
크롤링이 뭔가 싶어서 이것저것 찾아 보던 중에 웹 크롤러 좀 그만만들어라 이런 글을 발견했다. 기능학습하기 전에 크롤링이 뭔지, 내가 하려는게 뭔지에 대한 이해를 위해서 읽어보기 괜찮은 글이다. 그리고 내가 쓰려는 글은 '그만 만들어야 하는 크롤러' 기능학습을 한 후 사용법을 정리하는 글이다...
크롤링
크롤링의 원리는 http reuqest을 했을 때 받은 데이터에서 필요한 요소를 추출하는 것이다.
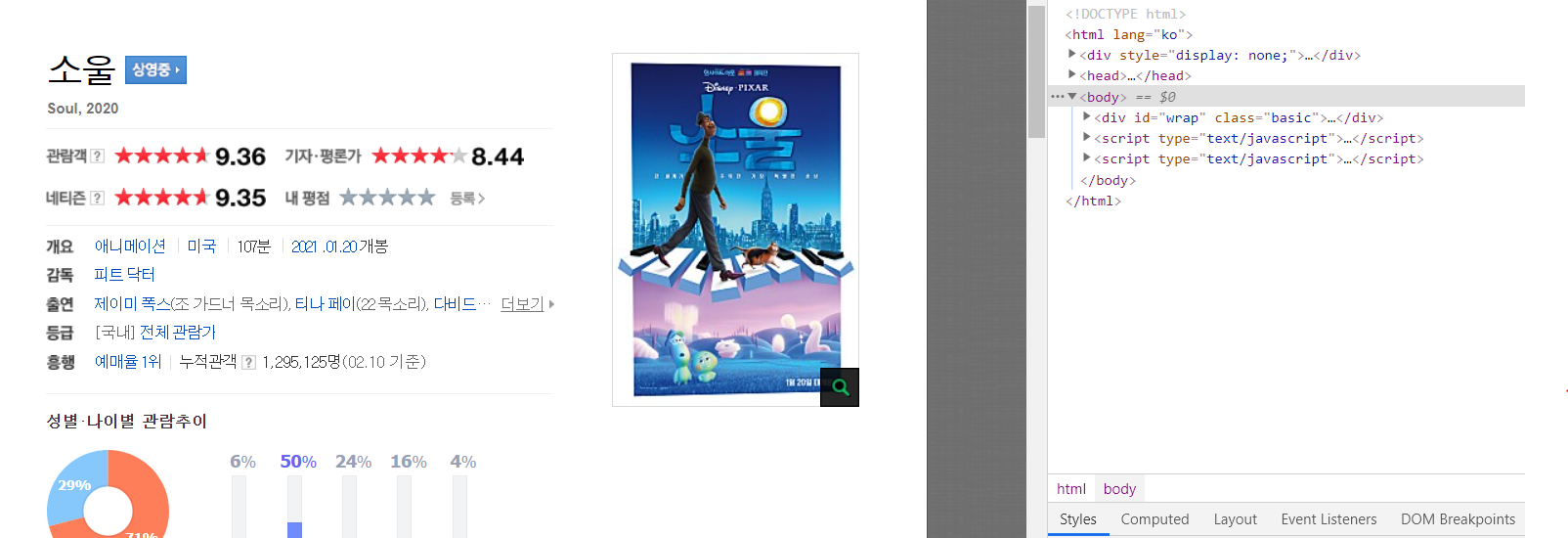
네이버 영화에서 '소울'을 검색하면 나오는 결과다. html DOM?에서 필요한 데이터를 meta data나 css selecotor를 이용해 추출한다.
requests로 브라우저를 통하지 않고 요청을 하고, beautiful soup4로 필요한 element를 추출하는 방법을 학습했다.
beautifulsoup
데이터를 추출하는 파이썬 라이브러리다.
데이터를 가지고 오는 두가지 방법
meta tag
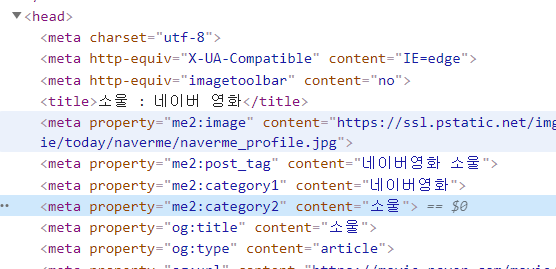
import requests
from bs4 import BeautifulSoup
url = 'https://movie.naver.com/movie/bi/mi/basic.nhn?code=184517#'
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(url,headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
title = soup.select_one('meta[property="og:title"]')['content']
image = soup.select_one('meta[property="og:image"]')['content']
desc = soup.select_one('meta[property="og:description"]')['content']
print(title, image, desc);html element
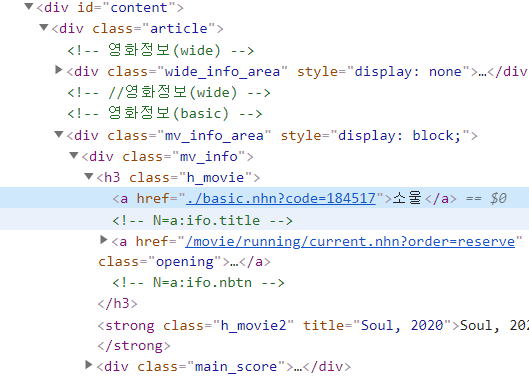
우클릭 > Copy selector
title = soup.select_one('#content > div.article > div.mv_info_area > div.mv_info > h3 > a:nth-child(1)').text추출하는 method
select_one
- 한개의 앨리먼트
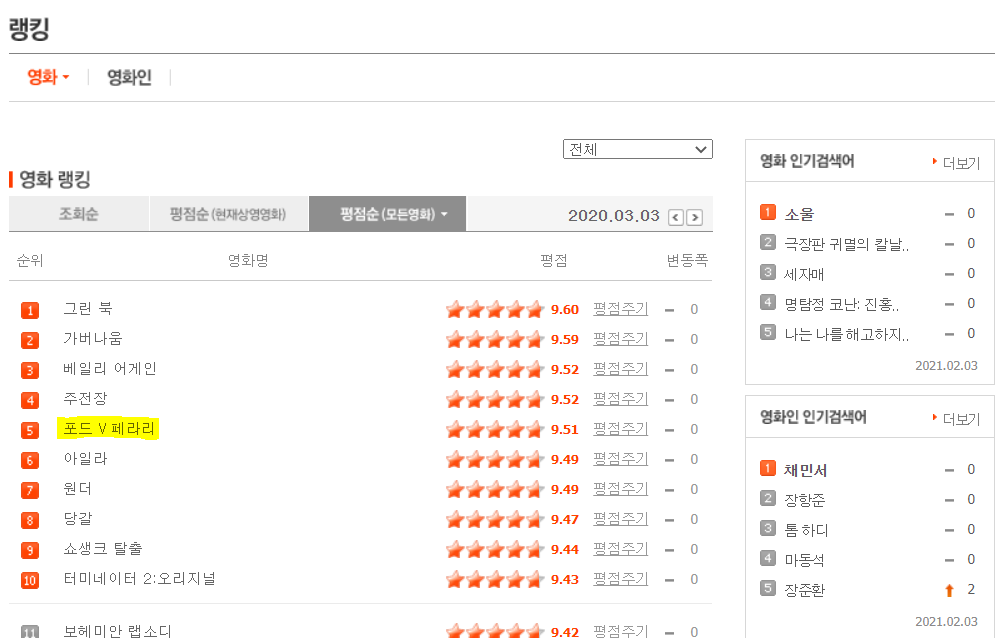
title = soup.select_one('#old_content > table > tbody > tr:nth-child(6) > td.title > div > a')
# 메타태그
# title = soup.select_one('meta[property="og:title"]')
print(title) #<a href="/movie/bi/mi/basic.nhn?code=181710" title="포드 V 페라리">포드 V 페라리</a>
print(title.text) # 그린북
print(title['href'] #/movie/bi/mi/basic.nhn?code=181710select
여러개의 element리스트를 가져온다. 각 영화내용은 tr태그 안에 들어있었으므로 tr을 가지고왔다.
#old_content > table > tbody > tr:nth-child(6) 원래는 tr을 선택해 copy selector하면 내가 선택한 항목이 tr의 몇번째 자식인지까지 나오는데, 이렇게 하면 select_one이 되므로 밑줄친 부분은 빼고 tr까지만 select에 넣어주도록 한다. 이렇게 가져온 lists의 각 요소 필요한 부분을 정확히 추출하기 위해 for문으로 select_one으로 다시 실행. 아래 소스로 네이버영화를 크롤링하면 구분선 부분은 None이 뜬다. 그래서 조건문으로 처리해줌. 사이트마다 다르므로 잘 보고 전략을 짜야한다.
lists = soup.select('#old_content > table > tbody > tr')
for tr in lists:
a_tag = tr.select_one('td.title > div > a') # tr tag 하위의 가져올 부분의 tag
if a_tag is not None:
print(a_tag)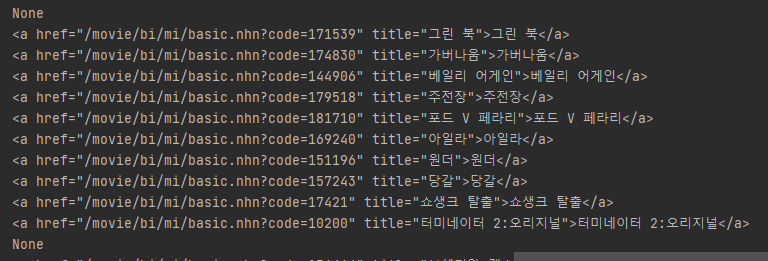
네이버영화 데이터 가져오기 예제 소스
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
lists = soup.select('#old_content > table > tbody > tr')
# old_content > table > tbody > tr:nth-child(6) > td.title > div > a
for tr in lists:
num = tr.select_one('td:nth-child(1) > img')
title = tr.select_one('td.title > div > a')
point = tr.select_one('td.point')
if num is not None:
print(num['alt'], title.text, point.text )📑 reference
- 스파르타 코딩클럽 웹개발 종합반
