grep
특정 패턴 찾아서 출력
사용법
grep [option] pattern file옵션
-b : 일치하는 패턴이 있는 줄의 시작점을 출력
-c : 일치하는 패턴이 있는 줄의 개수 출력
-h : 여러 개의 파일 검색 시 출력하는 파일 이름이 붙는 것을 방지함
-i : 검색할 때 대소문자 구분 X
-n : 일치하는 패턴 있는 줄의 번호, 내용 같이 출력
-v : 일치하는 패턴 없는 줄 출력
-w : 패턴과 한 단어로 일치해야 출력
-x : 패턴과 한 줄로 일치해야 출력
-l : 주어진 패턴과 일치하는 패턴이 있는 파일 이름만 출력
-r : 하위 디렉터리까지 주어진 패턴 찾기
-o : 지정한 패턴과 매칭되는 것만 출력
-E : 이 옵션은 | 와 연계하여 여러 패턴을 찾음
-F : 지정한 문자들을 기호 그대로 인식하여 출력
--color-auto : 검색하는 패턴과 매칭되는 문자열을 색깔로 표시하여 강조
grep -c linux *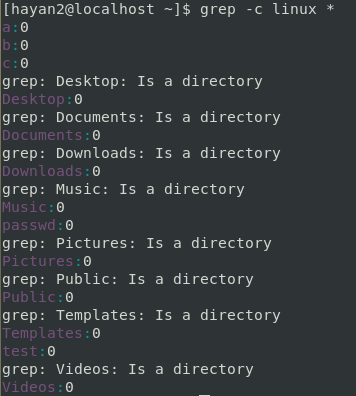
없으니까 출력을 안해준다...
만들어보자
cat > grepTest
...
linuxmaster
linux is good->
grep -c linux *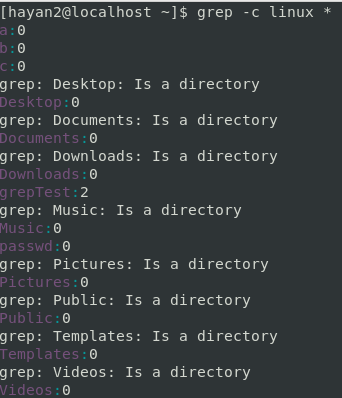
grepTest 파일에 패턴과 일치한 줄이 두 줄 있다고 나온다
grep -h linux *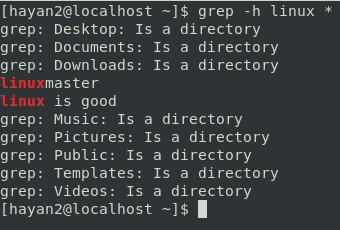
wc
사용법
wc [option] file옵션
-l : 행 수만 출력
-w : 단어 수만 출력
-c : 문자수만 출력
-L : 가장 긴 라인 길이 출력
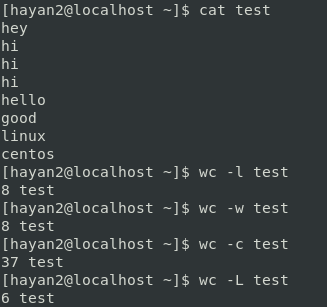
예상대로 나옴
sort
텍스트 파일 행 단위로 정렬. 기본 정렬 순서는 오름차순
사용법
sort [option] file옵션
-b : 라인 앞 부분 공백 문자 무시 (공백라인 제외)
-d : 공백과 알파벳, 숫자만으로 정렬 (왜 한글은 뺌?)
-f : 대소문자 무시
-r : 정렬 순서 내림차순으로
-o : 정렬 결과를 파일로 저장
-c : 파일이 정렬되어 있는지 검사. 정렬되어 있으면 아무것도 출력하지 않고 정렬되지 않았으면 정렬되지 않았다는 메시지를 출력
-n : 숫자를 문자가 아닌 숫자값으로 취급해서 수의 크기대로 정렬
-u : 중복되는 줄은 한 줄만 출력
-M : 월 표시 문자로 정렬할 때 사용
-t : 필드 구분자 지정할 때 사용
-k n[,m] : 정렬할 위치를 지정하는 옵션. n번째 필드를 기준으로 정렬. m이 지정되어 있으면 n필드에서 시작해서 m필드에서 끝남. 필드 내에서 위치 지정할 때는 .을 사용
sort -t : -n -k 3 passwd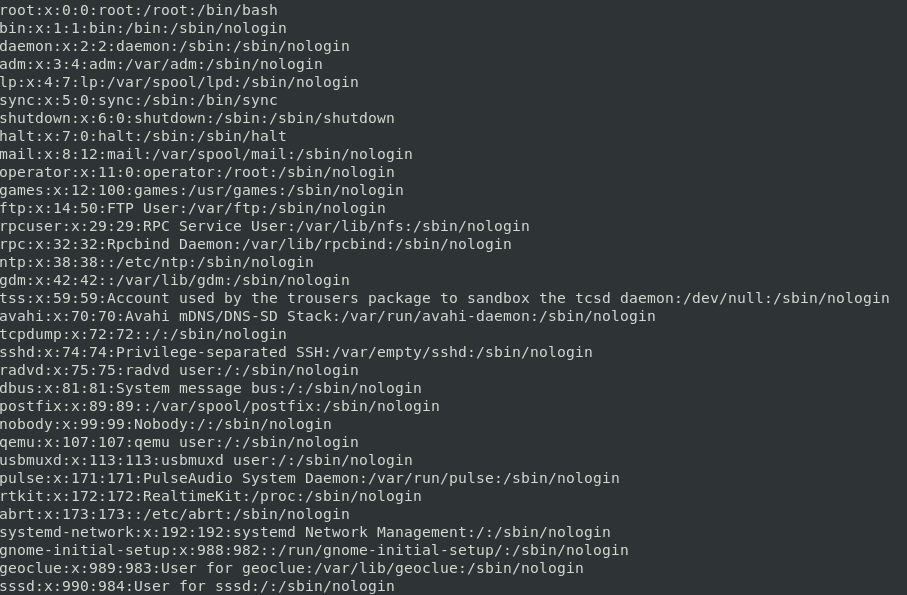
콜론(:) 을 기준으로 3 번째 필드의 값으로 정렬함
그리고 -n 옵션을 줌으로써 숫자값으로 취급하여 정렬했음
-n 옵션이 없을 땐 bin:x:1 어쩌구 값 다음에 operator:x:11 어쩌구가 왔어야 하지만 숫자값으로 취급하여 정렬했기 때문에 daemon:x:2 어쩌구가 왔다. 1 다음은 2니까..
cut
텍스트 파일의 데이터 열(column)을 추출할 때 사용
추출하는 데이터는 각 줄의 글자, 바이트, 필드가 됨
사용법
cut [option] file옵션
-c : 문자 수를 기준으로 추출
-f : 파일의 필드를 기준으로 추출
-d : 필드 구분자를 지정 (기본은 tab)
cut -c 1-10 passwd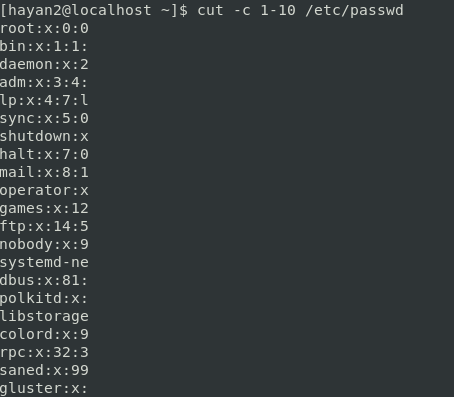
split
하나의 파일을 여러 개의 작은 파일로 분리하는 명령어
기본값은 1000줄 단위이며 별도의 파일명을 지정하지 않으면 얘가 지 멋대로 xaa, xab, xac .. 등으로 표기함
사용법
split [option] file [filename]옵션
-a 값 : 뒷 자리 길이 지정
-b 값 : 파일을 주이전 값의 바이트 크기로 분리. 단위로 K, M 등 붙여서 사용 가능
-C 값 : 분할되는 줄의 최대 크기를 지정
-d : x 뒤의 문자를 숫자로 지정. 숫자 값은 0부터 시작하며 2자리로 표시
-l 값 : 파일을 주어진 크기의 줄 크기로 분리.
분할된 파일 복원하기
split -b 100K /etc/services srv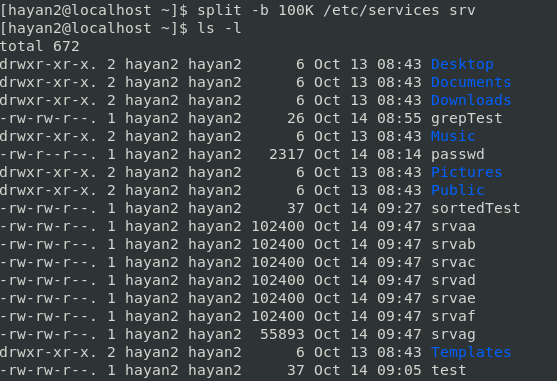
분할된 파일들을 cat 명령으로 하나로 만들면 됨
cat srv* > servicestr
텍스트 파일 안에 있는 문자열을 원하는 문자로 바꾸거나 제거함
리다이렉션 기호를 꼭 써야함
사용법
tr [option] word1 word2 < filename옵션
-d : 주어진 문자 삭제
-s : 문자가 중복된 경우 하나만 남기고 모두 삭제
