Vision former ViT 논문 리뷰
https://arxiv.org/pdf/2010.11929
이미지의 가치는 16X16단어:
대규모 이미지 인식을 위한 트랜스포머
알렉세이 도소비츠키 , 루카스 바이어, 알렉산더 콜레스니코프, 더크 바이센본, Xiaohua Zhai∗, 토마스 운터티너, 모스타파 데하니, 마티아스 마인드레러,
게오르그 하이골드, 실뱅 겔리, 야콥 우스코레, 닐 홀스비 ,동등한 기술 기여, 동등한 조언
Google 리서치, 브레인 팀 {아도소비츠키, 닐홀스비}@google.com
ABSTRACT
트랜스포머 아키텍처는 자연을 위한 사실상의 표준이 되었지만, 언어 처리 작업, 컴퓨터 비전에서 트랜스포머 아키텍처의 적용은 여전히 제한적입니다. 비전 분야에서 어텐션(attention)은 컨볼루션 네트워크와 함께 적용되거나
컨볼루션 네트워크의 특정 구성 요소를 유지하면서 대체하는 데 사용됩니다
전반적인 구조가 마련되어 있습니다. CNN에 대한 이러한 의존도가 필요하지 않다는 것을 보여줍니다
이미지 패치 시퀀스에 직접 적용된 순수 변압기는 다음과 같은 성능을 발휘할 수 있습니다
이미지 분류 작업을 매우 잘 수행합니다. 대량의
데이터를 여러 중간 크기 또는 작은 이미지 인식 벤치마크로 전송합니다
(이미지넷, CIFAR-100, VTAB 등) 비전 트랜스포머(ViT)는 우수합니다
최첨단 컨볼루션 네트워크와 비교했을 때 훈련하는 데 훨씬 적은 계산 리소스가 필요한 결과입니다.1
1 소개
자기 주의 기반 아키텍처, 특히 트랜스포머(Vaswani et al., 2017)는 다음과 같이 되었습니다
자연어 처리(NLP)에서 선택하는 모델. 지배적인 접근 방식은 다음을 사전 교육하는 것입니다
대규모 텍스트 말뭉치를 사용한 다음 더 작은 작업별 데이터 세트를 미세 조정합니다(Devlin et al., 2019). 감사합니다
트랜스포머의 계산 효율성과 확장성을 위해 다음과 같은 모델을 훈련하는 것이 가능해졌습니다
100B 이상의 매개변수를 가진 전례 없는 크기(브라운 외, 2020; 레피킨 외, 2020). 그리고
모델과 데이터 세트가 성장하고 있지만 여전히 성능이 포화될 조짐은 보이지 않습니다.
그러나 컴퓨터 비전에서는 컨볼루션 아키텍처가 여전히 지배적입니다(르쿤 외, 1989;
크리제프스키 외, 2012; 그 외, 2016). NLP 성공에서 영감을 받은 여러 작품이 결합을 시도합니다
자기 주의를 기울이는 CNN과 유사한 아키텍처(왕 외, 2018, 카리온 외, 2020), 일부 대체 기능
컨볼루션 전체 (라마찬드란 외, 2019; 왕 외, 2020a). 후자의 모델은 다음과 같습니다
이론적으로 효율적이지만, 다음과 같은 이유로 인해 최신 하드웨어 가속기에서 아직 효과적으로 확장되지 않았습니다
특수 주의 패턴의 사용. 따라서 대규모 이미지 인식에서 고전적인 ResNetlike 아키텍처는 여전히 최첨단입니다(Mahajan et al., 2018; Xie et al., 2020; 콜레스니코프 등).
2020).
NLP에서 트랜스포머 확장 성공에서 영감을 받아 표준을 적용하는 실험을 진행합니다
가능한 한 최소한의 수정으로 이미지로 직접 변환합니다. 이를 위해 이미지를 분할합니다
는 패치로 만들고 이러한 패치의 선형 임베딩 시퀀스를 트랜스포머에 대한 입력으로 제공합니다.
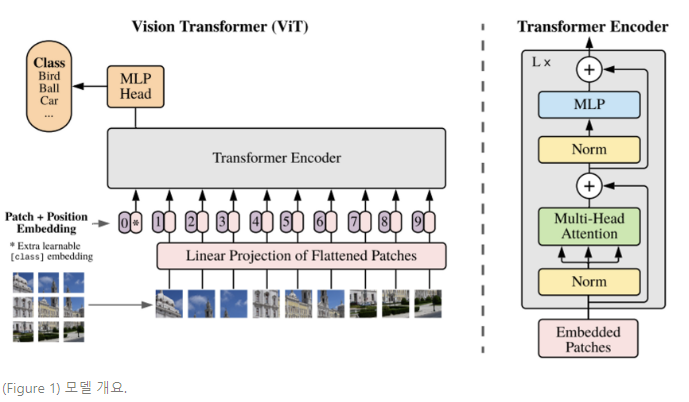
모델 개요.
이미지를 고정된 크기의 패치로 분할하고 각 패치를 선형으로 삽입합니다.
위치 임베딩을 추가하고 결과 벡터 시퀀스를 표준 변환기에 공급합니다.
인코더. 분류를 수행하기 위해 추가 학습 가능 항목을 추가하는 표준 접근 방식을 사용합니다.
"분류 토큰"을 시퀀스에 추가합니다. Transformer 인코더의 그림은 다음에서 영감을 받았습니다.
Vaswaniet al. (2017).
3. METHOD
모델 설계에서는 원래 Transformer(Vaswani et al., 2017)를 최대한 가깝게 따릅니다.
이렇게 의도적으로 간단한 설정의 장점은 확장 가능한 NLP Transformer 아키텍처와
효율적인 구현 – 거의 즉시 사용할 수 있습니다.
3.1 비전 트랜스포머(VIT)
모델의 개요는 그림 1에 나와 있습니다. 표준 Transformer는 1D 입력을 받습니다.
토큰 삽입 순서. 2D 이미지를 처리하기 위해 이미지 x ∈ R의 모양을 변경합니다.
H×W×C로
평평한 2D 패치의 시퀀스 xp ∈ R
N×(피
2
·기음)
, 여기서 (H, W)는 원본의 해상도입니다.
C는 채널 수, (P, P)는 각 이미지 패치의 해상도, N = HW/P2
는 패치의 결과 수이며, 이는 또한 유효 입력 시퀀스 길이 역할을 합니다.
변신 로봇. Transformer는 모든 레이어를 통해 일정한 잠재 벡터 크기 D를 사용하므로
패치를 평평하게 하고 기차를 사용하여 D 차원에 매핑합니다.
