IPv4주소의 기본 주소
- IP주소는 인터넷 프로토콜을 쓰는 인터넷망에서 인터넷에 연결된 컴퓨터 한 대를 식별하기 위해서 부여하는 고유번호이다.
IPv4주소의 구조
- IP는 32bit 주소 체계를 사용한다.
- 32bit는 8bit가 4개 있는 것.
- 전부 1이면 브로드캐스팅인지 고민해라.
ipconfig로 IP주소를 확인할 수 있다.- 192.168로 시작하면 사설 주소인가?
- 8bit 씩 쪼개서 가운데에 점(.)을 찍는다.
- 점을 구분으로 해서 8bit씩이므로, 각 숫자는 0~255까지 될 수 있다.
- IP주소는 Network ID와 Host ID로 구분한다.
- 우리나라 주소체계로 생각하자면 ‘서울시 강남구 역삼동 00번지’이다.
- ‘서울시 강남구 역삼동’가 Network ID, ‘번지’가 Host ID라는 느낌으로 기억하자.
- 인터넷망이 고속도로, 패킷을 택배라고 하자.
- 이때, 물류센터에 택배가 도착하면 어느 동네로 갈 것인지에 따라 분배한다.
- 즉, 각 ID는 다음과 같이 생각하자.
- Network ID로 우리 동네까지 올 건지 아닌지를 판별한다.
- Host ID로 동네에 도착한 후에 어느 집으로 갈 것인가를 본다.
L3 IP Packet
L3 Packet
- Packet은 개념적으로 단위 데이터이다.
- Packet이라는 말은 L3 IP Packet으로 외워라.
- 보통 L3라는 말은 안 붙인다.
- Packet을 언급하면 “IP 프로토콜이고 레이어 3이다”
- (L2 프레임에서와 마찬가지로) Header와 Payload로 나뉘며 이는 상대적인 분류이다.
- 논리적 구조
- Header가 송장이라면 Payload는 전달되는 대상
- Header에는 Source가 어디인데, Destination으로 간다는 정보가 포함되어 있다. → 출발지/목적지 주소
- 최대 크기는 MTU (Maximum transmission unit)
- Header와 Payload를 포함하여 전체 크기를 MTU이다.
- 특별한 이유가 없다면 1500 byte(1.4KB 정도)이다.
정리하자면, 인터넷이라는 거대한 논리 네트워크에서 정보의 유통체계이며 최소 단위 최대 크기가 1500byte밖에 안된다.
Encapsulation과 Decapsulation
Encapsulation
- 이해를 돕기 위한 비유
- 물건을 포장해서 택배로 쏙 넣었다.
- 쏙 넣었다는 의미에서 몇 가지 특징이 있다.
- 어떤 단위로 바꿨다. → 단위화했다.
- 택배를 보낼 때 박스 단위로 만든다.
- 안에 어떤 것이 들어있는지는 모른다.
- 택배 안에 들어있는 것이 책인지 음식인지 알 수 없다.
- 보안적으로 봤을 때 보이지 않는다.
- 정확히는 보이지 않는 건 사실은 아니지만, 단위 안에 넣어서 못 보게 하겠다는 의도가 포함되어있다는 점을 기억하자.
- 어떤 단위로 바꿨다. → 단위화했다.
En/Decapsulation
- L2 Frame 내부에 L3 IP Packet이 있다.
→ IP Packet 통째로 L2 Frame의 Payload가 된다. - L3 IP Packet 내부에는 L4 계층의 데이터(Segment)가 된다.
- L4 → L3 → L2 씩으로 하나씩 포장하는 것이 Encapsulation이다.
- L2 → L3 → L4 씩으로 하나씩 꺼내는 것이 Decapsulation이다.
패킷의 생성과 전달
두 가지 관점에서 다뤄본다.
패킷의 생성, 전달, 소멸
비유를 하자면, 다음 순서대로 진행된다.
- 철수가 영희에게 택배를 보낼 것이다.
- 보낼 물건(책)을 준비한다.
- 박스를 구해서 그 안에 물건을 넣고 포장한다.
- 택배에 송장을 붙여 기사님께 드린다.
- 기사님은 택배들을 모아 하나의 트럭에 넣고 이동한다.
- 물류체계를 타고 영희에게 전달된다.
- 전달의 모든 과정은 기사님 이하, 그 이후에 일어나는 일이고 철수는 아무런 개입을 하지 않는다.
- 택배는 물류체계에 의해 전달을 하며 송장의 목적지 주소를 보고 영희의 집까지 간다.
- 송장에는 주소(Src/Dst, 출발지/목적지)와 이름(보내는/받는 사람)이 적혀 있다.
- 만약, 영희의 집에 다른 가족들도 있다고 한다면, 받는 이를 보고 영희에게 전달될 것이다.
위 상황에서 용어를 정의하자면 다음과 같다.
- 용어 정리
- 영희와 철수는 Process
- 책은 Data, 택배는 Packet
- 택배 기사는 Gateway
- 집은 Host, 택배를 기사에게 전달하는 현관은 인터페이스
- 송장의 주소는 Host까지 찾아가는데 쓰이고, 받는 이는 도착한 후 Process를 찾는데 쓰인다.
구체적인 과정
어떤 프로세스가 인터넷을 통해 정보(Data)를 전달하려고 한다.
먼저, User mode application process가 접근할 수 있도록 Kernel mode Protocal(TCP/IP)을 추상화시켜준 인터페이스가 있다.
이 인터페이스는 파일의 일종이며, 소켓이라고 부른다.
- Data를 File에 Write한다.
- TCP 소켓(네트워크)에서는 Write라고 하지 않고, Send라고 한다.
- Data가 소켓을 타고 내려가서 TCP를 만나면 TCP Header를 붙여서 Segment라고 부른다.
- Segment화
- 한 층 더 내려가서 IP를 만나면 IP Header를 붙인다.
- 한 층 더 내려가면 Frame Header(이더넷 헤더)가 붙는다.
- 이렇게 포장된 것이 타고 나가서 L2 Access 스위치를 만나게 된다.
- Process가 Data를 Packet으로 만든 후 Gateway에게 준다.
- Access 스위치를 타고 올라가 라우터 게이트웨이를 타고 인터넷으로 나간다.
- Host와 만나는 접점, 즉 인터페이스를 타고 Packet이 나간다.
- Gateway는 물류체계에 의해 데이터를 라우팅한다.
- IPv4를 보고 목적지 Host에게 이동하고, 도착한 후에는 Port 번호를 보고 Data를 전달한다.
계층별 데이터 단위
- 운영체제 수준
- L1~L2 수준에서 논하는 데이터의 단위는 Frame이다.
- IP 수준에서 논하는 데이터의 단위는 Packet이다.
- TCP 수준에서 논하는 데이터의 단위는 Segment이다.
- User mode Application (L5~L7)
- Socket 수준에서 논하는 데이터의 단위는 Stream이다.
- 사실 Stream은 단위라고 하긴 힘들고, 데이터 덩어리 그 자체를 의미하는 것이다.
- 하나의 단위가 될 때는 적어도 세그먼트를 논해야 하고, 그 다음에 패킷, 프레임 이렇게 논한다.
- 세그먼트를 패킷이라고 부르는 사람도 많다.
- 특별히 구별해서 불러야 할 때가 아니라면 그냥 패킷이라고 부른다.
Stream
- Stream은 시작은 있으나 끝이 어디인지 정확하게 정의할 수가 없다.
- 이 끝은 프로세스 수준, 즉 어플리케이션 수준에서 정의해버리기 때문에 데이터를 송수신하는 운영체제 입장에서는 Stream은 연속적으로 이어진 크기를 정확히 알 수 없는 큰 데이터이다.
- Stream을 Socket에 대고 Write한다.
데이터의 최대 크기
- 인터넷의 데이터 단위 최대 크기는 MTU라고 정해져있다.
- 1500bytes 정도.
- Segment 에도 Maximum Segment Size(MSS)가 있다.
- 특별한 이유가 없다면 1460byte 정도이다.
- 스트림이 이 최대 크기보다 크다면, 스트림을 잘라서 분할한다.
- 세그먼트화될 때 일정 단위(Maximun Segement Size)로 분할이 일어난다.
→ Segmentation
- 세그먼트화될 때 일정 단위(Maximun Segement Size)로 분할이 일어난다.
Datagram
- TCP가 아닌 UDP 프로토콜에서 데이터그램이라고 이야기한다.
- 정해진 데이터 덩어리이다.
TCP/IP 송수신 구조
그림으로 이해하기
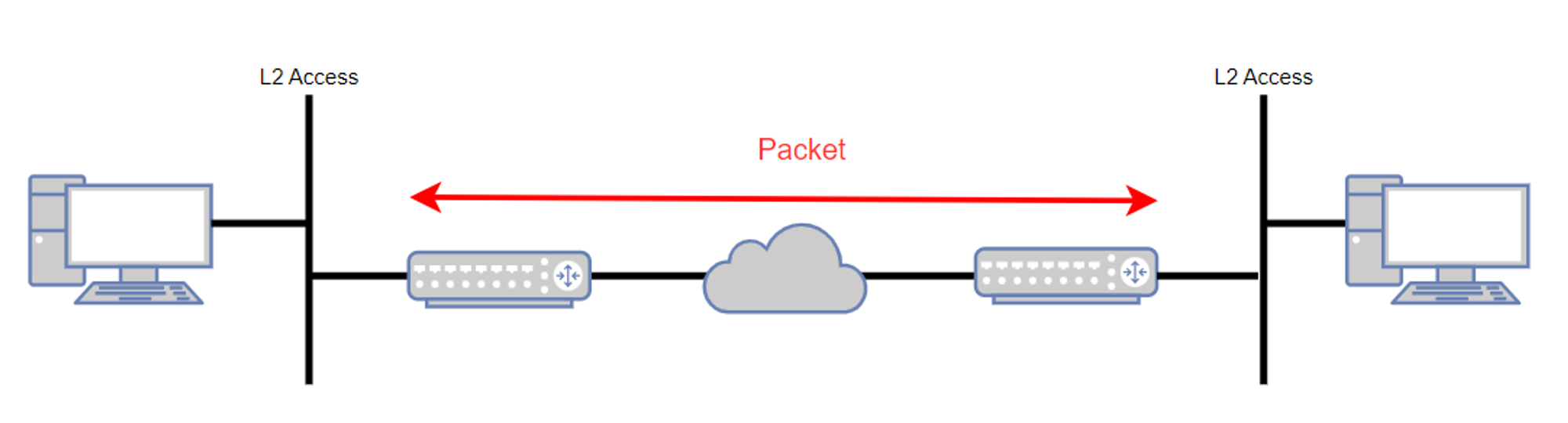
- Naver에서 파일을 다운로드 한다고 하자.
- Server에서는 파일을 송신하고, PC에서는 파일을 수신한다.
- 정확히는 PC 내의 Process가 파일을 송신하고 수신한다.
- 인터넷 구간에서 정보가 유통될 때는 패킷의 형태로 간다.
- 만약 파일이 1.4MB라면, 패킷의 MTU(1.4KB)와 1024배 이상 차이가 난다.
- 즉, 1000개 이상의 패킷으로 바뀌어서 전송된다.
TCP/IP로 보낸다고 가정한다면
- TCP는 연결지향, Connection Oriented Protocal이다.
- 즉, TCP 연결이 됐다는 가정 하에 송수신이 이루어진다.
Socket
- 소켓의 본질은 File이다.
- 소켓에 대고 입출력(I/O)가 일어난다.
- 이런 입출력이 일어날 때는 이 File 혹은 소켓에 Attached된 메모리 공간, 즉 버퍼가 있기 마련이다.
- 이 버퍼가 있으면 Buffered I/O를 하는 것이고, 버퍼 없이 입출력을 직접한다면 Non-Buffered I/O를 하게 된다.
- 버퍼는 두 가지이다.
- 프로그램(프로세스)에서 연결된 애가 관리하는 버퍼
- 소켓 입출력 버퍼
파일 전송
송신 측
송신하는 쪽에선 항상 Encapsulation이 일어난다.
- 1.4MB의 비트맵 파일을 보낸다고 가정한다면, 프로세스가 관리하는 버퍼에는 1.4MB를 모두 메모리에 올릴 수도 있고 일부를 올릴 수도 있다.
- 파일(일정 수준의 Block)을 Copy해서 버퍼에 올린다.
- 프로세스가 관리하는 버퍼를 Copy해서 소켓 입출력 버퍼에 올린다.
- Send할 Data Copy
- 이때의 데이터 단위는 Stream이며, 파일 전체를 읽어서 보낼 때 파일이 끝이 난다.
- L4(TCP)로 내려갈 때 분해가 일어난다.
- Segmentation
- 이렇게 자른 Segment에 번호를 붙인다.
- Segment는 하나씩 보내지고, 1번을 보낸 후 2번을 바로 보낼 수도 있고 wait를 줄 수도 있다.
- L3(IP)로 내려가면 박스 형태로 Segment를 포장 후 송장을 붙인다.
- 즉, Packet이 된다.
- L2로 내려가면 트럭(Frame) 안에 택배를 담는다.
- 즉, Frame 형태로 내려간다.
- 이 Frame은 유통과정에서 수시로 바뀐다. → 한 번에 배달되지 않고 트럭이 바뀌어가며 배달된다.
- 데이터를 전송 후 일정 수준이 지나면 wait를 걸고 잘 받았는지(ACK)를 기다린다.
- 1번과 2번을 보냈다면 ACK 3이 오기를 기다린다.
- ACK 3이 온다면 3번을 보낸다.
수신 측
수신하는 쪽에선 항상 Decapsulation이 일어난다.
- L2 수준에서 트럭에서 하차가 일어난다.
- Frame이 도착해서 Packet을 끄집어낸다. → Frame은 사라진다.
- L3(IP)로 올라가서 Packet에서 Segment를 꺼낸다.
- Segement가 소켓 입출력 버퍼에 쌓인다.
- 운영체제의 TCP 스택에서 버퍼를 채워준다.
- 소켓 입출력 버퍼의 내용을 프로세스 버퍼로 옮겨줘야 한다.
- 개념적으로는 Read라고 하는데, 네트워크에서는 Receive라고 한다.
- 리시브를 시도할 때는 프로세스 버퍼의 전체 사이즈만큼 리시브를 시도한다.
- 1번과 2번이 입출력 버퍼에 있다면, 둘을 합쳐서 프로세스 버퍼에 MOVE한다.
- 중요한 것은 속도 차가 있다는 것이다.
- 네트워크에서는 소켓 입출력 버퍼를 계속 채우고, 프로세스는 계속해서 비워서 여유 공간을 지속적으로 확보한다.
- TCP에서는 데이터를 받은 후 잘 받았다고 피드백을 준다.
- 이 피드백을 ACK(acknowledgement)라고 한다.
- ACK#3 → 1번과 2번까지 잘 받았다는 의미이다.
- ACK를 보낼 때 여유공간도 함께 보낸다. 송신 측에서는 이 여유공간이 있으면 데이터를 보내고, 없으면 못보낸다.
Network 장애
Network에서 장애가 발생하는 경우가 잦은데, 대표적으로 다음 것들이 있다.
- H/W 수준에서 Loss(유실, Lost Segment) 발생
- 100% 네트워크 상에서 문제가 있다.
- Re-transmission
- ACK가 오지 않으면 다시 보낼 때가 있다. (1번과 2번을 다시 보냄)
- 복잡한 타이머로 정교하게 도는 것이어서, 간발의 차로 ACK와 재전송이 같이 일어날 수 있다.
- 그러면 ACK-Dupplication(중복)이 일어난다.
- 네트워크 문제일 수도 있고, End-point 간에 합이 안 맞아서 문제가 난 걸 수도 있다.
- Out of order
- 1번 오고 2번 왔는데, 그 다음에 3번이 아닌 4번이 와버린다.
- 이렇듯 순서가 잘못된 경우를 Out of order라고 한다.
- 이 경우에는 TCP 스택에서 보정을 하게 된다.
- 네트워크 문제일 수도 있고, End-point 간에 합이 안 맞아서 문제가 난 걸 수도 있다.
- 주로 네트워크 상에서 이슈가 난다.
- Zero window
- 여유공간의 메모리 공간을 Window size라고 부르는데, 이게 0이 된 것이다.
- 즉, 네트워크의 송수신 속도가 프로세스(프로그램)이 버퍼를 비우는 속도보다 빨라서 Full이 난 것이다.
- 확실하게 End-point에서 Application 문제다. → 문제를 프로그램에서 찾아야 한다.
IP 헤더 형식
IPv4 Header

- MTU(Header+Payload)는 1500bytes, Header는 20bytes가량 한다.
- Options 이 붙으면 더 늘어나기도 한다.
- 그림을 보면 Data는 최대 65515 bytes(64K가량)도 될 수 있다고 되어 있다.
- 실제로는 그렇진 못하고, MTU에 맞춰서 운영된다.
- 늘어나는 사례도 있긴 하다.
구성
- Version
- IPv4이므로 항상 4byte이다.
- IHL (Internet Header Length)
- Header의 크기를 말한다.
- 보통 5행이다.
- TOS (Type of service)
- Total Length
- Payload의 길이
- 16비트이므로, 나올 수 있는 경우의 수는 이다.
- 여기서 헤더 길이 20을 빼서 대략 65515bytes 정도이다.
- 이론상 IP 패킷은 헤더를 포함하여 64KB가 가장 큰 숫자이다.
- 두번째 행은 모두 단편화(Fragment)와 관련이 있다.
- 예를 들어 패킷이 MTU가 1500인데, 어느 네트워크에 갔더니 MTU가 1300이어서 패킷을 잘라야할 때가 있다.
- 이렇게 잘라야할 때 단편화가 난다고 한다.
- TTL (time to live)
- 유통과정에서 TTL 값은 HOP이라는 단위를 지날 때마다 감소하는데, 0이 되면 이 패킷은 버려진다.
- 최대 크기는 이다.
- Protocal
- L3 Payload 안에 또 다른 Header가 올 수 있는데, 이 Header를 어떤 형태로 해석해야 되는지 프로토콜이 뭔지 설명이 된다.
- 프로토콜마다 고유 번호를 부여한 것이 있다. (TCP는 6)
- Header Checksum
- 네트워크로 패킷을 송수신하는 과정에서 손상이 일어났는지 검사하는 값이다.
- 출발지/목적지 주소
- 32bit
서브넷 마스크와 CIDR
Subnet Mask
- 서브넷 마스크를 기준으로 Network ID와 Host ID를 분리한다.
- 어떤 패킷이 온다면, 네트워크 장비나 이런 데서 서브넷 마스크와 IP주소를 bit단위로 AND 연산한다.
- Mask 연산이라고 한다.
- 네트워크 ID가 나와 일치한다면 우리 네트워크로 유입되는 것이라고 판단
- 서브넷 마스크를 라고 표기하면 앞에서부터 24비트를 Network ID라고 보는 것이다.
- 서브넷 마스크에서 1bit인 부분은 AND 연산 시, 자기 자신이 나온다.
- 즉, 255는 이므로 자기 자신이 통째로 나오는 것이다.
Class
- IP 주소에 Class 개념을 도입해서 등급을 매겼었다.
- IP 주소가 A.B.C.D라면,
- A만 Network ID로 사용한다면 A클래스
- B만 Network ID로 사용한다면 B클래스
- C만 Network ID로 사용한다면 C클래스
- 요즘은 Class라는 개념을 사실상 쓰지 않는다.
CIDR (Classless Inter-Domain Routing)
- 클래스 개념 없이, 즉 네트워크 구분을 Class로 하지 않는다.
- Class는 사이더가 나오기 전 사용했던 네트워크 구분 체계
- 사이더 표기법이라고 한다.
- 예를 들어, 라면 왼쪽부터 24개의 bit를 Network ID로 규정한다.
- 대신 슬래시로 표현
서브네팅
- 이미 잘려진 네트워크를 또 자르고 싶을 때 서브네팅이라고 한다.
- 서브넷 마스크할 때 Host ID 부분의 앞 부분의 비트가 올라간다.
- 예를 들어, 이고 서브넷 마스크가 이라면, 뒤의 2비트가 올라가서 가 된다.
- Host ID는 6bit가 되므로 나올 수 있는 수는 이 된다.
Broadcast IP 주소
- MAC 주소는 48bit 주소 체계를 갖는다.
- FF-FF-FF-FF-FF-FF
- IP에서 Host ID를 모두 1로 채우면 해당 네트워크에서 방송 주소로 쓰인다.
- 예를 들어, 라면 네트워크에서 방송 주소가 된다.
- MAC 주소도 FF-FF-FF-FF-FF-FF로 되어 있다.
- 만약 특정 주소를 찍어서 간다면 Unicast지만, Host ID를 1로 채워서 간다면 Broadcast이다.
- Multicast도 전체에 전달한다는 점에선 브로드캐스트와 유사하지만, 전달받은 애들을 따로 모아서 그룹핑하는 경우가 있다.
- IGMP를 다룬다?
- Multicast도 전체에 전달한다는 점에선 브로드캐스트와 유사하지만, 전달받은 애들을 따로 모아서 그룹핑하는 경우가 있다.
- 브로드캐스트를 자주하면 효율이 떨어진다.
- 네트워크 장비 전체에 부담이 늘어난다.
- 따라서 브로드캐스트 범위를 일정 범위 안에서 통제해야 한다.
- 브로드캐스트는 안 할 수 있으면 안 하는게 정답이다.
네트워크에서 쓸 수 없는 주소
- Host 부분이 0이면 서브넷 마스크와 일치하므로 사용할 수 없다.
- Host 부분이 255면 브로드캐스트가 되므로 사용할 수 없다.
- 따라서, Host 부분에서 실제로 사용할 수 있는 IP주소는 이다.
- 게이트웨이에 보통 1번을 많이 준다.
- 네트워크 장비 말고 순수하게 PC같은 애들이 쓸 수 있는 주소 개수는 250개 정도밖에 안된다.
Host 자신을 가리키는 IP 주소
127.0.0.1
- 인터넷을 사용하는 주체는 컴퓨터가 아니고, 컴퓨터에서 실행 중인 Process이다.
- 프로세스들이 내 프로세스들 간에 통신을 해야 할 때 (내가 나에게 접속) 쓸 수 있는 IP 주소가 이다.
- 이때, 1은 다른 걸 쓸 수도 있지만 보통 1을 쓴다.
- 이러한 주소를 Loopback Address라고 부른다.
- IP 주소를 특정하지 않고, 로 하면 내 컴퓨터 내의 프로세스 간 정보를 주고 받게 된다.
- 실제로 패킷은 IP 계층 밑으로 내려가지 않는다.
- 루프백 어드레스는 프로세스 간 통신을 할 때도 구현이 된다.
- IPC (Inter Process Communication)이라고 한다.
- 소켓을 이용해서 내가 나한테 접속하는 방식으로 프로세스 간 통신이 이루어지도록 지원할 때 흔히 사용된다.
💡 프로세스 간 통신(Inter-Process Communication, IPC)
프로세스들 사이에 서로 데이터를 주고받는 행위 또는 그에 대한 방법이나 경로
TTL과 단편화
Router VS L3 Switch
- 두 가지 의견이 있다.
- 라우터는 L3 스위치의 일종이므로 둘을 구분하는 것은 의미가 없다.
- L3 스위치가 라우터의 일종이다.
- 둘을 구분하는 것은 의미는 없다는 것이 강사님의 의견이다.
- 또한 개념적으로 L3 스위치에 포함되는 것으로 보는 게 타당하지 않을까?
TTL
- Time To Live(TTL)은 다음과 같은 역할을 한다.
- Packet을 전송할 때 목적지를 찾지 못하고 실패하는 경우가 있다.
- 이때 패킷이 네트워크에 좀비처럼 남아서, 좀비 패킷이 넘쳐나서 네트워크 전체가 다운되는 일이 없도록 빨리 버리고 폐기시켜야 한다.
- TTL의 값은 128인 경우도 있고 255인 경우도 있다.
- 라우터에서 어떤 라우터를 지날 때 단위를 Hop 단위라고 한다.
- Hop 단위로 지날 때마다(라우터를 지날 때마다) 값을 감소시킨다.
- 값이 0이 되면 목적지를 찾는데 실패했다고 보고 폐기한다.
- 라우터가 출발지에게 패킷이 폐기되었다고 알려주기도 하고, 보안 상의 이유로 알려주지 않기도 한다.
단편화
- 단편화는 MTU 크기 차이로 발생한다.
- 특별한 이유가 없다면 MTU는 1500bytes 정도 하는데, 다른 곳에서 MTU가 1400bytes라면 그에 맞춰서 패킷을 잘라줘야 한다.
- MTU 크기가 달라서 패킷의 크기를 잘라야 할 때 단편화라고 한다.
- 보통 단편의 조립은 수신측 Host에서 이루어진다.
예제
- 송신측 MTU는 1500인데 중간에 경로의 라우터 하나는 MTU가 1400이다.
- 그럼 해당 라우터로 갈 때 단편화가 발생한다.
- Payload를 둘로 나누고, 각각 IP 헤더를 붙여준다.
- 이 IP 헤더들은 flag나 offset 등 디테일한 값에서는 차이가 조금 있다.
- 이렇게 분리된 패킷들은 수신 측 End-point에서 조립한다.
- IP 프로토콜을 만나면 조립이 일어난다.
- 패킷을 조립한 후 Segment를 꺼낸다.
주의사항
- 단편화는 가급적 발생되지 않는 것이 좋다.
- 베스트는 처음부터 패킷을 보낼 때 1400으로 보내는 것이다. (하향평준화)
- 처음부터 단편화가 나지 않도록 낮춰서 보내는 것이 일반적이다.
- 가장 대표적으로 VPN이 적용되었을 때 MTU가 줄어드는 경우가 생긴다.
- 특히 IPSec VPN이 적용되면서 보안성은 올라가지만 단편화가 발생할 수 있다.
- 그 외에는 단편화가 날 가능성이 생각보다 높지 않다.
인터넷 설정 자동화를 위한 DHCP
인터넷 사용 전에 해야 할 설정
- IP 주소
- Subnet mask
- Gateway IP주소
- 여기까지는 L3에서 설정해야 하는 것이다.
- DNS 주소
- 도메인을 입력한다면 DNS 서버가 해당 도메인의 IP 주소가 무엇인지 알려준다.
ISP (Internet Service Provider)
- Host를 유니크하게 식별할 수 있는 식별자를 IP 주소라고 한다.
- 문제는 사용자는 IP주소의 값이 뭔지 구체적으로 알 수가 없다.
- 이러한 서비스를 제공해주는 회사를 ISP라고 한다.
- ISP쪽에서 IP주소들을 가지고 있다.
- 서비스를 돈 주고 구매하면 이 주소 중 하나를 쓸 수 있게 허락해준다.
자동 설정
- 보통 이러한 인터넷 설정들은 내가 직접하지 않고, 자동 설정해준다.
- 제어판 - 네트워크 설정으로 볼 수 있다.
- 자동으로 설정하겠다는 것은 DHCP를 활용하겠다는 것이다.
DHCP (Dynamic Host Configuration Protocol)
- DHCP 체계는 주소를 할당하는 서버와 할당 받으려는 클라이언트로 구성된다.
- 서버가 자동이라고 할 만한 모든 설정의 정보를 가지고 있다.
- 클라이언트가 접속하면 IP 주소를 포함한 설정(게이트웨이, 서브넷 등)을 모두 서버가 알려준다.
- 복잡한 인터넷 설정을 자동으로 해준다고 볼 수 있는데, 핵심은 내가 사용할 IP주소를 서버가 알려준다는 것에 있다.
- Dynamic은 IT쪽에서 Runtime과 동일한 말이다.
- 동적이다.
- 컴퓨터 작동 중에 되는 것
- Broadcast domain 안에 묶여 있어야 한다.
동작 과정
- PC의 전원이 켜지면 네트워크로 브로드캐스트 패킷이 나간다.
- DHCP 관련돼서 리퀘스트를 디스커버리라고 한다.
- 우리 네트워크 중에 DHCP 서버가 있는지를 묻는 디스커버리 트래픽이 나온다.
- 액세스 스위치에 도달하면 브로드캐스트하고 업링크해서 전달한다.
- 즉, 네트워크 전체에 퍼진다.
- DHCP Server가 response를 보낸다.
- 다른 컴퓨터들은 DHCP 서버가 아니므로 브로드캐스트 트래픽을 수신해도 아무런 응답을 보내지 않는다.
- 이전에 할당받은 주소가 있다면 DHCP Server에게 전에 받은 주소를 써도 되는지 묻는다.
- 써도 된다고 허락하거나 새로 주소를 내려준다.
ARP
ARP (Address Resolution Protocol)
- ARP는 IP주소로 MAC 주소를 알아내려 할 때 활용된다.
- ARP의 Address는 IP주소와 MAC 주소를 말한다.
- 보통의 경우 PC를 부팅하면 Gateway의 MAC 주소를 찾아내기 위해 ARP Request가 발생하며 이에 대응하는 Reply로 MAC 주소를 알 수 있다.
- 인터넷을 하기 위해서 Gateway의 MAC 주소를 반드시 알아야 한다.
예제
💡 PC의 IP 주소가 192.168.0.100이고 Gateway의 주소가 192.168.0.1이고 통신하고자하는 Naver 주소가 3.3.3.3이라고 가정하자.
- 인터넷으로 넘어오면 L3이므로 IP 주소가 중요하다.
- MAC 주소는 L2 구간에서만 중요하다.
- 다시 말해, 내가 Naver의 MAC 주소를 안다고 해도 그걸로 통신하지 않는다.
- PC가 인터넷에 접속하려고 한다면 Gateway MAC 주소를 반드시 알아야 한다.
- ARP 리퀘스트를 브로드캐스트로 보낸다.
- 처음 PC를 켰을 때 DHCP 서버에서 받은 Gateway 주소로, 이 주소를 사용하고 있는지를 확인
- Gateway는 해당 주소를 사용하고 있으므로 ARP reply를 보낸다.
- 이 때, MAC 주소를 같이 보낸다.
- PC는 Naver로 패킷을 보내는데, L2 Frame에서의 주소는 다음과 같다.
- 출발지: PC의 MAC 주소
- 목적지: Gateway의 MAC 주소
- 물론 L3의 IP 패킷의 출발지/목적지는 PC와 Naver의 IP 주소이다.
- Gateway는 IP 패킷의 헤더를 보고 목적지가 어딘지 판단한다.
ARP 캐시
- PC가 Gateway를 주소를 한 번 알아낸 후, 계속 다시 물을 이유는 없다.
- 따라서 캐시해서 메모리에 담고 있다.
- CMD에서
arp -a를 입력하면 arp 캐시가 나온다.- IP 주소 ~의 Gateway 주소는 무엇이다라는 정보가 출력됨
Ping과 RTT
Round Trip Time
왕복 시간(RTT)은 네트워크 요청이 시작점에서 목적지로 갔다가 다시 시작점으로 돌아오는 데 걸리는 시간(밀리초)이다.
참고: https://www.cloudflare.com/ko-kr/learning/cdn/glossary/round-trip-time-rtt/
Ping
- Ping 유틸리티(그냥 프로그램)는 특정 Host에 대한 RTT(Round Trip Time)을 측정할 목적으로 사용된다.
- Ping은 그냥 프로그램 이름이다.
- 보통 RTT로 네트워크의 회선 속도를 결정하고, RTT를 측정하는 가장 전형적인 프로그램이 Ping이다.
- ICMP 프로토콜을 이용한다.
- DoS(Denial of Service) 공격용으로 악용되기도 한다.
- 서버에 핑을 계속해서 보내는 등
- ping은 Echo Request로 일정 길이의 알파벳들을 보내고, Reponse로 똑같은 문자열이 돌아온다.
예제
만약, 철수와 영희와 길동이 같이 게임을 하고 있다. 이때, 각자의 Ping 속도가 다음과 같다.
- 철수: 20ms
- 영희: 25ms
- 길동: 50ms
그러면 길동이는 속도가 느리므로 화면이 서로 달리 보이게 된다.
이런 경우 “라운드 트립 타임이 시간이 오래 걸린다”, “라운드 트립에 문제가 있는 것 같다”고 표현한다.
💡 이때, 하향평준화를 시킬 것인지 화면 동기화를 어떻게 할 것인지 기술적인 노하우가 필요하다.
이러한 노하우는 어느 정도 공개가 되어있다.
활용
- 인터넷 연결이 안 될 때 Gateway에 Ping을 보내본다.
- 답이 없으면 Gateway가 다운되었다는 의미가 된다.
- 이때 몇 ms가 소요되었는지 나오는데, 이게 RTT가 된다.
- Gateway는 거의 LAN 수준, 즉 로컬 네트워크에 가깝기 때문에 매우 빠르다. (1ms 이내에도 응답이 온다.)
- 물리적 거리가 멀다 해도 네트워크 회선 속도가 훨씬 빠르다면 응답은 빠를 것이다.
- RTT는 거리에 비례하는 것이 아니고 네트워크 속도가 중요한 것이다.
- 물론 거리가 멀어지면 속도가 떨어질 가능성은 높다.
Reference
