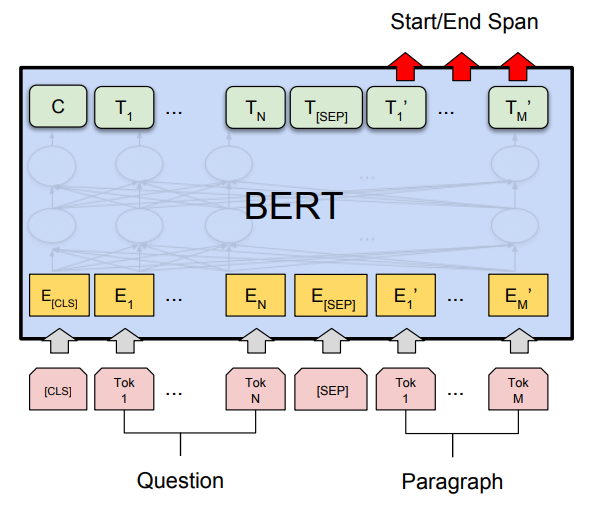
위의 코드를 기반으로 버트로 기계독해를 구현하였고 KoQUAD 1.0 데이터로 학습하였다.
파인 투닝을 별로도 하지는 않았지만 어느정도의 성능이 나와주어 마무리 하게되었다.

대단하십니다