『Do it! 알고리즘 코딩 테스트 with JAVA 강의』를 듣고 정리한 글입니다.
정렬 알고리즘
| 정렬 알고리즘 | 정의 |
|---|---|
| 버블 (Bubble) | 데이터의 인접 요소끼리 비교하고, swap 연산을 수행하며 정렬하는 방식 |
| 선택 (Selection) | 대상에서 가장 크거나 작은 데이터를 찾아가 선택을 반복하면서 정렬하는 방식 |
| 삽입 (Insertion) | 대상을 선택해 정렬된 영역에서 선택 데이터의 적절한 위치를 찾아 삽입하면서 정렬하는 방식 |
| 퀵 (Quick) | pivot 값을 선정해 해당 값을 기준으로 정렬하는 방식 |
| 병합 (Merge) | 이미 정렬된 부분 집합들을 효율적으로 병합해 전체를 정렬하는 방식 |
| 기수 (Radix) | 데이터의 자릿수를 바탕으로 비교해 데이터를 정렬하는 방식 |
버블 정렬 (Bubble sort)
- 두 인접한 데이터의 크기를 비교해 정렬하는 방법이다.
- 간단하게 구현할 수 있지만, 시간 복잡도는 으로 다른 정렬 알고리즘보다 속도가 느린 편이다.
- Loop를 돌면서 인접한 데이터 간의 swap 연산으로 정렬한다.
- 만약 특정한 루프의 전체 영역에서 swap이 한 번도 발생하지 않았다면 그 영역 뒤에 있는 데이터가 모두 정렬됐다는 뜻이므로 프로세스를 종료해도 된다.
오름차순으로 수 정렬하기
❓ N개의 수가 주어졌을 때, 이를 오름차순으로 정렬하는 프로그램
for (int i = 0; i < N-1; i++) {
for (int j = 0; j < N-1-i; j++) {
// 인접한 두 데이터를 비교
if(A[j] > A[j+1]) {
int temp = A[j];
A[j] = A[j+1];
A[j+1] = temp;
}
}
}선택 정렬 (Selection Sort)
- 대상 데이터에서 최대나 최소 데이터를 데이터가 나열된 순으로 찾아가며 선택하는 방법이다.
- 구현 방법이 복잡하며 시간 복잡도가 으로 효율적이지 않아서 코딩 테스트에서는 많이 사용하지 않는다.
핵심 이론
- 최솟값 또는 최댓값을 찾고, 남은 정렬 부분의 가장 앞에 있는 데이터와 swap한다.
- 오름차순이면 최솟값을 찾고, 내림차순이면 최댓값을 찾는다.
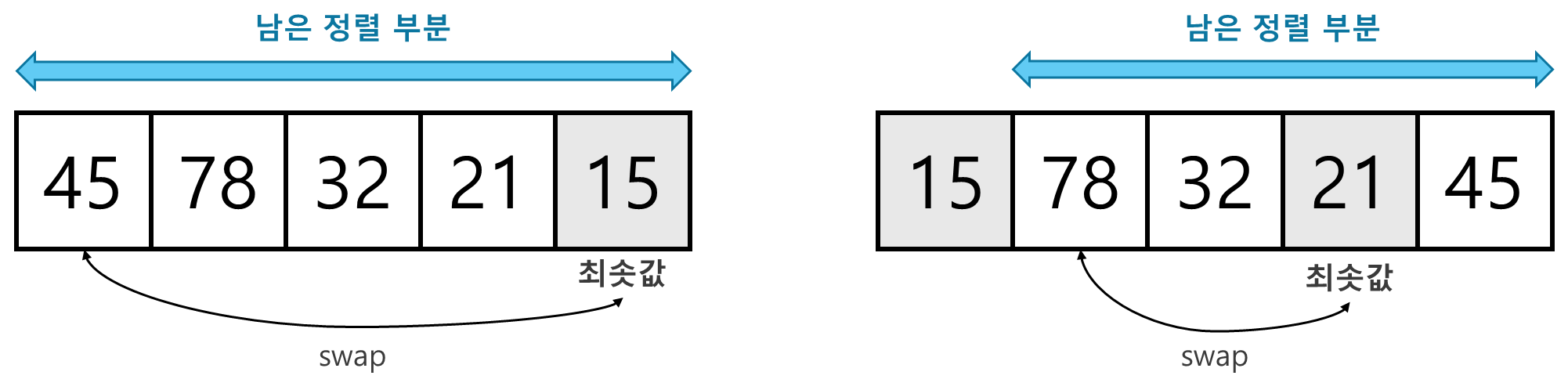
- 선택 정렬 과정
- 남은 정렬 부분에서 최솟값 또는 최댓값을 찾는다.
- 남은 정렬 부분에서 가장 앞에 있는 데이터와 선택된 데이터를 swap한다.
- 가장 앞에 있는 데이터의 위치(index)를 변경해 남은 정렬 부분의 범위를 축소한다.
- 남은 정렬 부분이 없을 때까지 1~3번 과정을 반복한다.
- N-1번 반복을 돌면서 최솟값 혹은 최댓값을 구하기 위해 각각 N, N-1, N-2, … 1번의 비교 연산을 수행한다.
- 약 인데, 상수는 제거되므로 시간복잡도는 이다.
내림차순으로 자릿수 정렬하기
❓ N개의 수가 주어졌을 때, 이를 내림차순으로 정렬하는 프로그램
// i : 정렬된 부분의 범위
for (int i = 0; i < N; i++) {
// 최댓값의 인덱스
int Max = i;
// j : 남은 정렬 부분의 범위
for (int j = i+1; j < N; j++) {
// 최댓값의 인덱스 찾기
if (A[j] > A[Max]) {
Max = j;
}
}
// 최댓값이면 swap
if(A[i] < A[Max]) {
int temp = A[i];
A[i] = A[Max];
A[Max] = temp;
}
}삽입 정렬 (Insertion Sort)
- 이미 정렬된 데이터 범위에 정렬되지 않은 데이터를 적절한 위치에 삽입시켜 정렬하는 방식이다.
- 구현하기는 쉽지만 시간 복잡도는 이므로 코딩 테스트에서 많이 사용되지는 않는다.
핵심 이론
- 선택 데이터를 현재 정렬된 데이터 범위 내에서 적절한 위치에 삽입하는 것이 핵심이다.
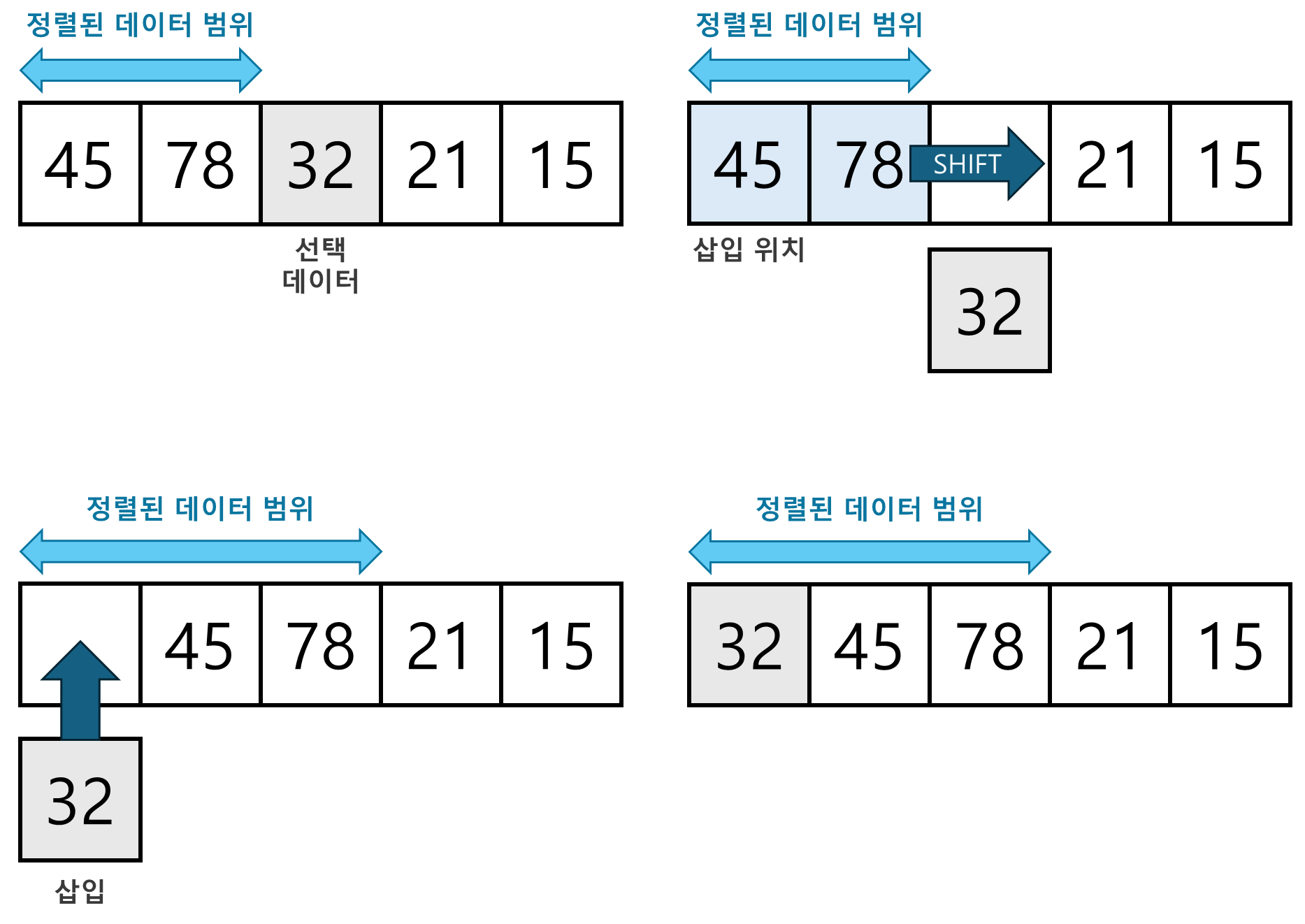
- 삽입 정렬 수행 방식
- 현재 index에 있는 데이터 값을 선택한다.
- 현재 선택한 데이터가 정렬된 데이터 범위에 삽입될 위치를 탐색한다.
- 삽입 위치부터 index에 있는 위치까지 shift 연산을 수행한다.
- 삽입 위치에 현재 선택한 데이터를 삽입하고 index++ 연산을 수행한다. → 정렬된 범위가 증가
- 전체 데이터의 크기만큼 index가 커질 때까지, 즉 선택할 데이터가 없을 때까지 반복한다.
- 적절한 삽입 위치를 탐색하는 부분에서 이진 탐색과 같은 탐색 알고리즘을 사용하면 시간 복잡도를 줄일 수 있다.
- 탐색하는 시간을 에서 으로 줄일 수 있다.
- 하지만 shift 연산 때문에 결국 시간은 오래 걸리게 된다.
오름차순으로 수 정렬하기
❓ N개의 수가 주어졌을 때, 이를 오름차순으로 정렬하는 프로그램
// temp : 정렬할 데이터, j : 정렬된 범위
int temp, j;
for (int i = 1; i < N; i++) {
// 정렬할 데이터 선택
temp = A[i];
// 삽입 위치 탐색하면서 Shift 연산 수행
for (j = i-1; j >= 0; j--) {
if(A[j] > temp) {
// 선택 데이터보다 클 경우 한 칸 뒤로 Shift
A[j+1] = A[j];
}
else {
// 선택 데이터보다 작을 경우 반복문 종료
break;
}
}
// 적절한 위치에 삽입
A[j+1] = temp;
}퀵 정렬 (Quick Sort)
- 기준값(pivot)을 선정해 해당 값보다 작은 데이터와 큰 데이터로 분류하는 것을 반복해 정렬하는 알고리즘이다.
- 기준값이 어떻게 선정되는지가 시간 복잡도에 많은 영향을 미친다.
- 평균 시간 복잡도는
- 최악의 경우, 시간 복잡도는
- 퀵 정렬의 시간 복잡도는 비교적 준수하므로 코딩 테스트에서 종종 으용한다.
핵심 이론
- pivot을 중심으로 계속 데이터를 2개의 집합으로 나누면서 정렬하는 것이 핵심이다.
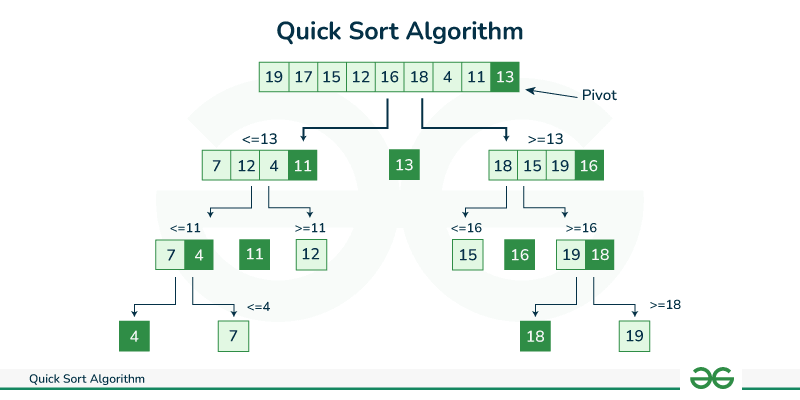
- 퀵 정렬 과정
- 데이터를 분할하는 pivot을 설정한다.
- pivot을 기준으로 다음 과정을 거쳐 데이터를 2개의 집합으로 분리한다.
1). start가 가리키는 데이터 < pivot이 가리키는 데이터 -> start++
2). end가 가리키는 데이터 > pivot이 가리키는 데이터 -> end--
3). (start가 가리키는 데이터 > pivot이 가리키는 데이터) && (end가 가리키는 데이터 < pivot이 가리키는 데이터)
-> start, end가 가리키는 데이터를 swap하고 start++, end--
4). start와 end가 만날 때까지 (1~3) 과정을 반복
5). start와 end가 만나면 만난 지점에서 가리키는 데이터와 pivot이 가리키는 데이터를 비교하여 pivot이 가리키는 데이터가 크면 만난 지점의 오른쪽에, 작으면 만난 지점의 왼쪽에 pivot이 가리키는 데이터를 삽입 - 분리 집합에서 각각 다시 pivot을 선정한다.
- 분리 집합이 1개 이하기 될 때까지 과정 1~3을 반복한다.
- 재귀 함수의 형태로 직접 구현해보는 것을 추천한다.
오름차순으로 자릿수 정렬하기
// 위키백과의 퀵정렬 알고리즘
public void quickSort(int[] arr, int left, int right) {
// base condition
if (left >= right) {
return;
}
int pivot = arr[right];
int sortedIndex = left;
for (int i = left; i < right; i++) {
if (arr[i] <= pivot) {
swap(arr, i, sortedIndex);
sortedIndex++;
}
}
swap(arr, sortedIndex, right);
quickSort(arr, left, sortedIndex - 1);
quickSort(arr, sortedIndex + 1, right);
}
private void swap(int[] arr, int i, int j) {
int tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}병합 정렬 (Merge Sort)
- 분할 정복(divide and conquer) 방식을 사용해 데이터를 분할하고 분할한 집합을 정렬하며 합치는 알고리즘이다.
- 안정적이며 시간 복잡도는 이다.
- 코딩 테스트에서 이 이론을 이해하고 응용해서 푸는 문제가 종종 나온다.
핵심 이론
- 나눌 수 없을 만큼의 부분 그룹으로 분할한다.
- 부분 그룹들을 각각 병합하면서 정렬한다.
- 정렬을 하면서 만큼의 연산이 일어난다.
- 병합-정렬 과정을 총 만큼 반복한다.
- 따라서 시간 복잡도는 이다.
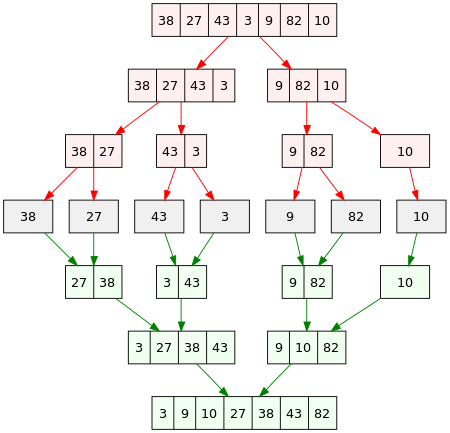
2개의 그룹을 병합하는 과정
- 투 포인터 개념을 사용하여 왼쪽, 오른쪽 그룹을 병합한다.
- 왼쪽 포인터와 오른쪽 포인터의 값을 비교하여 작은 값을 결과 배열에 추가하고 포인터를 오른쪽으로 1칸 이동시킨다.
- 각 포인터는 그룹 별로 하나씩 둔다.
- 즉, 그룹에서 포인터를 두고 서로의 값을 비교하여 작은 것부터 배열에 담는다.
- 이 과정을 어떻게 응용할 수 있을지 생각할 것.
- 예를 들어, 자동차 경주에서 몇 번 역전했는지를 확인한다면?
오름차순으로 자릿수 정렬하기
private static void mergeSort() {
int A[] = new int[N];
devide(A, 0, N);
}
private static void devide(int[] arr, int low, int high) {
if (high - low < 2) {
return;
}
int mid = (low + high) / 2;
devide(arr, 0, mid);
devide(arr, mid, high);
merge(arr, low, mid, high);
}
private static void merge(int[] arr, int low, int mid, int high) {
int[] temp = new int[high - low];
int t = 0, l = low, h = mid;
// 왼쪽 배열과 오른쪽 배열 중 하나를 다 비울때까지 반복
while (l < mid && h < high) {
// 작은 값을 temp 배열에 우선해서 담기
if (arr[l] < arr[h]) {
temp[t++] = arr[l++];
} else {
temp[t++] = arr[h++];
}
}
// 만약 왼쪽 배열이 남아있다면 담기
while (l < mid) {
temp[t++] = arr[l++];
}
// 만약 오른쪽 배열이 남아있다면 담기
while (h < high) {
temp[t++] = arr[h++];
}
// temp 배열을 원본 배열로 복사 (정렬 완료)
for (int i = low; i < high; i++) {
arr[i] = temp[i - low];
}
}기수 정렬 (Radix Sort)
- 값을 비교하지 않는 특이한 정렬이다.
- 기수 정렬은 값을 놓고 비교할 자릿수를 정한 다음 해당 자릿수만 비교한다.
- 시간 복잡도는 이다. (k=데이터의 자릿수)
- 시간 복잡도가 가장 짧은 정렬이므로, 코딩 테스트에서 정렬해야 하는 데이터의 개수가 너무 많다면 기수 정렬 알고리즘을 활용해 보자.
핵심 이론
- 10개의 큐를 이용하며, 각 큐는 값의 자릿수를 대표한다.
- 큐가 10개인 이유는, 한 자릿수에 올 수 있는 값은 0~9까지이기 때문이다. 값을 표현하기 위해 10개의 큐를 사용한다.
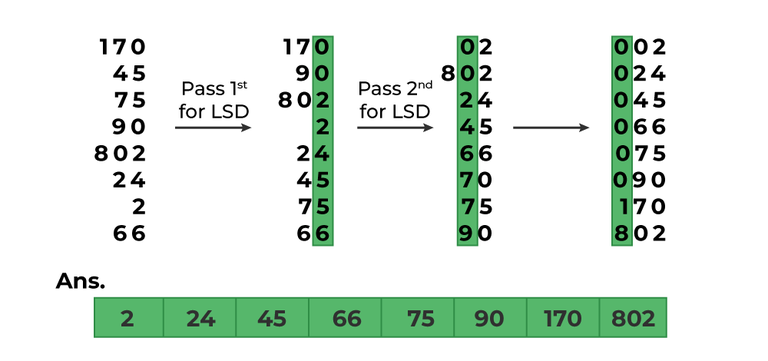
- 정렬 과정
- 대상 데이터가 주어졌을 때, 각 데이터의 일의 자릿수를 기준으로 큐에 (해당 데이터를) 넣는다.
- 큐에 넣은 데이터를 순차적으로 빼면 일의 자릿수를 기준으로 데이터를 정렬한 결과가 나온다.
- 일의 자리에서 정렬된 순서 기준(2번의 결과)으로 십의 자릿수를 기준으로 큐에 데이터를 저장한다.
- 큐에 넣은 데이터를 순차적으로 빼면 십의 자릿수를 기준으로 데이터를 정렬한 결과가 나온다.
- 위 과정을 자릿수(k)만큼 반복한다.
오름차순으로 자릿수 정렬하기
// 자릿수 (개수)
int MaxNumber = A[0];
for (int num : A){
if (num > MaxNumber) {
MaxNumber = num;
}
}
// bucket 초기화
Queue<Integer>[] buckets = new Queue[10];
for (int i = 0; i < 10; i++) {
buckets[i] = new LinkedList<>();
}
// 자릿수를 기준으로 정렬
for (int exp = 1; exp <= MaxNumber; exp *= 10) {
// 버킷에 분류하여 저장
for (int num : A) {
int digit = (num / exp) % 10;
buckets[digit].add(num);
}
// 버킷에서 꺼내기 (정렬)
int index = 0;
for (int digit = 0; digit < buckets.length; digit++) {
while (!buckets[digit].isEmpty()) {
A[index++] = buckets[digit].poll();
}
}
}
for (int i = 0; i < N; i++) {
System.out.print(A[i] + " ");
}Reference

책을 읽거나 강의를 들으며 공부한 내용을 정리합니다. 가끔 개발하는데 있었던 이슈도 올립니다.