
데이터의 수집 3단계
계획―수집―가공 및 저장
1. 계획 단계 : 어떤 데이터를 수집할 것인지, 데이터 원본 및 형식, 수집에 필요한 도구, 기술 선택
2. 수집 단계 : 웹 크롤링, API호출, 수동 데이터 입력 등 다양한 방법 사용 But 데이터 품질 유지 + 저작권 및 개인정보 보호에 관련 법률 준수必
스크래핑과 크롤링
- 스크래핑 : 웹페이지의 특정 부분에서 원하는 데이터를 추출하는 기술
- 크롤링 : 웹페이지를 자동으로 탐색하여 원하는 데이터를 추출하는 방법
반 자동화? 자동화? 프로그램
반자동화 프로그램
수작업의 일부를 프로그래밍 지원하는 형태
1단계 : 수집할 페이지를 지정하여 프로그램 시작 → 수동
2단계 : 대상 페이지를 내려받고 특정 데이터를 추출 → 프로그램
3단계 : 수집한 데이터를 일정 형식으로 저장 → 수동 및 프로그램
완전 자동화 프로그램
- 반 자동화 프로그램의 모든 부분을 자동화 프로그램으로 작성하여 실행
- 스케줄링을 이용하여 순환/반복 기능을 이용
- 변화에 취약
수집 데이터의 처리와 저작권
- 웹 사이트의 정보는 기본적으로 저작물
2016년 재정된 저작권법 제30조(정보 해석을 목적으로 저작물을 복제/변안 가능) : 공표된 저작물을 영리를 목적으로 하지 아니하고 개인적으로 이용하거나 가정 및 이에 준하는 한정된 범위 안에서 이용하는 경우에는 그 이용자는 이를 복제할 수 있다.
웹 사이트의 리소스 압박과 업무 방해
-
사이트를 크롤링하기 전 API지원 여부 확인
- 공공데이터포털
- 크롤러 사례 : 구글, 스카이스케너, 쿠차, 다나와 등등
-
웹 사이트의 자원을 독점하게 되면 다른 사람이 웹 사이트를 이용할 수 없음 ⇒ 무한 크롤러 사용 시 업무 방해 혐의 적용 가능🚨
서버와 클라이언트
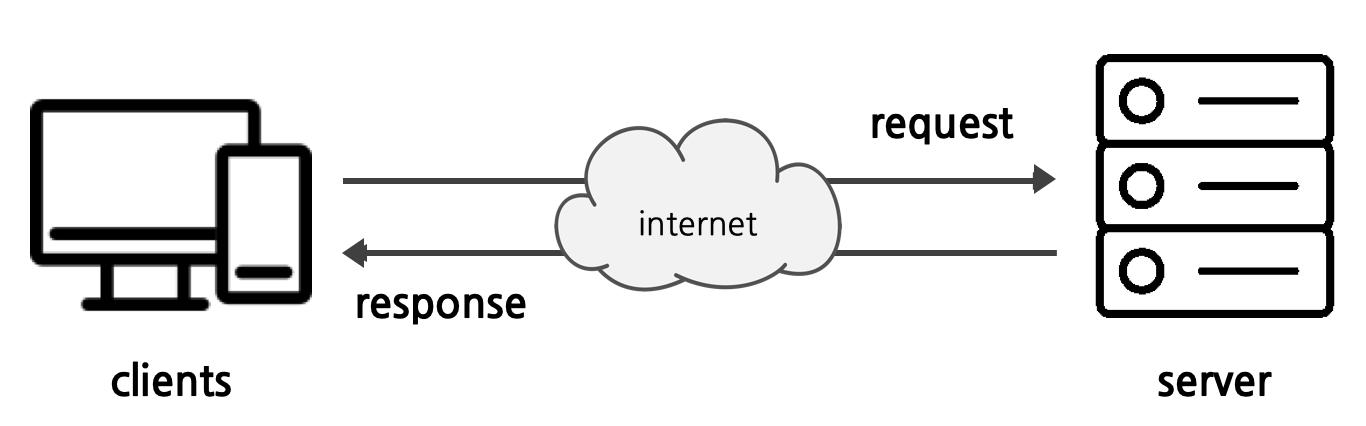
- 클라이언트 : 서비스를 요청하는 프로그램, 앱
- 서버 : 요청에 대해 응답을 해주는 프로그램
- 웹페이지 해석 순서
- 클라이언트가 서버에게 컨텐츠를 요청
- 서버는 요청받은 컨텐츠를 클라이언트에게 응답
- 브라우저는 서버에서 받은 HTML을 해석하여 화면에 보여줌
- HTTP = HyperText Transfer Protocol
- HTTPS 의무화 : 정보통신망법 제 28조 개인정보의 보호조치
- HTTPS 클라이언트 모듈
- Request Method
post: 자료 생성 요청--insert- body에 quey data가 들어간다.
- 데이터 길이 제한X
- 링크/북마크X
- url을 가지지 않으므로 주로 중요하지 않은 데이터를 가져갈 때 사용
get: 자료 요청 시 (헤더에 정보)--read- body 없이 Header만으로 전송
- 데이터 길이 제한O
- 링크/북마크O
- url의
?뒤에 쿼리 문자열 올 수 있음 ⇒ key, value 구조, 각 쿼리는&로 구분
put: 자료의 수정을 요청할 때 사용--updatedelete: 자료의 삭제를 요청할 때 사용--delete
- Status Code
- 1xx(조건부 응답)
- 2xx(성공)
- 3xx(리다이렉션 완료)
- 4xx(요청오류)
- 5xx(서버오류)
- Request Method
스크랩핑 관련 주요 모듈
webbrowser
파이썬 기본 제공, 브라우저로 특정 페이지를 열 때 사용
import webbrowser
webbrowser.open_new('http://python.org')Requests
인터넷에서 파일과 웹 페이지를 다운로드 함 ⇒ 외부 라이브러리기 때문에 설치 필요
설치
pip install requestsreqeusts(get) 예제
import requests # requests는 외부 모듈이기 때문에 설치 필요
session = requests.Session()
# requests 모듈의 Session 클래스를 이용하여 세션을 생성
# 세션을 사용하면 여러 요청 간에 상태를 유지 가능
# 웹 요청 시 함께 전송할 헤더 정보를 headers 변수에 딕셔너리 형태로 저장. 여기서는 User-Agent를 설정하고 있음
# User-Agent = 웹 브라우저 정보
# 해당 정보를 설정함으로써 웹 서버에게 웹 브라우저로부터 요청이 오는 것처럼 속이는 역할
headers = {
'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36'
}
url = 'https://www.naver.com'# 요청을 보낼 URL을 지정합니다.
# requests 모듈의 Session 객체인 session을 사용하여 지정한 URL에 GET 요청을 보냅니다.
# 이때, 앞서 설정한 헤더 정보를 함께 전송합니다. 응답 결과는 res 변수에 저장됩니다.
res = session.get(url, headers=headers)
print(res.text) # HTTP 응답 내용 출력BeautifulSoup(bs4)
- 웹페이지가 작성된 형식의 html구문 분석함(parsing)
- html 페이지에서 정보 추출하기 위한 파이썬 라이브러리
⇒ 정규식 작성 필요X, tag, id, class 등의 이름으로 쉽게 파싱 - 쉽고 간결, 문서화 잘 되어 있음
설치
pip install beautifulsoup4예제
import bs4
from bs4 import BeautifulSoup as bs # bs4모듈에서 BeautifulSoup 함수를 가져오는데 이름을 bs라고 지칭
url = 'https://www.naver.com'
res = requests.get(url) # `request` 로 html 소스 확보
html = res.text # 파싱하기 좋은 객체로 변환
soup = bs(html, 'html.parser')
print(soup)lxml
html.parser보다 빠름
설치
pip install lxml예제
import bs4
import lxml
url = 'https://www.naver.com'
res = requests.get(url)
html = res.text
# html.parser 대신 lxml로 파싱
soup = BeautifulSoup(html, 'lxml')
print(soup)Selenium
- 주로 웹앱을 테스트하는데 이용하는 프레임워크
webdriver라는 드라이버를 사용하여 웹 브라우저를 띄우고 제어함, 양식 채우기와 마우스 클릭 시뮬레이션이 가능- 속도 드림
- 동적 페이지도 크롤링 가능(자바스크립트 실행 가능)
설치
# selenium 설치
pip install selenium알라딘에서 베스트셀러 책 이미지, 제목, 링크 스크래핑
import requests
import bs4
url = 'https://www.aladin.co.kr/shop/common/wbest.aspx'
data = {
'BestType':'Bestseller',
'BranchType':'1'
}
req = requests.get(url,data=data)
#print(req.text)
html = req.text
soup = bs4.BeautifulSoup(html,'html.parser')
book_list = soup.find_all(class_='ss_book_box')
books = []
for book_info in book_list:
book = {}
book['book_img'] = book_info.img.get('src')
book['book_title'] = book_info.find(class_='bo3').text
book['book_link'] = book_info.find(class_='bo3').get('href')
books.append(book) #books리스트에 book정보를 삽입
for book in books:
print(f"Book Title: {book['book_title']}")
print(f"Book Image URL: {book['book_img']}")
print(f"Book Link: {book['book_link']}")
print("-----------------------")스크래핑한 데이터를 pickle로 저장 및 불러오기
import pickle
# 파일을 pickle 형식으로 저장
with open('books.pkl', 'wb') as file: #wb 이진쓰기모드 -> books.pkl 파일이 현재 작업 디렉터리에 pickle형식으로 저장됨
pickle.dump(books, file)# pickle 파일 불러오기
import pickle
with open('books.pkl', 'rb') as file:
loaded_books = pickle.load(file)
# 불러온 데이터 확인
for book in loaded_books:
print(f"Book Title: {book['book_title']}")
print(f"Book Image URL: {book['book_img']}")
print(f"Book Link: {book['book_link']}")
print("-----------------------")네이버 로그인 자동화
#셀레니움 모듈 설치 pip install selenium
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
#크롬 브라우저 꺼짐 방지
chrome_options = Options()
chrome_options.add_experimental_option('detach',True)
chrome_options.add_argument('--headless')
chrome_options.add_argument('window-')
drv = webdriver.Chrome()
drv.implicitly_wait(3)
drv.get('https://nid.naver.com/nidlogin.login?mode=form&url=https://www.naver.com/')
drv.find_element(By.ID,'id').send_keys('pakina96')
drv.find_element(By.ID,'pw').send_keys('pja9740807!')
drv.find_element(By.ID,'log.login').click()
drv.get_screenshot_as_file('naver_login.jpg') # 실행결과를 스크린샷을 찍어 파일로 저장할 수 있다.
drv.implicitly_wait(3) #3초 안에 웹페이지를 load 하면 바로 넘어가거나, 3초를 기다림.유튜브에서 키워드 검색 후 스크롤
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
#pip install webdriver-manager
from webdriver_manager.chrome import ChromeDriverManager #호환성 해결
from bs4 import BeautifulSoup
from selenium.webdriver.common.keys import Keys
import random
import time
#브라우저 꺼짐방지
chrome_options = Options()
chrome_options.add_experimental_option('detach',True)
#윈도우창을 켤 필요가 없는 경우
#chrome_options.add_argument('--headless')
#chrome_options.add_argument('window-size=1920x1880')
drv = webdriver.Chrome(options=chrome_options)
drv.implicitly_wait(3)
drv.get('https://www.youtube.com/')
#main
#검색
search_word = 'marilyn monroe movie'
search = drv.find_element(By.NAME,'search_query')
search.send_keys(search_word)
time.sleep(1)
search.send_keys(Keys.RETURN)
#검색할 페이지 제한
page_limit = 3
#스크롤 하는 함수
def scroll(drv,page_limit):
#페이지 내 스크롤 높이를 가져온다.
last_page_height = drv.execute_script('return document.documentElement.scrollHeight')
#페이지 끝까지 내리기
try :
while True:
pause_time = random.uniform(1,2) #1-2초 정도 멈추도록
drv.execute_script('window.scrollTo(0,document.documentElement.scrollHeight);')
time.sleep(pause_time)
drv.execute_script('window.scrollTo(0,document.documentElement.scrollHeight+50);')
time.sleep(pause_time)
new_page_height = drv.execute_script('window.scrollTo(0,document.documentElement.scrollHeight);')
if new_page_height == last_page_height:
print('scroll finish!!!')
break
else:
last_page_height = new_page_height
cnt=0
if cnt > page_limit:
break
cnt+=1
except :
print('ERROR: ',e)
#함수실행
scroll(drv,page_limit)xkcd에서 이미지 크롤링
#%%
import os
import requests
import bs4
url='https://xkcd.com/3/'
os.makedirs('xkcd',exist_ok=True) #이름이 'xkcd'인 디렉토리 생성
while not url.endswith('#'):
print('페이지 다운로드중...')
# 1) 페이지 다운로드(request)
req = requests.get(url)
req.raise_for_status() # 응답 코드 200 ? True : False
soup = bs4.BeautifulSoup(req.text, 'html.parser')
# print(soup) 확인용
# 2) 만화 이미지 url찾기(bs4)
comic_img_src = soup.find(id='comic').find('img').get('src')
print(comic_img_src)
comic_img_name = comic_img_src.split('/')[-1] # url에서 파일이름 추출 barrel_cropped_(1).jpg
print(f'Imge Name : {comic_img_name}')
comic_img_url = f'http:{comic_img_src}' # 전체 이미지 url 생성
print(f'Image URL : {comic_img_url}')
# 3) 이미지 다운로드
req = requests.get(comic_img_url)
req.raise_for_status()
# 4) ./xkcd폴더에 이미지 저장하기
img_file = open(os.path.join('xkcd',comic_img_name), 'wb')
# iter_content(100000)은 requests 라이브러리에서 제공하는 메서드로, 웹에서 데이터를 읽어올 때 몇 바이트씩 나누어 읽어오게 합니다. 이렇게 나누어 읽어오는 이유는 큰 파일을 전부 한 번에 메모리에 로딩하지 않고 조금씩 나누어 읽어오기 때문에 메모리 사용을 효율적으로 관리할 수 있습니다.100000은 한 번에 읽어오는 바이트 수입니다. 여기서는 100,000 바이트(약 100KB)씩 읽어오도록 설정되어 있습니다. 만약 이미지 파일이 매우 큰 경우, 이 값을 더 크게 설정하여 더 큰 덩어리로 읽어올 수 있습니다.
for chunk in req.iter_content(100000):
img_file.write(chunk)
img_file.close()
print(f"'{comic_img_name}' 다운로드 완료!")
# 5) 이전 버튼의 url 열기
prev_link = soup.select_one('a[rel="prev"]')
if prev_link:
url = f'https://xkcd.com{prev_link["href"]}'
else:
print("마지막 페이지에 도달했습니다.")🤯 스크래핑 시 주의사항
Bot No!! Human ok!!
- 자바스크립트가 실행되기 전의 페이지는 아무것도 없어 비어있을 수 있다.
- 폼을 전송하거나 post 요청을 보낼 때는 서버에서 기대하는 모든 데이터를 보내야 한다.
- 크롬 개발자 툴에서 network탭을 통해 요청되는 정보를 확인
- 폼의 hidden 필드를 확인
- 쿠키가 함께 전송되는지 확인
- 403 Forbidden 에러를 받는 다면 IP가 차단되었을 수 있다.
- 새로운 ip로 요청을 시도하거나 가까운 카페에 가서 스크래핑을 수행하는 것이 좋다.
- 사이트를 너무 빨리 이용하지 않아야 한다.
- 페이지 이동 시 지연시간을 추가
- 헤더 수정하기

공부 기록