[운영체제] 19. Networks and Distributed System
분산시스템 : 공유 안하는 프로세서들의 모음
- 각 노드는 자체 로컬메모리가 있고 노드는 버스를 타고 네트워크를 통해 통신한다.
- 대규모 클라우드, 대규모 데이터분석, 과학데이터 병렬 처리
- 인터넷
- 통신 네트워크로 느슨하게 연결된 노드들의 집합
19.1 분산시스템의 장점
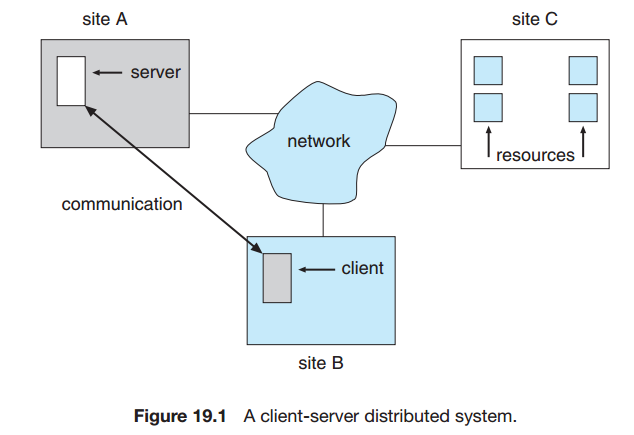
노드는 클라이언트와 서버의 역할을 모두 수행할 수 있다.
여기서 사이트는 기기의 위치를 나타내고 노드로 사이트의 특정 시스템을 언급한다.(siteC안의 작은 네모상자가 노드다)
시스템 간 전달되는 정보를 "메시지"라고 하며, 낮은 수준에서 이루어진다.(단일 컴퓨터에서 프로세스간 메시지 전달과 유사함)
자원공유
서로 다른 기능을 가진 여러 사이트가 연결되면 한 사이트사용자가 다른 사이트의 가용자원을 사용할 수 있다.
- 원격 파일 공유
- 분산 데이터베이스 정보처리
- 원격사이트 파일 인쇄
- 슈퍼컴퓨터 GPU
계산속도 향상
하위 계산을 분산시켜 동시에 실행시킨다. 또한 과부화 된 사이트의 업무를 다른 사이트로 재배치하는 load Balancing을 사용한다.
신뢰성
하나의 사이트가 장애가 발생해도 나머지 사이트가 계속 작동되어 신뢰성이 향상된다. 그러나 시스템이 웹서버, 파일시스템 가튼 중요한 시스템 기능을 담당할 경우, 하나의 시스템 장애가 전체 시스템작동을 멈출수 있다. 일반적으로 충분한 중복성을 사용하면 시스템이 계속 작동할 수 있다.
19.2 네트워크 구조
LAN :근거리통신망 - 소규모 건물에 분산된 호스트
WAN :광역 통신망 - 넓은 지역(대귝) 분산된 시스템
LAN : local area networks
사무실, 가정환경 등 모든 사이트가 서로 가까워 통신링크 속ㄷ가 빠르고, 오류율이 낮다.
하나이상의 라우터, 여러 컴퓨터, 이더넷과WIFI로 구성된다.
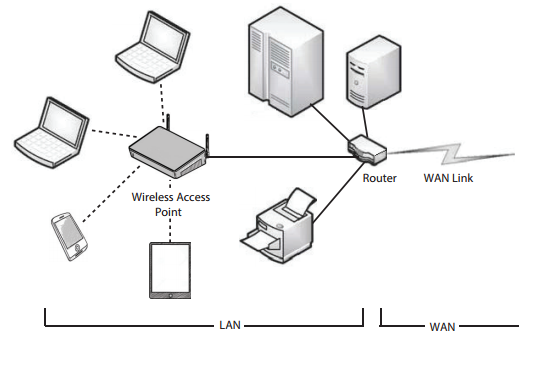
이 네트워크는 신호를 전송하기 위해 동출, 트위스티드 페어 또는 광섬유케이브을 사용한다. wifi는 현재 어디에나 있으며 기존의 이더넷 네트워크를 보완하거나 자체적으로 존재한다.
WAN : wide area networks
인터넷 (world wide web) 역시 wan이다.
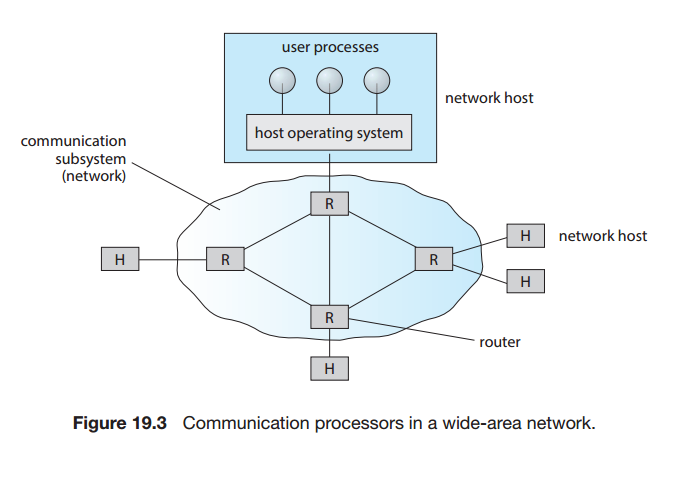
넓은 지리적 지역에 분포되었으며, 링크는 전화선, 임대회선, 광케이블, 전파 및 위성채널 등이다. 이 통신 링크는 트래픽을 다른 라우터 및 네트워크로 보내고 다양한 사이트 간에 정보를 전송하는 라우터에 의해 제어된다.
호스트는 일반적으로 LAN에 있으며 지역네트워크를 통해 인터넷에 연결된다. 지역네트워크는 라우터와 상호연결되어 전세계 네트워크를 형성한다.
19.3 통신 구조
이름 지정 및 이름 찾기
사이트A와 B가 정보를 교환하려면 서로를 지정할수 있도록 네트워크상에서 시스템 이름 지정이 필요하다. 단일 컴퓨터에서 프로세스가 식별자를 가진것과 달리, 네트워크로 연결된 시스템은 메모리를 공유하지 않아 다른 호스트의 이름을 알 수 없다.
일반적으로 원격 시스템의 프로세스는 <호스트 이름, 식별자> 쌍으로 식별된다.
예를 들어 <naver, 128.252.12.100>
컴퓨터는 호스트 이름을 호스트id로 변환하는 기법을 사용한다.
그러나 모든 사ㅣ트의 이름을 가지고 있을수는 없기때문에, 대안으로 네트워크 상의 시스템 간에 정보를 배포한다.
인터넷을 호스트 이름을 알기위해 DNS(domain-name-sysem)을 사용한다. DNS는 호스트의 이름을 지정할 뿐만아니라 이름-주소 변환을 지정한다. 인터넷의 호스트는 ip주소라는 여러 부분으로 구성된 이름으로 주소가 표기된다.
EX) eric.cs.yale.edu에서, .으로 구분된 각 구성요서는 네임서버를 가진다. 네임서버는 각 네임서버의 주소를 반환하는데, 최상위 edu부터 호스트 이름인eric 서버에 까지 접속하면 호스트id가 반환된다.
자바는 IP이름을 IP주소에 매핑하는 API를 제공한다. InetAddress라는 클래스를 통해 사용할 ㅜ 있다..
통신 프로토콜
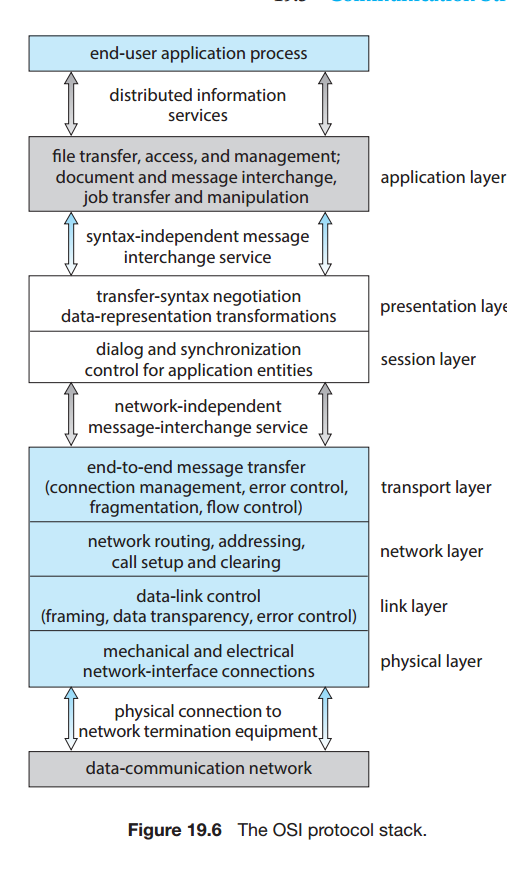
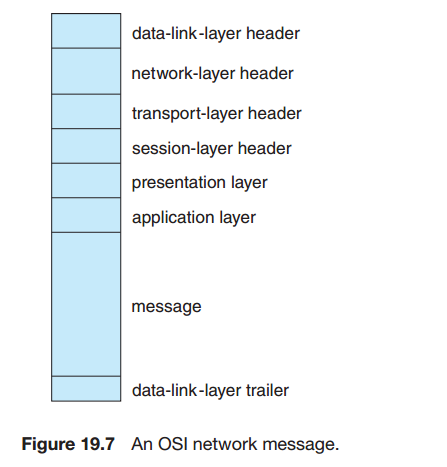
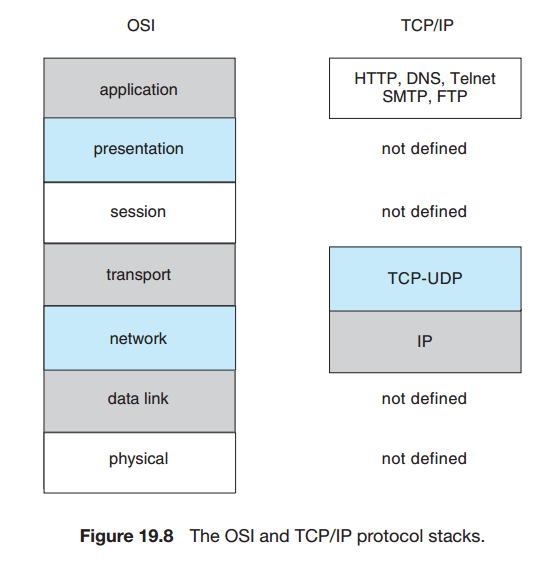
TCP/IP는 HTTP, FTP, SSH, DNS, SMTP등 여러 프로토콜을 식별한다. IP는 IP데이터그램, 패킷을 인터넷을 통해 라우팅하는 일을 담당한다.
예시 - 책들고가서 같이 읽기..
전송 프로토콜 UDP 및 TCP
특정 IP주소를 가진 호스트가 패킷을 받으면 정확한 대기 프로세스로 전달해야 한다. 전송 프로토콜은 포트번호를 사용하여 수신 및 송신 프로세스를 식별한다.
예를들어 http웹 사이트에 연결하려는 경우 브라우저는TCP 전송 헤더에 포트번호로 80을 사용하여 서버의 포트80에 자동으로 연결을 시도한다.
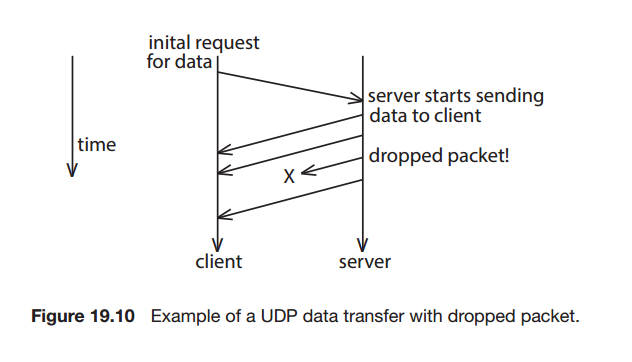
UDP : user datagram protocol
datagram
IP + 포트 번호 의 조합이다.
신뢰성이 없고 헤더는 매우 단순하여 소스 포트번호, 목적지 포트번호, 길이, 체크섬만 가지고 있다.
패킷을 목적지로 빠르게 보낼 수 있그나 패킷이 유실되거나 순서가 꼬일 수 있다.
TCP : transmission control protocol
TCP는 UDP에서 순서를 지키기 위한 기법과 포트번호가 명시되어있다.
-
호스트가 패킷을 보낼 때 수신자는 ACK를 보낸다.
-
헤더에 시컨스 번호를 넣어 패킷을 순서대로 배치, 누락한 패킷 확인
-
일련의 제어 패킷(핸드쉐이크)로 시작하고 닫는다.
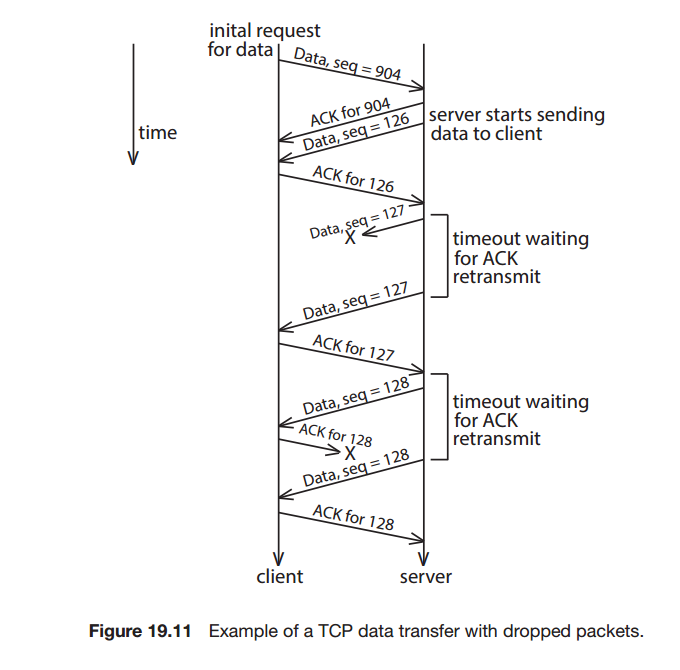
그 외에도
흐름제어 : 발신자가 수신자의 용량을 초과하는 것을 방지한다.
혼잡제어 : 송신자와 수신자사이의 네트워크를 어림계산한다.19.4 네트워크 및 분산 운영체제
네트 워크 운영체제는 네트워크 운영체제와 분산 운영체제로 구분된다. 분산 운영체제가 더 구현하기 어렵지만 더 많은 기능을 가진다.
네트워크 운영체제
네트워크 운영체제는 사용자가 적절한 원격시스템에 로그인하거나 원격 시스템에서 자신의 시스템으로 데이터를 전송하여 원격자원에 액세스할수있는 환경을 제공한다.
- 원격 로그인 : 사용자가 원격으로 로그인할 수 있게 ssh기능을 제공한다.(암호화된 소켓 연결, https의 s)
- 원격 파일 전송 : FTP, SFTP 라는 파일전송프로토콜을 제공해 원격파일을 복사하거나 파일을 변경할 수 있도록 한다.
- 클라우드 저장장치 : 사용자는 클라우드 서비스에 로그인 하고 나면 일련의 그래픽 명령으로 파일을 업로드, 다운로드, 공유한다.
분산 운영체제
사용자가 로컬 자원에 액세스 하는 것과 동일한 방식으로 원격 자원에 액세스한다.
- 데이터 마이그레이션 : 사이트A에서 사이트B로 필요한 파일의 일부만 바로 전송한다.
- 계산 마이그레이션 : 계산을 시스템 전체에 걸쳐 전송한다.
- 프로세스 마이그레이션 : 프로세스가 일부 다른 사이트에서 실행된다.
- 부하 균등화, 계산속도 향상, 하드웨어 선호도, 소프트웨어 선호도, 데이터 접근 때문에
19.5 분산 시스템의 설계 문제
- 견고성 : 분산 시스템은 다양한 유형의 하드웨어 장애가 발생할 수 있고 이러한 장애를 감시, 재구성, 복원하기 위한 방법이 필요하다.
- 결함 허용성
- 장애 감지
- 재구성 : a와b의 직접 링크가 실패한 경우 이 정보가 모든 사이트에 브로드캐스트 되어야한다.
- 장애 복구 : a와b에 모두 링크가 수정된다고 통보하거나, b가 복구중이라고 모두에게 메시지를 보내야한다.
- 투명성 : 사용자에게 저장장치를 투명하게, 로컬인것처럼 보여야한다.
- 확장성 : 시스템이 한정된 자원을 가지고 있고 부하가 증가할때. 확장 가능한 시스템은 단계적으로 반응한다.
a 성능이 적정 수준으로 더 저하된다
b. 자원이 포화상태가 되면 새 기계를 추가하거나 두개의 네트워크를 연결해 확장한다.
그 외에도 압축, 중복 제거를 사용하여 저장장치 사용량을 줄인다.
19.6 분산파일 시스템 DFS
DFS의 서비스 : 하나이상의 시스템에서 실행되고 클라이언트에 특정 유형의 기능을 제공하는 소프트웨어 개체
서버 : 단일 시스템에서 실행되는 서비스 소프트웨어
클라이언트 : 기계간 인터페이스. 서비스 호출 프로세스
DFS의 구현은 시스템마다 다를 수 있다. 독특한 특징은 클라이언으와 서버의 다양성과 자율성이다.
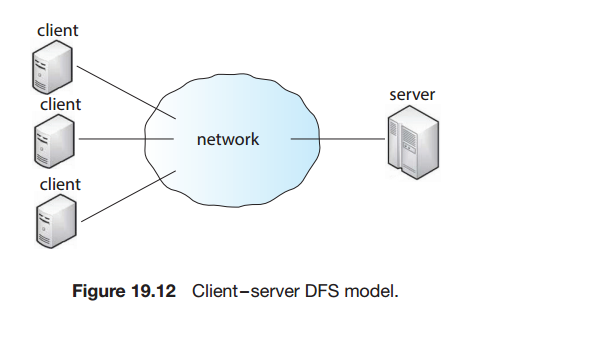
클라이언트-서버 모델
서버 : 파일과 메타데이터를 모두 연결된 저장장치에 저장한다.
N클라이언트는 NFS등의 프로토콜로 서버에 접속하고 파일액세스를 요청한다.
Andrew 파일시스템
확장성에 중점을 두고 만들어졌다. 서버가 가능한 많은 클라이언트를 지원하도록 클라이언트가 ㅏ일을 요청하면 파일 내용은 서버에서 다운롣되어 클라이언트의 로컬저장소에 저장된다.
클러스터 기반DFS모델
google 파일시스템, Hadoop 분산파일 시스템이 이 예이다.
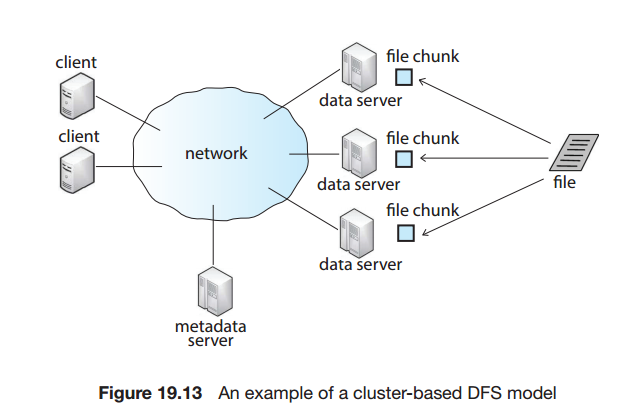
하나 이상의 클라이언트가 네트워크를 통해 마스터 메타데이터 서버 및 파일의 청크(일부)를 포함하는 여러 데이터서버에 연결된다.
메타데이터 서버는 어떤 데이터 서버가 어떤 파일 청크를 가졌는지를 알고 있다.
파일에 액세스하려면 클라이언트는 먼저 메타데이터서버에 접속하고, 메타데이터 서버는 데이터서버들의 ID를 반환한다. 그럼 클라이언트는 해당 파일을 가진 데이터 서버에 접속하여 파일 정보를 수신한다.
19.7 DFS 명명 및 투명성
..
naming은 논리적 객체와 물리적 객체 사이의 매핑이다. 또한 투명한DFS는 파일 사본의 존재와 파일 위치를 네이밍으로 추상화시켜 숨긴다.
명명구조
- 위치 투명성 : 물리적 저장위치를 드러내지않ㅇ는다.
- 위치 독립 : 물리 위치가 변경되어도이름은 그대로다.
..머라머라머라
명명기법
- 홋트이름+로컬이름
- 자동 마운트 기능으로 마운트 포인트테이블 사용
구현 기법
위치 독립적 파일 식별자를 도입한다.
19.8 원격 파일 액세스
원격 서비스 기법으로 원격파일에 대한 액세스를 허용한다.
기본 캐싱 기법
서버에서 클라이언트 시스템으로 데이터 사본을 가져온다.
캐시 위치
캐시된 데이터를 디스크나 메인메모리에 저장한다.
캐시 업데이트 정책
- 지연 쓰기 정책(write-back)
- write-through 정책
- write-on-close 정책
일관성
로컬로 캐시된 데이터 사본이 마스터 사본과 일치하는지 결정하는 문제
1. 클라이언트 주도 검증방식 : 클라이언트가 서버에 접속해 로컬데이터와 일치하는지 유효성 검사
2. 서버 주도검증방식 : 서버가 각 클라이언트의 캐시파일 기록을 유지하고 불일치를 감지하면 대응한다.
