오늘의 학습 키워드 📕
▸ 오늘의 코드카타
▸ JDBC
▸ ORM
✅ 오늘의 코드카타
2024년 3월 5일 - [프로그래머스 - 자바(JAVA)] 33 : 타겟 넘버 | 최솟값 만들기
✅ JDBC
- 연결정보 파라미터 정의
- Connection 생성
- 실행할 SQL 문 지정
- 파라미터 선언과 파라미터 값 제공
- Statement 준비와 실행
- 결과 담기
- Connection, Statement, ResultSet 닫기
- Connection, Statement, ResultSet 예외 처리
JDBC DB 연결 실습
void jdbcTest() throws SQLException {
//given
// docker run -p 5432:5432 -e POSTGRES_PASSWORD={비밀번호} -e POSTGRES_USER={이름} -e POSTGRES_DB=messenger --name postgres_boot -d postgres
// docker exec -i -t postgres_boot bash
// su - postgres
// psql --username yejin --dbname messenger
// \list (데이터 베이스 조회)
// \dt (테이블 조회)
// 각 어플리케이션에서 이 컨테이너에 접속하기 위해서는
// url 경로로 username과 password로 접속하겠다.
String url = "jdbc:postgresql://localhost:5432/messenger";
String username = "{이름}";
String password = "{비밀번호}";
//when
try {
Connection connection = DriverManager.getConnection(url, username, password);
String creatSql = "CREATE TABLE ACCOUNT (id SERIAL PRIMARY KEY, username varchar(255), password varchar(255))";
// 쿼리 실행
PreparedStatement statement = connection.prepareStatement(creatSql);
statement.execute();
// 제일 중요한 자원 해제
statement.close();
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}- 이 실습에서는 postgreSQL 의존성을 추가해야한다.
//build.gradle
//PostgreSQL 의존성 추가
implementation 'org.postgresql:postgresql:42.2.27'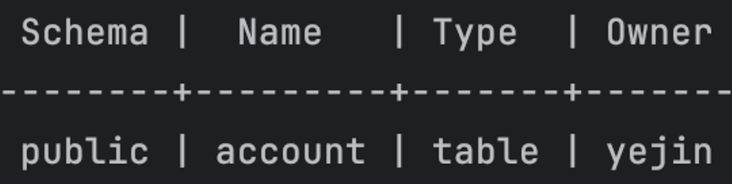
- 인텔리제이 데이터베이스 연동도 가능하다.
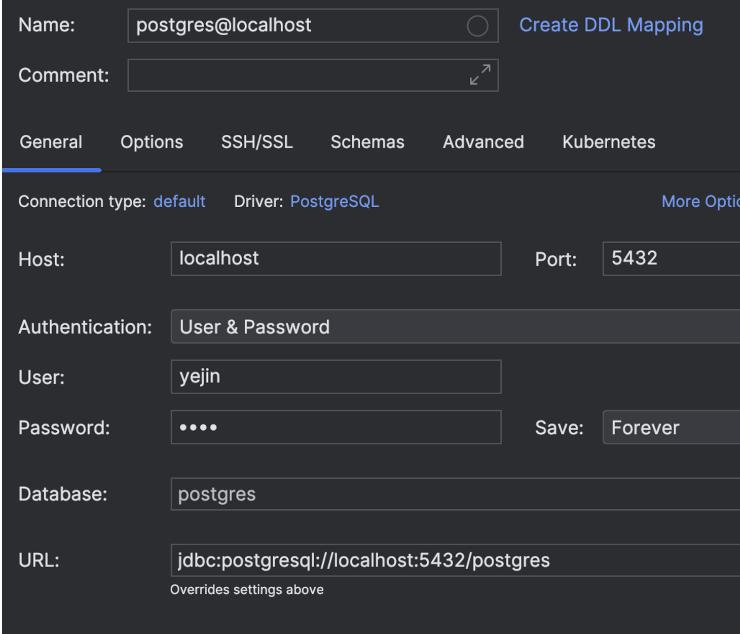
- Database: messenger (postgres X)
JDBC 삽입/조회 실습
@Test
@DisplayName("JDBC 삽입/조회 실습")
void jdbcInsertSelectTest() throws SQLException {
// given
String url = "jdbc:postgresql://localhost:5432/messenger";
String username = "yejin";
String password = "pass";
// when
//자동으로 close(자원해제) 하는 방법 : try() -> 괄호 안에 connection 넣어주기
try (Connection connection = DriverManager.getConnection(url, username, password)) {
System.out.println("Connection created: " + connection);
String insertSql = "INSERT INTO ACCOUNT (id, username, password) VALUES ((SELECT coalesce(MAX(ID), 0) + 1 FROM ACCOUNT A), 'user1', 'pass1')";
try (PreparedStatement statement = connection.prepareStatement(insertSql)) {
statement.execute();
}
// then
String selectSql = "SELECT * FROM ACCOUNT";
try (PreparedStatement statement = connection.prepareStatement(selectSql)) {
var rs = statement.executeQuery();
while (rs.next()📌) {
System.out.printf("%d, %s, %s", rs.getInt("id"), rs.getString("username"),
rs.getString("password"));
}
}
}
}📌
executeQuery()는 JDBC에서 사용되는 메서드로, SELECT 쿼리를 실행하고 그 결과를 나타내는ResultSet객체를 반환한다.executeQuery()메서드는Statement또는PreparedStatement인터페이스에서 호출할 수 있다. 이 메서드는 DB로부터 데이터를 검색할 때 사용된다.- 실행된 쿼리가 SELECT 쿼리일 때 사용되며, 해당 쿼리의 결과로
ResultSet객체가 반환된다. 반환된ResultSet객체는 DB로부터 검색된 결과를 포함하며, 이를 통해 자바 애플리케이션에서 데이터를 읽을 수 있다.
📌
- 여기서
rs는 JDBC(Java Database Connectivity)를 통해 실행된 쿼리에 대한 결과 집합을 나타내는 객체이다. JDBC에서ResultSet인터페이스를 구현한 것이다. ResultSet은 테이블로부터 데이터를 가져올 때 사용되며, 테이블의 각 행(row)에 대한 데이터를 나타낸다. 각 행은 열(column)의 집합으로 이루어져 있다.- 주요 메서드로는
next(),getInt(),getString()등이 있다.next(): 결과 집합에서 다음 행으로 이동하고, 그 행이 존재하면 true를 반환한다. 만약 다음 행이 없다면 false를 반환한다.getInt(),getString(): 현재 행에서 지정된 열의 데이터를 가져온다. 열은 이름(String) 또는 인덱스(int)로 지정할 수 있다.
- 따라서
while (rs.next())는 결과 집합에서 다음 행이 존재하는 동안 반복하고, 각 행의 id, username, password 열의 데이터를 가져와 출력한다.
JDBC DAO 삽입/조회 실습
@Test
@DisplayName("JDBC DAO 삽입/조회 실습")
void jdbcDAOInsertSelectTest() throws SQLException {
// given
AccountDAO accountDAO = new AccountDAO();
// when
var id = accountDAO.insertAccount(new AccountVO("new user", "new password"));
// then
var account = accountDAO.selectAccount(id);
assert account.getUsername().equals("new user");
}- 쿼리를 직접 만드는 것이 아니라 DAO라는 객체를 만들어서 이런 동작을 대신 해주도록 함
- AccountDAO가 하는 일 : JDBC 관련 변수 관리
AccountDAO
public class AccountDAO {
//JDBC 관련된 변수 관리
private Connection conn = null;
private PreparedStatement stat = null;
private ResultSet rs = null;
private final String url = "jdbc:postgresql://localhost:5432/messenger";
private final String username = "yejin";
private final String password = "pass";
//SQL 쿼리
private final String ACCOUNT_INSERT = "INSERT INTO account(ID, USERNAME, PASSWORD) "
+ "VALUES((SELECT coalesce(MAX(ID), 0) + 1 FROM ACCOUNT A), ?, ?)";
private final String ACCOUNT_SELECT = "SELECT * FROM account WHERE ID = ?";
//CRUD 기능 메서드
public Integer insertAccount(AccountVO vo) {
var id = -1;
try {
String[] resultId = {"id"};
conn = DriverManager.getConnection(url, username, password);
stat = conn.prepareStatement(ACCOUNT_INSERT, resultId);
stat.setString(1, vo.getUsername());
stat.setString(2, vo.getPassword());
stat.executeUpdate();
try (ResultSet rs = stat.getGeneratedKeys()) {
if (rs.next()) {
id = rs.getInt(1);
}
}
} catch (SQLException e) {
e.printStackTrace();
}
return id;
}
public AccountVO selectAccount(Integer id) {
AccountVO vo = null;
try {
conn = DriverManager.getConnection(url, username, password);
stat = conn.prepareStatement(ACCOUNT_SELECT);
stat.setInt(1, id);
var rs = stat.executeQuery();
if (rs.next()) {
vo = new AccountVO();
vo.setId(rs.getInt("ID"));
vo.setUsername(rs.getString("USERNAME"));
vo.setPassword(rs.getString("PASSWORD"));
}
} catch (SQLException e) {
e.printStackTrace();
}
return vo;
}
}AcountVO
public class AccountVO {
private Integer id;
private String username;
private String password;
public AccountVO(String username, String password) {
this.username = username;
this.password = password;
}
public AccountVO() {
}
public void setId(Integer id) {
this.id = id;
}
public void setUsername(String username) {
this.username = username;
}
public void setPassword(String password) {
this.password = password;
}
public Integer getId() {
return id;
}
public String getUsername() {
return username;
}
public String getPassword() {
return password;
}
}
- 그러나 JDBC의 여러 문제로 QueryMapper가 탄생했다.
JDBC 로 직접 SQL을 작성했을때의 문제
- SQL 쿼리 요청시 중복 코드 발생한다.
- DB별 예외에 대한 구분 없이 Checked Exception (SQL Exception) 처리한다.
- Connection, Statement 등 자원 관리를 따로 해줘야한다.
- 안해주면 메모리 꽉차서 서버가 죽는다.
- 안해주면 메모리 꽉차서 서버가 죽는다.
이 문제 해결을 위해 처음으로 Persistence Framwork가 등장한다.
- Persistence Framework
- SQL Mapper : JDBC Template, MyBatis
- ORM
JDBC Template
- SQL Mapper 첫번째 주자로 JDBCTemplate 탄생
- 쿼리 수행 결과와 객채 필드 매핑
- RowMapper 로 응답필드 매핑코드 재사용
- Connection, Statement, ResultSet 반복적 처리 대신 해줌
- 그러나, 결과값을 객체 인스턴스에 매핑하는데 여전히 많은 코드가 필요함
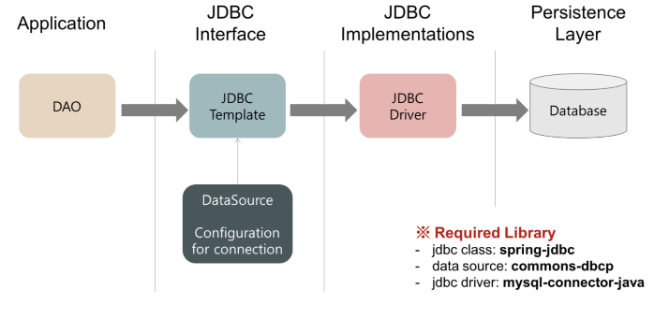
QueryMapper의 DB의존성 및 중복 쿼리 문제로 ORM이 탄생했다.
✅ ORM
- ORM은 DAO 또는 Mapper를 통해서 조작하는 것이 아니라 테이블을 하나의 객체(Object)와 대응시켜 버린다.
릴레이션(관계형 데이터베이스)를 객체(도메인 모델)로 매핑하려는 이유
- 객체 지향 프로그래밍의 장점을 활용할 수 있다.
- 이를 통해, 비즈니스 로직 구현 및 테스트 구현이 편리하다.
- 각종 디자인 패턴 사용하여 성능 개선 가능
- 코드 재사용
- 하지만, 객체를 릴레이션에 매핑하려니 여러 문제가 발생한다.
ORM이 해결해야하는 문제점과 해결책
▼ 상속의 문제
- 객체 : 객체간에 멤버변수나 상속관계를 맺을 수 있다.
- RDB : 테이블들은 상속관계가 없고 모두 독립적으로 존재한다.
▼ 해결방법
- 매핑정보에 상속정보를 넣어준다. (@OneToMany, @ManyToOne)
▼ 관계 문제
- 객체 : 참조를 통해 관계를 가지며 방향을 가진다.(다대다 관계도 있음)
- RDB : 외래키(FK)를 설정하여 Join으로 조회시에만 차조가 가능하다. (즉, 다대다는 매핑 테이블 필요)
▼ 해결방법
- 매핑정보에 방향정보를 넣어준다. (@JoinColumn, @MappedBy)
▼ 탐색 문제
- 객체 : 참조를 통해 다른 객체로 순차적 탐색이 가능하며 콜렉션도 순회한다.
- RDB : 탐색시 참조하는 만큼 추가 쿼리나, Join이 발생하여 비효율적이다.
▼ 해결방법
- 매핑/조회 정보로 참조 탐색 시점을 관리한다. (@FetchType, fetchJoin())
▼ 밀도 문제
- 객체 : 멤버 객체크기가 매우 클 수 있다.
- RDB : 기본 데이터 타입만 존재한다.
▼ 해결방법
- 크기가 큰 멤버 객체는 테이블을 분리하여 상속으로 처리한다. (@embedded)
▼ 식별성 문제
- 객체 : 객체의 hashCode 또는 정의한 equals() 메서드를 통해 식별
- RDB : PK로만 식별
▼ 해결방법
- PK를 객체 Id로 설정하고 EntityManager는 해당 값으로 객체를 식별하여 관리한다. (@Id,@GeneratedValue)
ORM이 얻은 최적화 방법
1. 1차, 2차 캐시
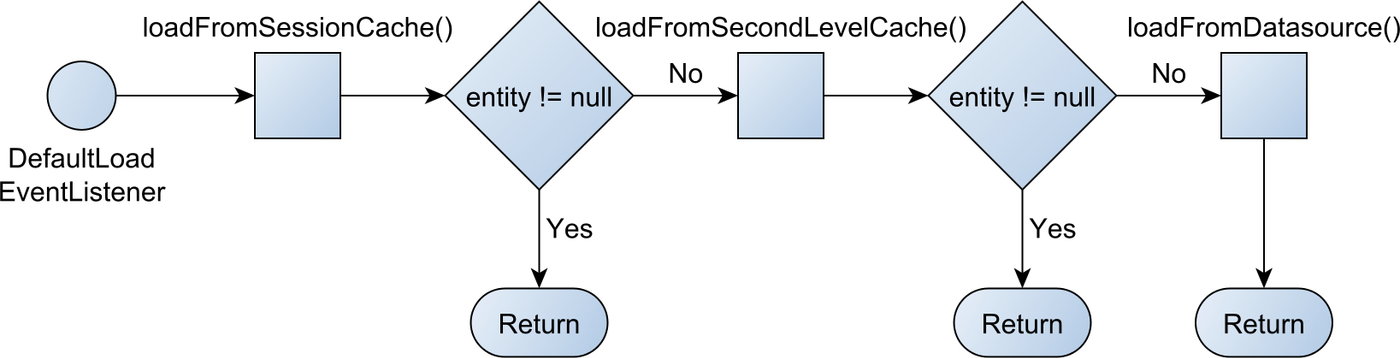
- 1차 캐시, 2차 캐시 조회 후 없으면 DataSource에서 조회한다.
1차 캐시
- 영속성 컨텍스트 내부에는 엔티티를 보관하는 저장소가 있는데 이를 1차 캐시라고 한다.
- 일반적으로 트랜잭션을 시작하고 종료할 때까지만 1차 캐시가 유효하다.
- 1차 캐시는 한 트랜잭션 계속해서 원본 객체를 넘겨준다.
2차 캐시
- 애플리케이션 범위의 캐시로, 공유 캐시라고도 하며, 애플리케이션을 종료할 때 까지 캐시가 유지된다.
- 2차 캐시는 캐시 한 객체 원본을 넘겨주지 않고 복사본을 만들어서 넘겨준다.
- 복사본을 주는 이유는 여러 트랜잭션에서 동일한 원본객체를 수정하는일이 없도록 하기 위해서이다.
2차 캐시 적용방법
1. Entity에 @Cacheable 적용 후 설정 추가
// Team.java
@Entity
@Cacheable
public class Team {
@Id @GeneratedValue
private Long id;
...
}# application.yml
spring.jpa.properties.hibernate.cache.use_second_level_cache: true
# 2차 캐시 활성화합니다.
spring.jpa.properties.hibernate.cache.region.factory_class: XXX
# 2차 캐시를 처리할 클래스를 지정합니다.
spring.jpa.properties.hibernate.generate_statistics: true
# 하이버네이트가 여러 통계정보를 출력하게 해주는데 캐시 적용 여부를 확인할 수 있습니다.2. sharedCache.mode 설정
# appplication.yml
spring.jpa.properties.javax.persistence.sharedCache.mode: ENABLE_SELECTIVEcache mode 종류
ALL 모든 엔티티를 캐시합니다. NONE 캐시를 사용하지 않습니다. ENABLE_SELECTIVE Cacheable(true)로 설정된 엔티티만 캐시를 적용합니다. DISABLE_SELECTIVE 모든 엔티티를 캐시하는데 Cacheable(false)만 캐시하지 습니다. UNSPECIFIED JPA 구현체가 정의한 설정을 따릅니다
2. 영속성 컨텍스트(1차 캐시)를 활용한 쓰기지연
영속성 이란?
- 데이터를 생성한 프로그램이 종료되어도 사라지지 않는 데이터의 특성을 말한다.
- 영속성을 갖지 않으면 데이터는 메모리에서만 존재하게 되고 프로그램이 종료되면 해당 데이터는 모두 사라지게 된다.
- 그래서 우리는 데이터를 파일이나 DB에 영구 저장함으로써 데이터에 영속성을 부여한다.
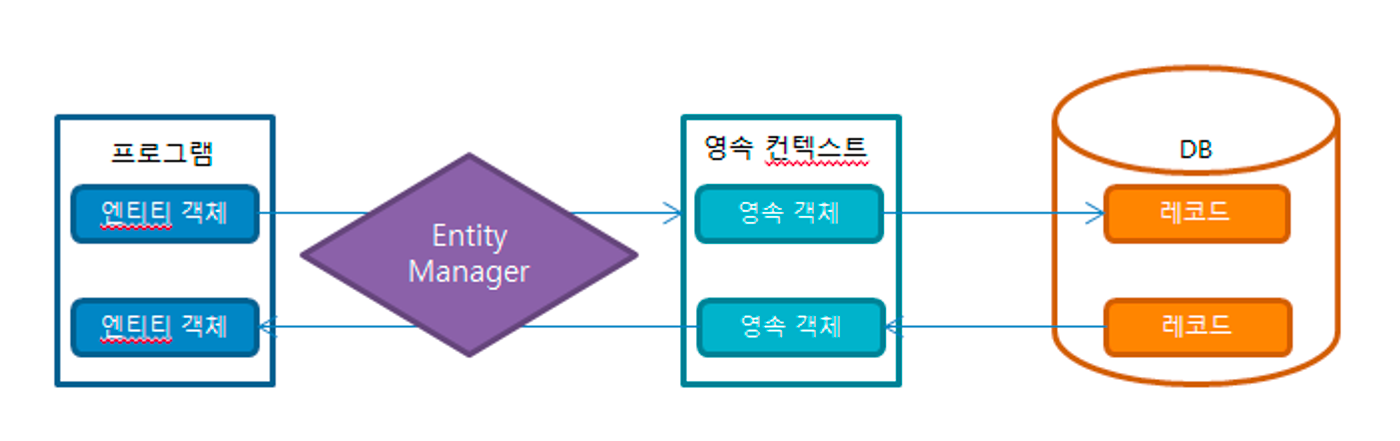
영속성 4가지 상태 (비영속 > 영속 > 준영속 | 삭제)
- 비영속(new/transient) - 엔티티 객체가 만들어져서 아직 저장되지 않은 상태로, 영속성컨텍스트와 전혀 관계가 없는 상태
- 영속(managed) - 엔티티가 영속성 컨텍스트에 저장되어, 영속성 컨텍스트가 관리할 수 있는 상태
- 준영속(detached) - 엔티티가 영속성 컨텍스트에 저장되어 있다가 분리된 상태로, 영속성컨텍스트가 더 이상 관리하지 않는 상태
- 삭제(removed) - 엔티티를 영속성 컨텍스트와 데이터베이스에서 삭제하겠다고 표시한 상태
- 객체의 영속성 상태는 Entity Manager 의 메소드를 통해 전환된다.
- Raw JPA 관점
- persist(),merge() >
(영속성 컨텍스트에 저장된 상태)> flush() >(DB에 쿼리가 전송된 상태)> commit() >(DB에 쿼리가 반영된 상태)
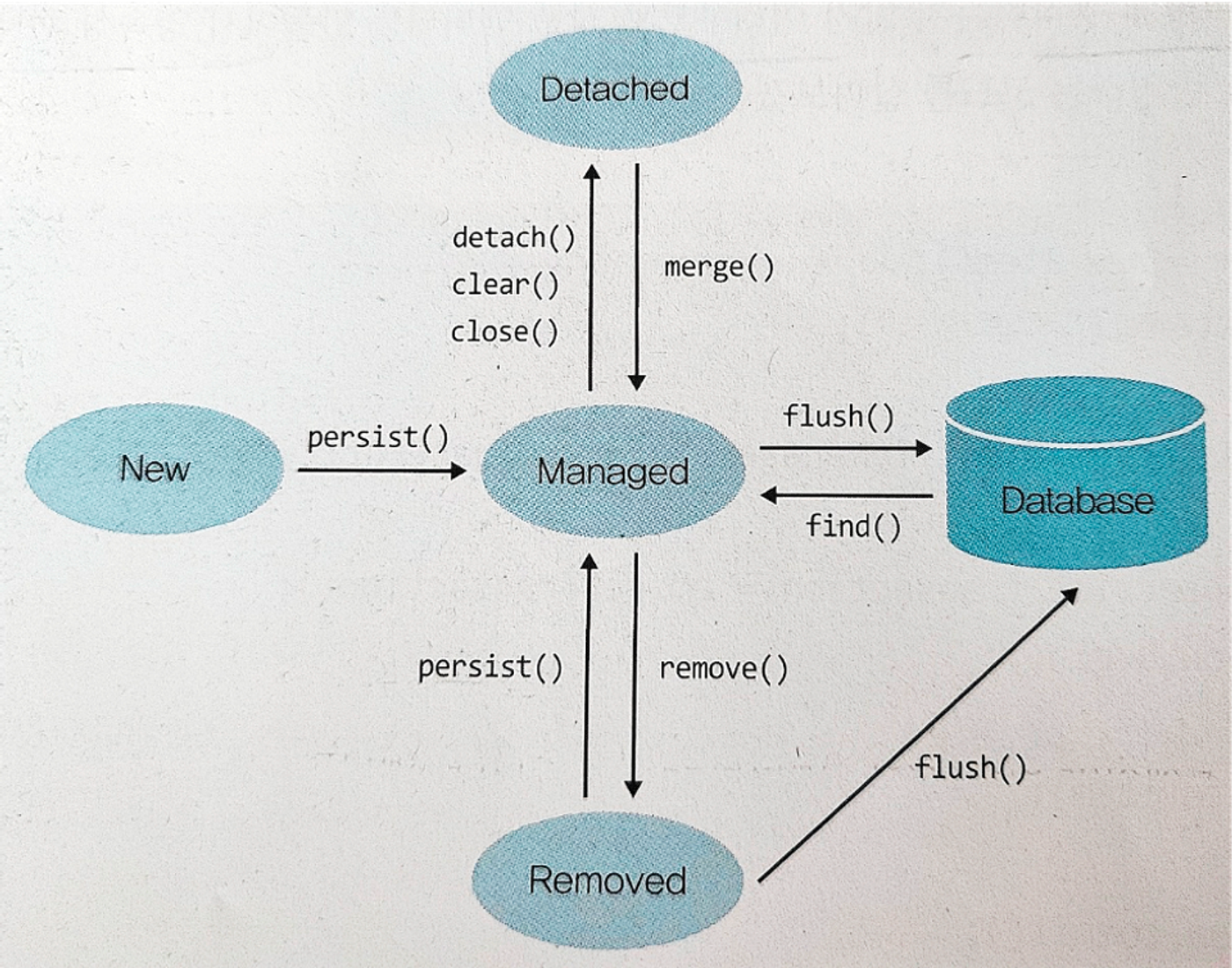
- persist(),merge() >
- 예제 코드
Item item = new Item(); // 1
item.setItemNm("테스트 상품");
EntityManager em = entityManagerFactory.createEntityManager(); // 2
EntityTransaction transaction = em.getTransaction(); // 3
transaction.begin();
em.persist(item); // 4-1
em.flush(item). // 4-2 (DB에 SQL 보내기/commit시 자동수행되어 생략 가능함)
transaction.commit(); // 5
em.close(); // 6
1 영속성 컨텍스트에 담을 상품 엔티티 생성
2 엔티티 매니저 팩토리로부터 엔티티 매니저를 생성
3 데이터 변경 시 무결성을 위해 트랜잭션 시작
4 영속성 컨텍스트에 저장된 상태, 아직 DB에 INSERT SQL 보내기 전
5 트랜잭션을 DB에 반영, 이 때 실제로 INSERT SQL 커밋 수행
6 엔티티 매니저와 엔티티 매니저 팩토리 자원을 close() 호출로 반환
쓰기지연이 발생하는 시점
- flush() 동작이 발생하기 전까지 최적화한다.
- flush() 동작으로 전송된 쿼리는 더이상 쿼리 최적화는 되지 않고, 이후 commit()으로 반영만 가능하다.
쓰기지연 효과
- 여러개의 객체를 생성할 경우 모아서 한번에 쿼리를 전송한다.
- 영속성 상태의 객체가 생성 및 수정이 여러번 일어나더라도 해당 트랜잭션 종료시 쿼리는 1번만 전송될 수 있다.
- 영속성 상태에서 객체가 생성되었다 삭제되었다면 실제 DB에는 아무 동작이 전송되지 않을 수 있다.
- 즉, 여러가지 동작이 많이 발생하더라도 쿼리는 트랜잭션당 최적화 되어 최소쿼리만 날라가게된다.
키 생성전략이
generationType.IDENTITY로 설정 되어있는 경우 생성쿼리는 쓰기지연이 발생하지 못한다.
-> 단일 쿼리로 수행함으로써 외부 트랜직션에 의한 중복키 생성을 방지하여 단일키를 보장한다.
예제 코드
Team teamA = new Team();
teamA.setName("TeamA");
em.persist(teamA); //persist -> 영속상태가 됨
Team teamB = new Team();
teamB.setName("TeamB");
em.persist(teamB);
Member member_A = new Member();
member_A.setName("memberA");
member_A.setTeam(teamA);
em.persist(member_A);
em.flush();
Member findMember = em.find(Member.class, member_A.getId());
Team findTeam= findMember.getTeam();
System.out.println(findTeam.getName());flush가 있는 경우
create member
create team
insert team // flush로 인해 쓰기지연이 발생하지 않음
insert member // flush로 인해 쓰기지연이 발생하지 않음
print "TeamA" (memberA.getTeam())flush가 없는 경우 -> em.flush()가 없는 경우 트랜직션이 끝날때까지 insert 쿼리가 실행되지 않음
create member
create team
print "TeamA" (memberA.getTeam()) // 쓰기 지연이 발생하더라도 영속성 컨텍스트에서 조회해옴(persist로 인해서 영속성 컨텍스트에 존재함)
insert team // 쓰기 지연이 발생한 부분
insert member // 쓰기 지연이 발생한 부분
안녕하세요