EDA
03. 범죄
01. 결제정보 오류
-
구글맵을 사용해야 해서 구글에 gcp를 검색하고 클라우드를 들어갔다. 결제정보를 추가해야하는데 권한오류가 계속 발생했다.
-
아래 사진같은 오류가 발생하였음
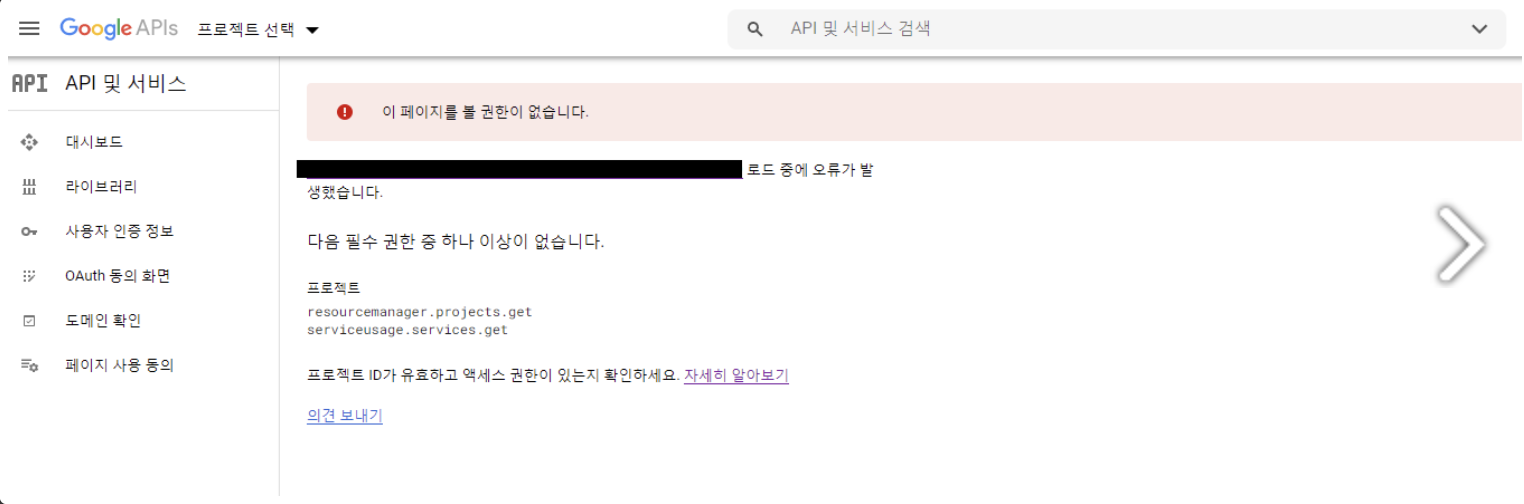
-
주소나 계정 정보 등 다 맞게 했는데도 계속 권한 오류가 발생해서 구글링을 해보았다.
-
먼저 클라우드에서 API서비스에 들어가면 API 및 서비스 사용설정이 있다. 여기에 들어가서 내가 사용할 API의 '사용' 버튼을 눌러준 후 다시 시도해보면 정상적으로 작동된다.
02. robust 오류
- 21강에서 해당 코드를 작성하고 실행했는데 ModuleNotFoundError: No module named 'statsmodels' 이런 오류가 생겼다
sns.set_style("darkgrid")
sns.lmplot(
x='x',
y='y',
data=anscombe.query("dataset == 'III'"),
robust=True,
ci=None,
height=7)
plt.show()- 뭔가 모듈이 없어서 그런 것 같다는 예상은 했지만 어떻게 해야할지 몰라 구글 검색을 해보았다
- 결론은 해당 모듈을 설치해주면 된다고 했다
- 아래 코드를 실행해서 설치해주었고 정상적으로 실행되었다
!pip install statsmodels03. invalid syntax
- 이 오류가 나면 대부분 괄호나 쉼표 등이 빠졌는지 체크해본다
04. 웹 데이터
01. HTTP Error 403: Forbidden
- request를 했을 때 권한이 막혀있기 때문에 해당 에러가 발생한다
- 해결 방법은 request headers를 통해서 user-agent값을 딕셔너리 형태로 가져와서 적어주면 해결된다
ex)
req = req = Request(row["URL"], headers={"user-agent":"Chrome"})- 여기서 "user-agent" : ua.ie 를 쓰면 랜덤으로 값을 돌려주게 된다
- 해당 코드로 처음에 작성하였는데 중간쯤에 403 오류가 지속적으로 발생하였고 "chrome"으로 변경해주니 정상실행되었다
- 네트워크의 문제였는지 확실히 알 순 없지만 ua.ie가 필요한 상황이 아니라면 "chrome"으로 작성하는 것이 더 안정적일 것 같다
05. 유가분석
01. selenium AttributeError 'Webdriver' object has no attribute 'find_element_by ... 에러
- 특정 지점까지 스크롤하는 코드를 짜는 중
driver.find_element_by_xpath()이 함수가 실행되지 않고 에러가 났다. 해당 에러는 셀레니움 상위버전이기 때문에 생기는 것이다.
- 이때는 기존의 코드를 사용하지 말고 다음처럼 임포트를 추가한다.
from selenium.webdriver.common.by import By- 이후 아래 예제처럼 사용한다.
elem = driver.find_element(By.NAME, "q")
title = driver.find_element(By.XPATH, r'//*[@id="bestList"]/ol/li[1]/p[1]').text- 실제 적용
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
some_tag = driver.find_element(By.XPATH, '''/html/body/div[2]/section/article/div[9]/nav/ul''')
action = ActionChains(driver)
action.move_to_element(some_tag).perform()02. css_selector
- 검색 버튼 클릭 동작을 xpath와 css_selector을 이용해서 실행하는중에 강의대로 css_selector로 코드를 짜면
NoSuchElementException 이런 오류가 생겼다
- 강의 시점과 현재의 웹사이트가 바뀌어서 오류가 난다
- 강의코드
'#header > div:nth-child(2) > button'- 검색결과 2번째 div에 input과 botton이 있는데 해당 하위들을 다 선택해주지 않아서 오류가 생긴 것 같다
- 하위 모든 요소를 선택하려면 숫자 옆에 n을 붙여줘야 한다
- 수정 코드
'#header > div:nth-child(2n) > button'- 이후 정상실행 되었다
참고했던 링크
06. 시계열 분석
could not convert string to float: '914 dividend'
- 네이버 주식 정보를 가져오면 주가의 타입이 object이기 때문에 float로 형전환이 필요했다
- 강의에 나온 코드를 그대로 따라했는데 위의 제목같은 오류가 났다
- 강의 코드
df["y"] = df["y"].astype("float")- 강의 당시 데이터와 지금 데이터가 다르기 때문이다. 중간에 '914 dividend'라는 데이터가 껴있어서 그렇다고 예상했다. loc 함수를 이용해서 해당 value을 가지고있는 index를 찾아보았다
d = df_target.loc[df_target["y"]=="914 Dividend"] # df_target은 원본데이터
d- d 실행결과

- 68번째 index를 삭제한 후 강의처럼 float형으로 형전환해주었다
df.loc[68]
df = df.drop(68, axis=0)
df["y"] = df["y"].astype("float")terminal
01. 업데이트 오류
- 맥북을 업데이트 한 후 터미널에 conda activate ds_study를 입력했는데 xcrun: error가 났다
- 서칭 결과 업데이트 한 후 종종 발생하는 오류라고 했다
- 터미널에 위의 명령어를 입력하여 설치해주면 해결된다
xcode-select --installSQL
3회차 sql 과제
문제 1. csv 파일에 저장된 세계 테러 데이터를 하나의 테이블에 저장하세요.
- 1번 문제는 정답 코드를 그대로 문제지에 주셨다. 그런데 create_engine을 생성하는 과정에서 계속 Invalid argument(s) 'encoding' sent to create_engine(), using configuration MySQLDialect_pymysql/QueuePool/Engine. Please check that the keyword arguments are appropriate for this combination of components 이런 오류가 발생했다
- encoding 부분이 오류가 있는 것 같았다
- 구글링 결과 밑의 코드처럼 수정하니 오류가 해결되었다는 사람이 있어서 똑같이 수정했고 오류가 해결되었다.
<before>
engine = create_engine(f'mysql+pymysql://{user}:{password}@{host}:{port}/{database}', encoding='utf-8')
<after>
engine = create_engine(f'mysql+pymysql://{user}:{password}@{host}:{port}/{database}?charset=utf8mb4')머신러닝
kernel died
-
머신러닝 20, 21번 파일을 강의와 똑같이 따라 실행하는 중 lightgbm, smote 등을 실행할 때마다 커넬이 죽었다
-
vscode, jupyter notebook 둘 다 실행해 보았는데도 해결되지 않았다
-
서칭 결과 가장 많이 말하고 있는 두가지 방법을 써보았는데 20번 파일은 되었지만 21번은 똑같이 kernel이 죽었다
-
첫번째 방법
- pip대신 conda로 install
- 기존의 모듈은 uninstall 해준 뒤 conda로 재설치
-
두번째 방법
- 터미널에 jupyter notebook --generate-config 친 후 경로 확인

- 이동 > 폴더로 이동 > 경로 복붙 후 검색
- jupyter_notebook_config.py에 들어가서 max_buffer_size=10000000000정도로 변경
- 터미널에 jupyter notebook --generate-config 친 후 경로 확인
-
이 두 방법 다 해보았는데 21번 파일은 왜 안되는지 도대체 모르겠다
머신러닝 과제
-
chromedriver을 써야하는데 버전이 맞지 않아 오류가 생긴다는 오류메시지가 떴다
-
chromedriver 다운로드 해당 링크에 들어가서 원하는 버전을 다운로드 해준다
-
압축을 풀고 사용하고싶은 폴더 안에 옮겨준다
-
그 후 실행을 해보았는데 '개발자를 확인할 수 없기 때문에 ‘chromedriver’을(를) 열 수 없습니다.' 라는 오류 메시지가 떴다
-
터미널을 열어주고 chromedriver가 있는 폴더까지 이동한 후 아래 코드를 입력해주었다
-
xattr -d com.apple.quarantine chromedriver -
입력 후 다시 실행해보니 정상작동 되었다
27. Titanic using PCA, Knn
- 마지막 부분에서 주인공들의 생존을 확인하기 위해 디카프리오와 윈슬렛의 데이터를 넣고 predict_proba를 해보았는데 아래와 같은 오류가 났다
X does not have valid feature names, but IsolationForest was fitted with feature name- 확인해보니 주인공들의 데이터 및 test데이터는 values로 이루어져있고 train데이터는 feature names가 있기 때문에 난 오류였다
- 따라서 train 데이터에도 values로 변경해준 후 코드를 실행해주면 오류가 나지 않는다
estimators = [('scaler', StandardScaler()),
('pca', PCA(n_components=3)),
('clf', KNeighborsClassifier(n_neighbors=20))]
pipe = Pipeline(estimators)
pipe.fit(X_train.values, y_train)
dicaprio = np.array([[3,18,0,0,5,1,1]])
print('Decaprio : ', pipe.predict_proba(dicaprio)[0,1])
winslet = np.array([[1,16,1,1,100,0,3]])
print('Winslet : ', pipe.predict_proba(winslet)[0,1])