
해당 포스트는 패스트 캠퍼스에 초격차 패키지 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE를 공부한 뒤 복습을 위해 각색하여 작성하였습니다.
01. 시작하며
이번 10번째 미니 프로젝트에서는 (제주도) 도로 교통량 분석 및 예측 모델을 만드는 실습을 진행했습니다.
특히, Feature Importance에 기반한 Feature Selection을 통해 feature의 숫자를 줄이며 모델링을 진행하는 과정을 배울 수 있었습니다.
그럼 먼저 간략하게 전체 진행과정을 소개해드리겠습니다!
02. 미니 프로젝트 진행과정
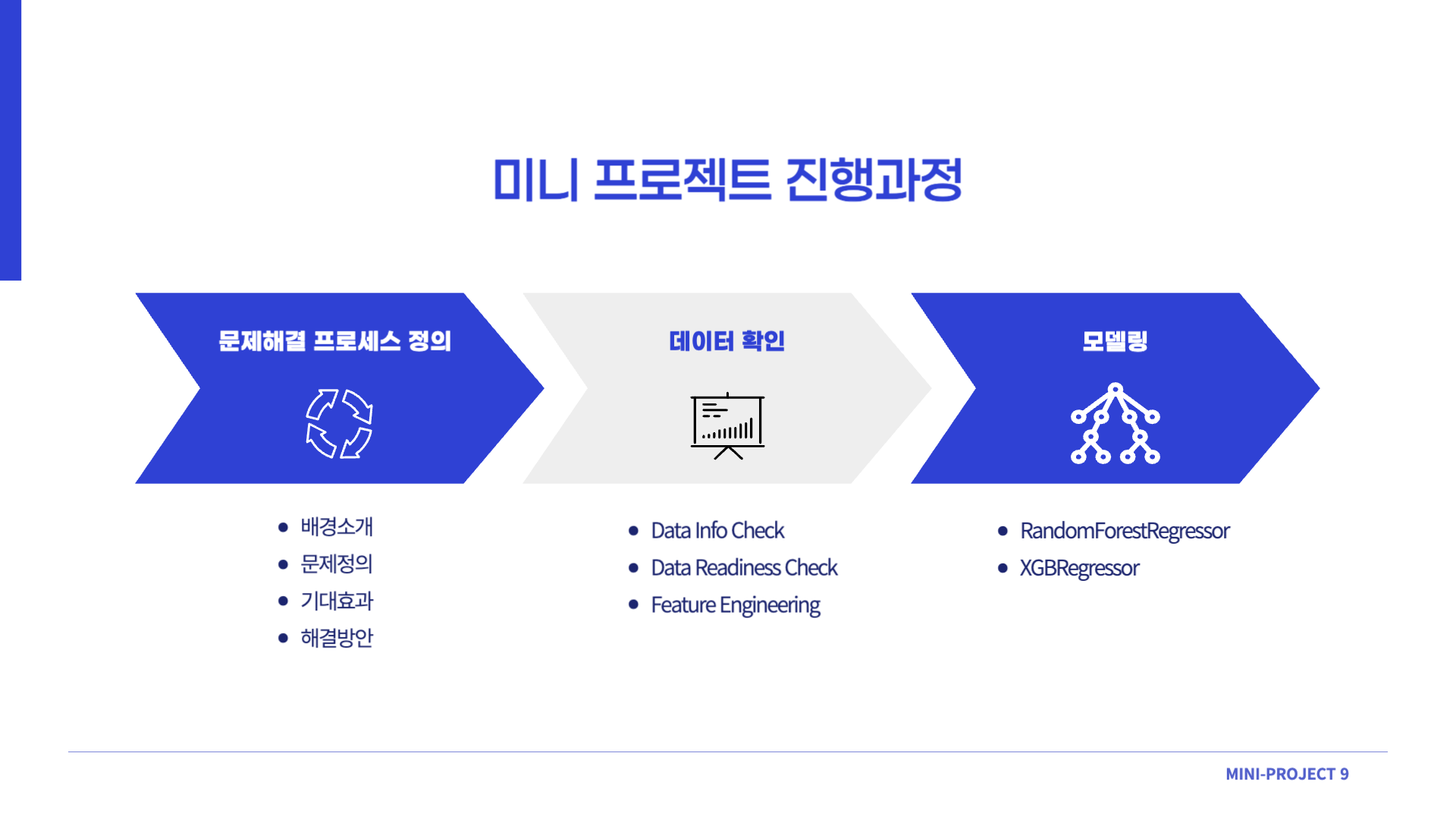
전체적인 프로젝트 진행과정을 간략하게 소개해드리면, 먼저 문제해결 프로세스를 정의했습니다. 이번 미니 프로젝트의 배경, 해결하고자 하는 문제는 무엇인지, 문제를 해결함으로서 얻게되는 기대효과는 무엇이고, 어떻게 해결할지에 대한 과정을 정의했습니다.
다음으로는 데이터를 확인하는 과정을 거쳤습니다. 데이터의 shape, type 등의 기본적인 정보들을 확인한 후에 (Data Info Check), 데이터가 모델링을 위해 사용가능한 상태로 만들고 (Data Readiness Check), 그 다음으로는 모델링의 성능을 올릴 수 있을만한 형태로 데이터를 변형하는 과정 (Feature Engineering) 을 거쳤습니다.
세번째로는 변형한 데이터를 활용하여 모델링을 진행했습니다. Ensemble 계열의 bagging 모델인 RandomForest와 boosting 계열의 XGBoost 두 가지 모델을 사용해 모델링을 진행했습니다. 해당 두 모델을 사용해 모델링을 한 후 성능 평가를 통해 더 좋은 모델을 골라 최종 모델로 선정했습니다.
다음으로는 문제해결 프로세스를 정의한 과정을 소개해드리겠습니다.
03. 문제해결 프로세스 정의

해당 미니 프로젝트의 배경에는 늘어난 유동인구로 인해 교통 체증이 심각해진데 있습니다. 이전의 적은 인구로 설계 및 건설이 되어있던 도로 등의 설비 등이 더 많아진 유동인구를 감당하는데 한계가 있기 때문입니다.
이에 대한 문제로 기존에 살고 있던 제주도민들의 출퇴근 시간이 길어지는 등 불편이 발생하고 있습니다. 그래서 이를 해결하고자 다양한 지표들을 활용하여 더 정확한 교통 예측 정보 제공을 통해 운전 편의성을 제공하고자 합니다.
문제를 해결함으로서 얻는 기대효과로 제주도 내에서 운송 스케줄을 계획하는 개인 혹은 회사에게 편의성을 제공해줄 수 있습니다. 또한 제주도 외부에서 온 관광객에게도 이동을 할 때 참고할 수 있는 서비스를 제공할 수 있습니다.
문제해결 프로세스의 마지막은 해결방안의 정의입니다. 먼저 데이터를 시각화하여 데이터를 눈으로 확인하고, 데이터를 모델링에 활용할 수 있는 형태로 변형했습니다. 그리고 2개의 모델로 모델링을 진행하고 성능을 확인하며 최종 모델을 선택했습니다. (하이퍼파라미터 튜닝 과정은 생략했습니다.)
다음으로 데이터를 확인하고 변형하는 과정을 거쳤습니다.
04. 데이터 확인
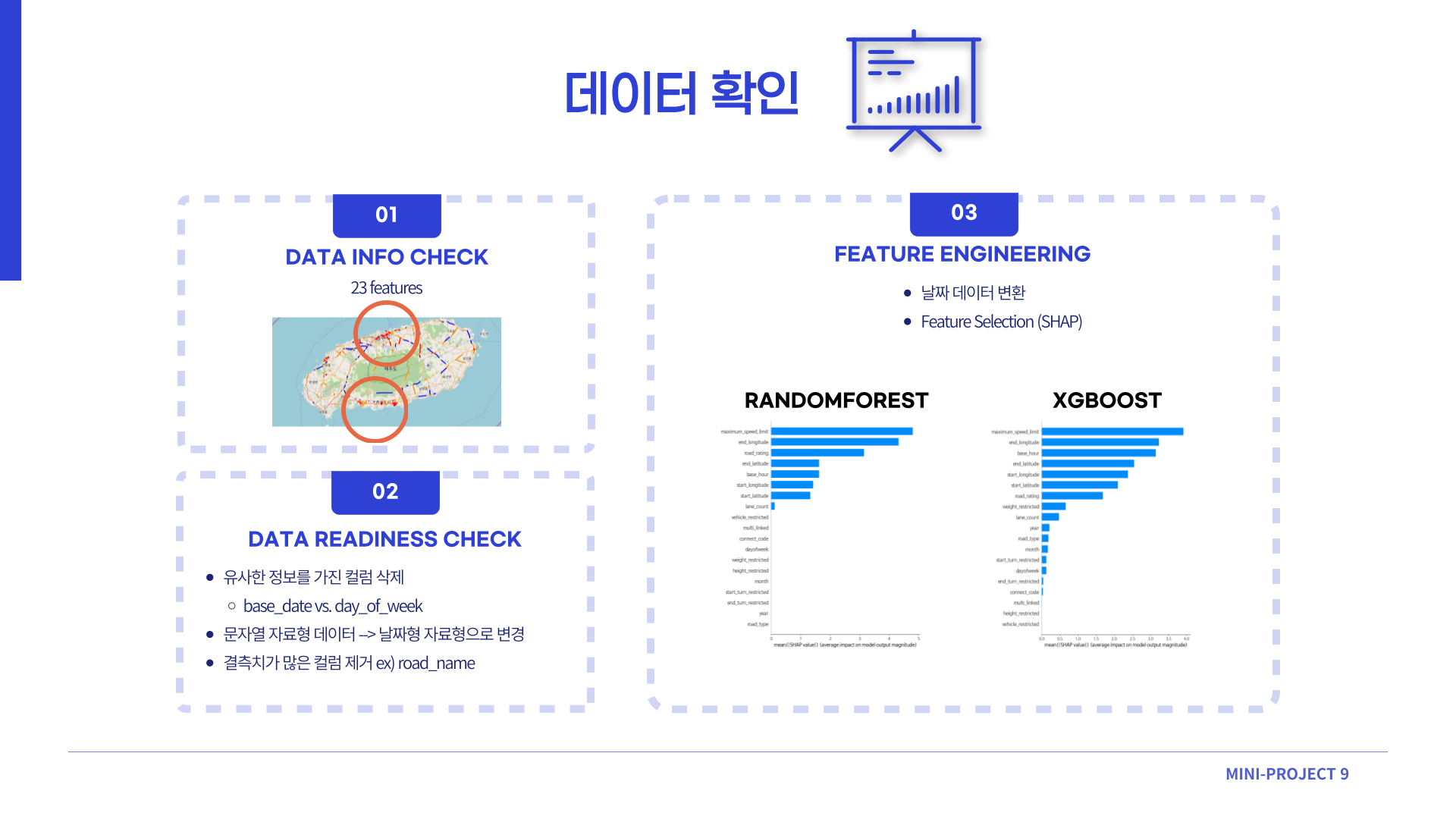
먼저 Data Info Check 단계에서 데이터의 기본적인 형태를 확인했습니다. 그런 다음 위도와 경도를 기준으로 속도를 일정구간으로 나누어 folium 라이브러리로 막히는 구간 (속도를 기준으로)을 시각화했습니다. 지도를 봤을 때 제주시와 서귀포시에 교통혼잡량이 많다는 것을 짐작할 수 있었습니다.
다음으로 Data Readiness Check 단계에서는 데이터를 쓸 수 있는 형태로 변경하였습니다. 유사한 정보를 가진 컬럼은 삭제하기도 하고, 날짜형 데이터가 필요하여 (연,월,일) 문자열로 되어있는 날짜 정보를 datetime 형태로 변형하기도 했습니다. 그리고 결측치가 많아 사용하기 어려운 컬럼은 삭제했습니다.
Feature Engineering 단계에서 주요하게 다룬 내용은 Feature Selection (선택할 컬럼 선택) 과정입니다.
RandomForestRegressor와 XGBMRegressor 두 모델을 하이퍼파라미터를 거의 건들지 않은 기본적인 상태로 (속도가 너무 오래걸릴 것을 우려하여 max_depth=5로 설정) 돌렸습니다. 그 다음 SHAP 라이브러리를 통해 Feature Importance를 확인하여 두 모델에서 겹치는 상위 8개의 feature를 최종으로 사용할 컬럼으로 선정했습니다.
(선정된 최종 컬럼은 최대 속도 제한, 도로 끝지점 위도, 도로 시작점 위도, 도로 평가 점수, 도로 시작점 경도, 도로 끝지점 경도, 시간, 도로 차선 수 입니다.)
05. Modeling
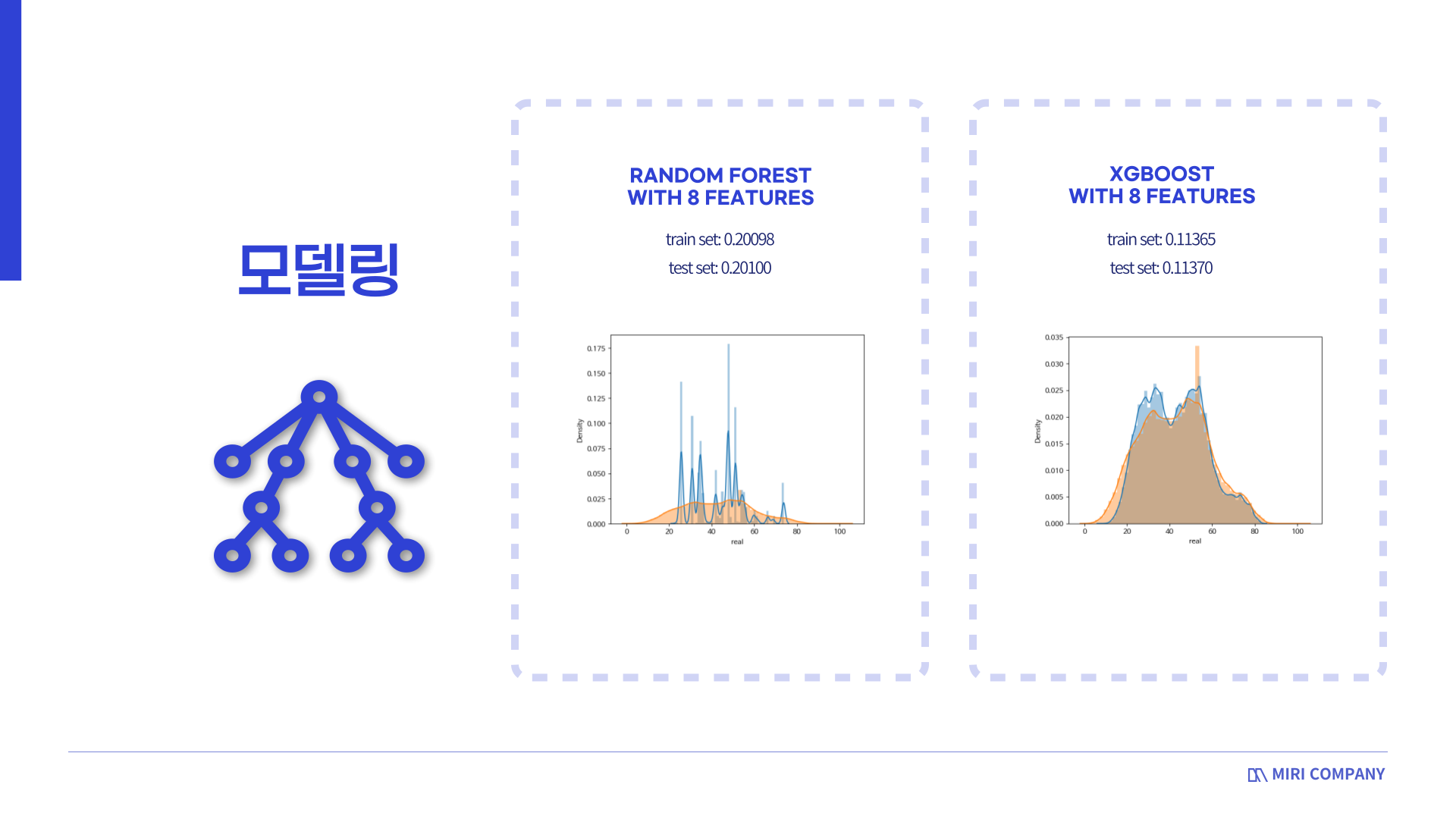
선정된 8개의 feature로 모델링을 한 결과,
Random Forest의 경우 train set과 test set 에서 약 0.201의 MAPE가 확인할 수 있었습니다.
XGBoost의 경우는 train set과 test set 에서 약 0.1137의 MAPE가 확인할 수 있었습니다.
예측결과와 실제값을 시각화했을 때, XGBoost의 예측 결과가 실제값과 많이 겹치는 부분이 있다는 것을 알 수 있었습니다.
이를 통해 해당 데이터가 bagging 계열보다는 boosting 계열에 더 적합하다는 결론을 내릴 수 있었습니다.
(하이퍼파라미터를 조정한다면 Random Forest의 예측값을 시각화한 부분이 좀 더 스무스하게 변할 것 같습니다.)
06. 마무리하며
아쉽게도 해당 미니 프로젝트에서는 예측결과를 비교할 수 있는 테스트 데이터가 없었습니다 (위에서 모델링에 사용되었던 test set은 훈련 데이터를 분할해서 사용한 test set 입니다). 그래서 마지막으로 교통량 예측결과를 시간별로 시각화하는 과정으로 마무리지었습니다.
이번 미니 프로젝트를 통해 Shapely value를 사용하여 모델링에 사용할 feature를 선정하는 과정을 경험을 할 수 있었습니다. 이전에 SHAP을 사용하는 방법을 배운적이 있었지만 실제로 활용할 기회가 없었는데, 이번 미니 프로젝트를 통해 feature importance를 시각화하고 feature selection 하는 과정을 거치며 배웠던 내용을 더 잘 이해할 수 있었습니다.
이번 프로젝트는 이전 프로젝트들과 달리 새로운 내용을 배우기보다는 이전 프로젝트들에서 진행했던 분석방법들을 복습하는 시간이었습니다. 그래서 복습을 하며 까먹었던 내용들은 다시 떠올리며 기억할 수 있었고, 알고 있던 부분은 체화하는 시간을 가질 수 있어 유익한 시간이었습니다.
많이 부족하지만 읽어주셔서 감사합니다:) 피드백은 언제나 환영합니다:)
