Numpy
행렬, 대규모 다차원 배열 쉽게 처리할 수 있도록 지원하는 파이썬 라이브러리
import Numpy as npnp로 바꿔서 많이 쓴다
Scalar
방향x 크기만 있는 값
a = np.array([0])
aVector
n차원 공간에서 방향과 크기를 갖는 단위
정형데이터에서 어떤 샘플의 데이터를 '특성벡터' 라고도 한다.
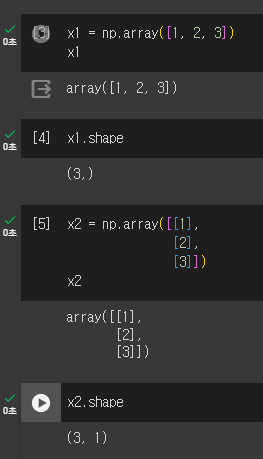
numpy는 1차원 배열객체도 벡터로 인정하지만 x2처럼 열벡터(column vector)로 나타낸 2차원 배열 객체로 표현한 방식이 올바른 표기법이다.
Matrix
선형대수학에서는 열 벡터를 모아 놓은 것으로 말한다.
M x N 행렬은 MxN개의 원소를 갖는다.

Function
자주 사용되는 기능들 정리
np.shape
행렬의 차원을 확인할 수 있는 메소드이며,
np.shape(행렬) 뿐만아니라 행렬.shape 방식으로도 사용 가능
np.reshape
행렬의 차원을 변경하는 메소드로, 변경 이전 차원의 곱과 변경 이후 차원의 곱이 같다면 변환 가능
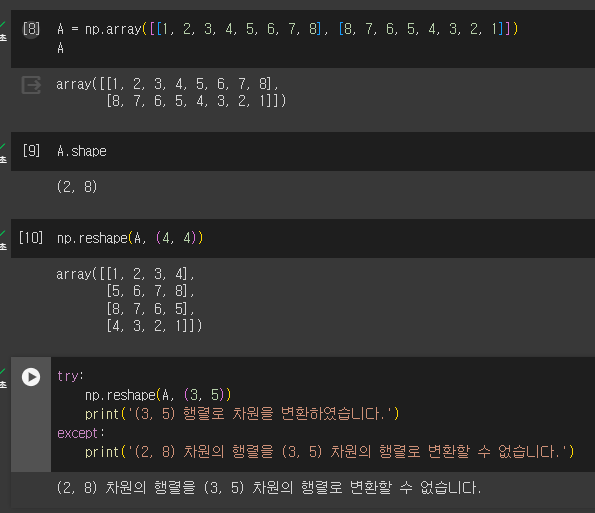
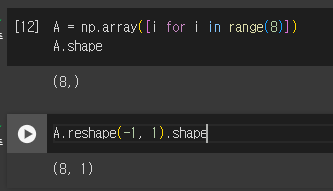
마지막 A.reshape(-1, 1).shape 에서 -1은 n개의 차원 중 n-1개는 사용자가 지정하고 나머지는 알아서 가능한 차원에 맞추라는 의미
해당 예제의 경우 2개의 차원 중 마지막 차원에 1을 할당했으므로 -1에는 8이 들어가 (8, 1) 차원 행렬이 된다.
np.concatenate()
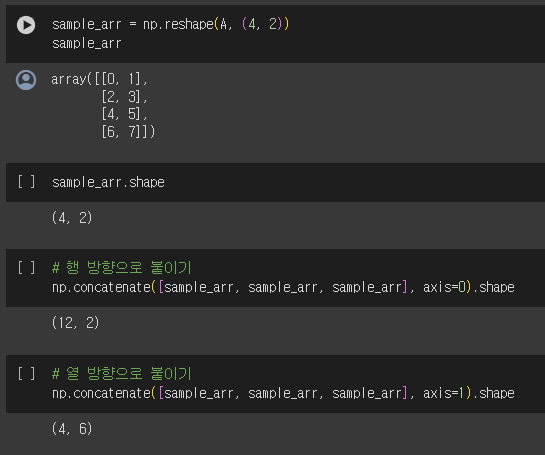
여러개의 numpy 행렬을 특정 방향으로 이어 붙이고 싶을 때 사용
차원 확인한 후 차원을 지정해서 이어붙이면 된다.
여기서 axis = ? 는 ?에 해당하는 인덱스를 축으로 붙이겠다는 의미. 비정형 데이터를 다루다 보면 고차원 데이터를 다룰 때가 있는데 단순히 0 = 행, 1 = 열로 외우면 틀릴 수 있다.
np.sum()
파이썬에도 내장함수가 있지만 numpy 메소드들은 axis 인자를 할당해서 특정 축을 기준으로 연산이 가능하다는 특징이 있다.
A = np.array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
_A = np.array[[[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]],
[[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]]]) np.sum(행렬, 축) 은 주어진 행렬과 축 방향에 대해 합계를 계산해 반환하는 함수

np.mean()
np.sum(행렬, 축)은 주어진 행렬과 축 방향에 대해 평균을 계산해서 반환하는 함수

np.var()
np.var(행렬, 축) 은 주어진 행렬과 축 방향에 대해 분산을 계산해 반환하는 함수

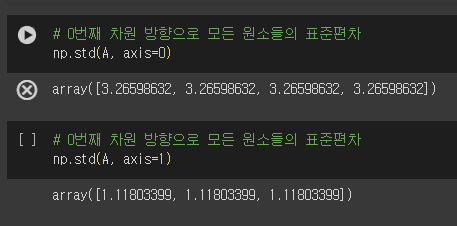
np.std()
np.std(행렬, 축) 은 주어진 행렬과 축 방향에 대해 표준편차를 계산해 반환하는 함수
np.max()
np.max(행렬, 축) 은 주어진 행렬과 축 방향에 대해 최대값을 반환하는 함수

np.min()
np.min(행렬, 축) 은 주어진 행렬과 축 방향에 대해 최소값을 반환하는 함수

np.unique()
np.unique(행렬) 은 주어진 행렬에 대해 중복을 제거하여 모든 원소 값을 반환하는 함수

np.log(), np.exp()
값에 자연 로그를 취하거나 자연 상수의 지수곱을 수행하는 함수
일반적으로 데이터가 치우친(Skew) 분포를 가지고 있을 경우 로그 변환을 수행하게 되는데, np.log는 이 때 사용하는 메소드
자연 로그의 역함수로 사용되는 메소드로 np.exp가 있다.

Pandas
판다스(Pandas)는 데이터 조작 및 분석을 위해 사용하는 라이브러리입니다.
특히, 숫자 테이블 및 시계열 데이터를 위한 데이터 구조 및 함수를 제공합니다.
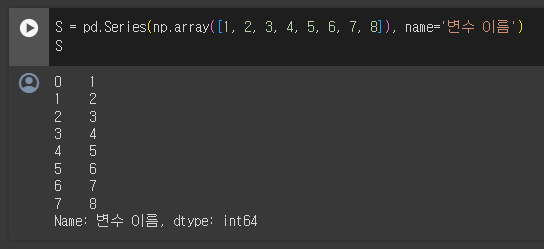
Series
시리즈(Series)는 Pandas의 대표적인 데이터 객체 표현으로 라벨(컬럼 이름)을 가진 1차원 배열입니다.
간단하게 하나의 열(Column)을 생각하시면 됩니다.
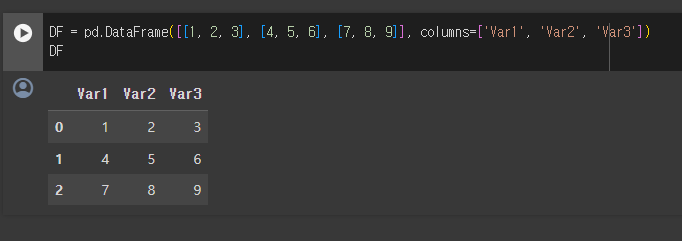
DataFrame
데이터 프레임(DataFrame)는 Pandas의 대표적인 데이터 객체 표현으로 라벨(컬럼 이름)을 가진 2차원 배열입니다.
간단하게 엑셀 데이터를 생각하시면 됩니다.
Functions
자주 사용되는 Pandas 기능 정리
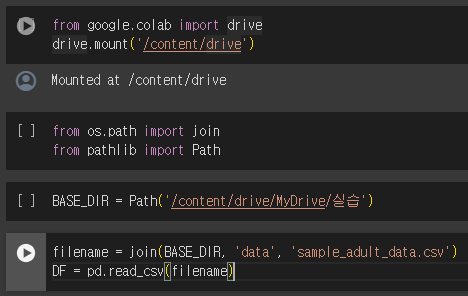
pd.read_csv()
pd.read_csv(파일명) 메소드는 csv(comma-separated variables) 파일로 이루어진 데이터를 DataFrame으로 읽어오는 기능을 수행합니다.
주로 정형 데이터를 읽어올 때 사용됩니다.
pd.set_option
 보통 .head() 를 치면 보이는 컬럼수가 제한되어 있는데 이 기능을 사용하면 뒤의 숫자만큼 최대한도를 늘려서 전부 보여줘서, 눈으로 전체를 확인하기 좋다.
보통 .head() 를 치면 보이는 컬럼수가 제한되어 있는데 이 기능을 사용하면 뒤의 숫자만큼 최대한도를 늘려서 전부 보여줘서, 눈으로 전체를 확인하기 좋다.
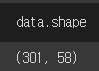
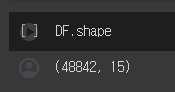
DataFrame.shape
Numpy의 np.shape 처럼 동일하게 차원을 확인할 수 있는 속성입니다.
차원을 변경할 수 있는 reshape 함수는 따로 존재하지 않기 때문에
차원을 변경하고자 할 때는 Numpy 행렬로 변경한 후에 np.reshape 메소드를 사용하여 변경합니다.
Pandas의 DataFrame의 행과 열의 수를 확인할 수 있는 메소드입니다.
DataFrame.head()
DataFrame.head(개수) 는 Series나 DataFrame 객체가 가진 값의 일부분을 반환하는 메소드 입니다.
기본 값으로 5개를 반환하며, 전달한 인자의 숫자에 따라 개수를 조절할 수 있습니다.
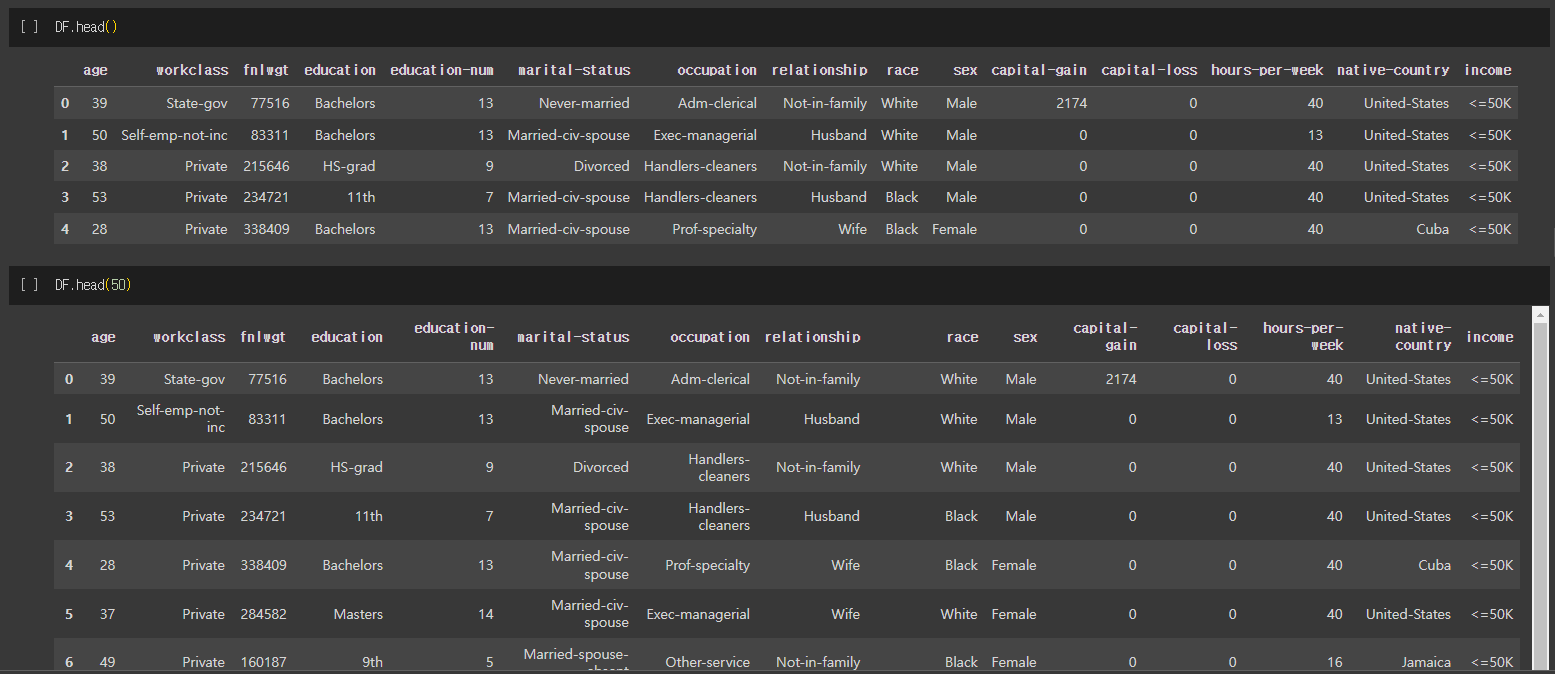
DF.head(50)은 너무 길어서 짤렸음
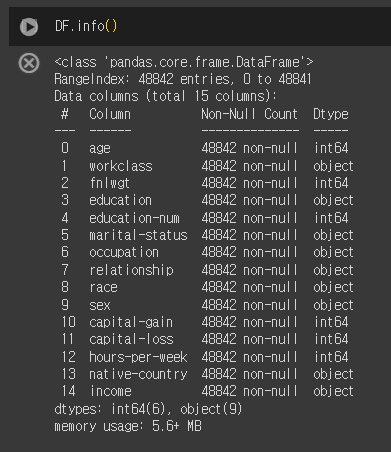
DataFrame.info()
DataFrame.info() 는 Series나 DataFrame 객체가 가진 변수들의 정보를 보여줍니다.
일반적으로 변수들의 자료형(수치형 or 범주형)을 확인하기 위해 사용하기도 합니다.
DataFrame.describe()
DataFrame.describe() 는 Series나 DataFrame 객체가 가진 변수들의 기초 통계량 값을 출력합니다.
수치형 변수의 경우 최대, 최소, 중간, 평균, 표준편차 등을 출력하며, 범주형 변수의 경우 범주의 수, 최빈값, 최빈값의 빈도수 등을 확인할 수 있습니다.
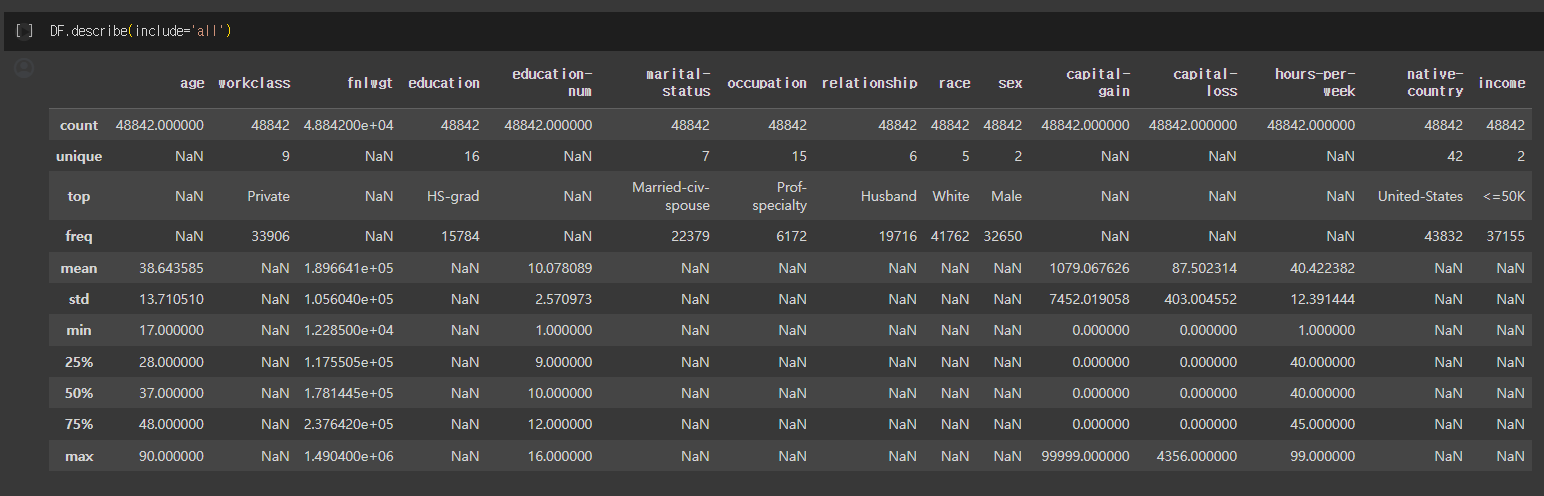
DataFrame.values
DataFrame.values 속성은 Series나 DataFrame에서 값을 Numpy 배열(ndarray)로 반환해줍니다.
주로 대용량 데이터 처리 시 Pandas 자체 연산보다는 Numpy 배열 연산이 빠르기 때문에 Numpy 배열로 변환 후 연산할 때 사용합니다.
Pandas.concat()
Pandas.concat() 함수를 사용해 지정한 축으로 Pandas 객체를 연결할 수 있습니다.
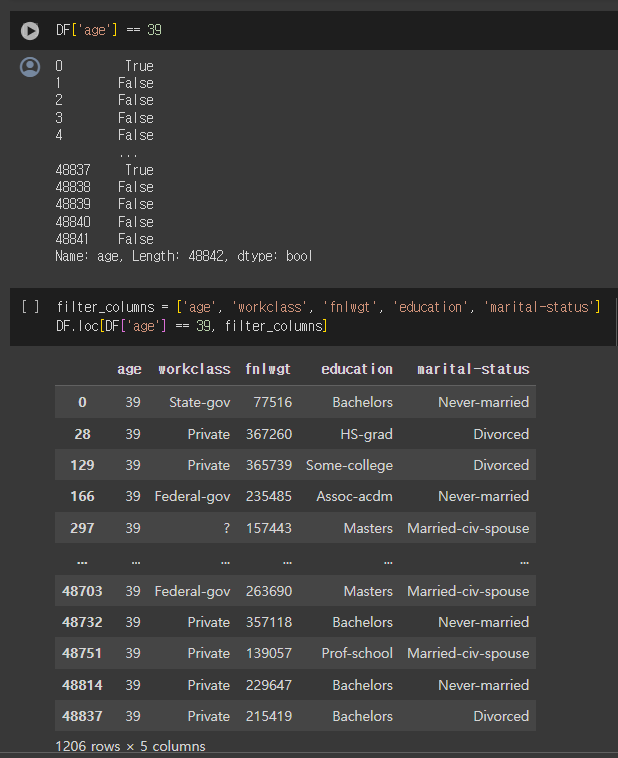
DataFrame.loc / DataFrame.iloc
DataFrame을 제대로 사용하기 위해서는 필수로 익혀야하는 메소드 2가지 입니다.
간단하게 생각하면, 특정 조건에 맞는 행과 열을 추출한다고 말할 수 있습니다.
iloc 메소드 보다는 loc 메소드가 더 자주 사용됩니다.
DataFrame.loc[행 조건, 열 조건 또는 열 리스트]으로 해당 조건에 맞는 행과 열을 찾아냅니다.
예를 들어 age 컬럼의 값이 39인 행과 'age, workclass, fnlwgt, education, marital-status' 열로 구성된 데이터만을 추출하고 싶은 경우
DF.loc[DF['age'] == 39, ['age', 'workclass', 'fnlwgt', 'education', 'marital-status']]와 같이 작성할 수 있습니다.
DataFrame.iloc[행 인덱스, 열 인덱스]로 인덱스에 맞는 행과 열을 찾아냅니다
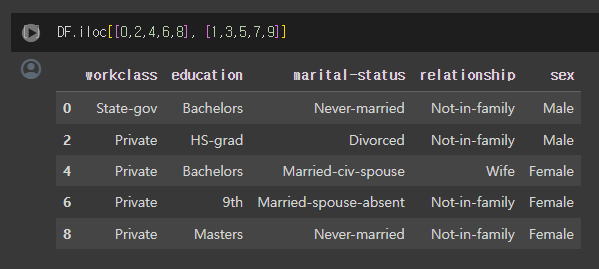
Series.map()
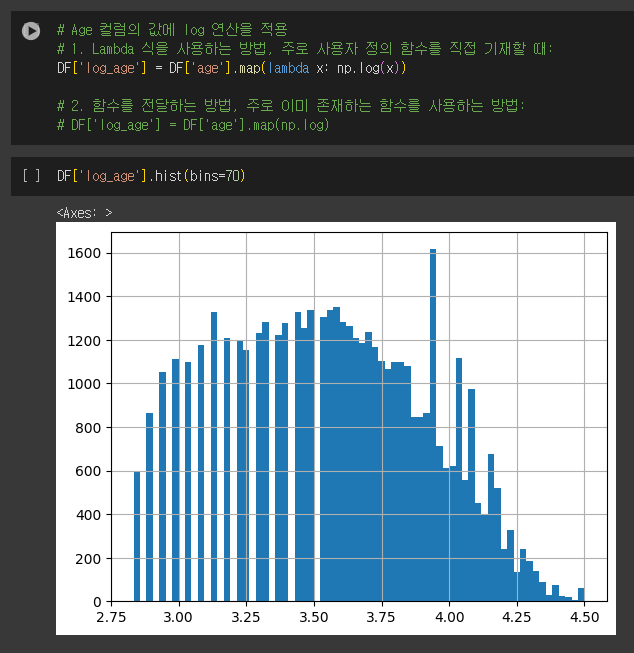
map 함수는 Pandas Series(column)에 사용할 수 있는 함수로 Series의 각 원소에 연산을 적용 할 수 있습니다. 각 원소를 입력으로 받아 단일 값을 반환합니다.
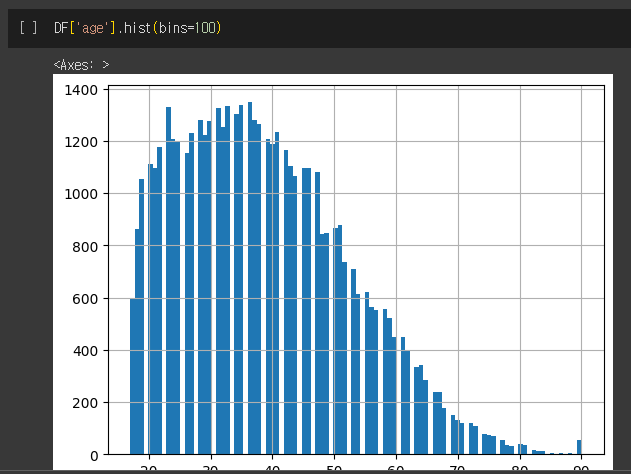
예를들어 나이 컬럼인 'age' 컬럼에 log 연산을 적용하고 싶은 경우 다음과 같이 할 수 있습니다.
분포 확인
DataFrame.apply()
apply, applymap 함수는 Pandas DataFrame에 사용할 수 있는 함수로
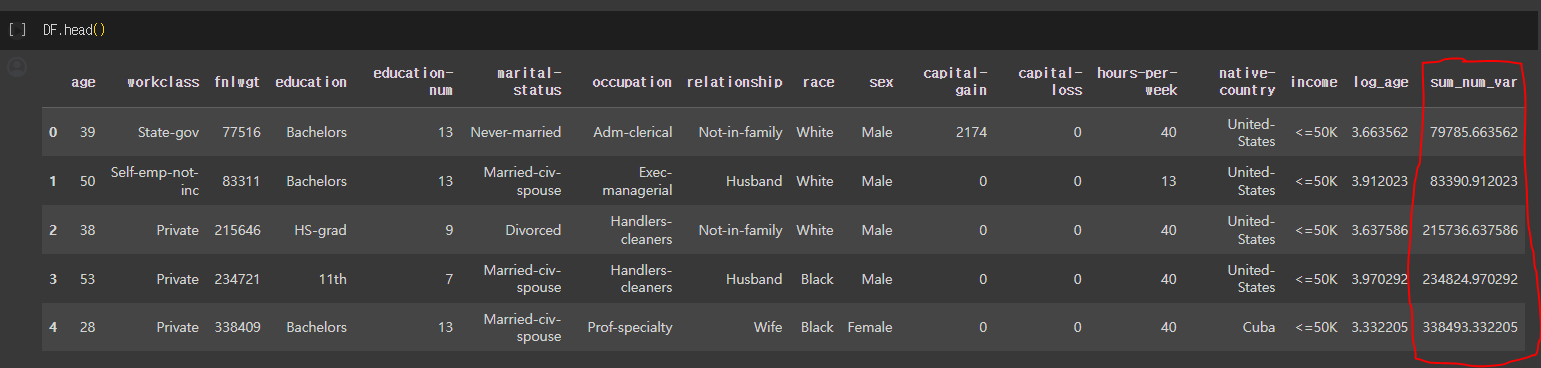
apply는 행 또는 열 같은 축에 대해 연산을 적용 할 수 있습니다. 행 또는 열을 입력으로 받아 단일 값을 반환합니다.
예를들어 행에 존재하는 모든 수치형 열의 값을 더해서 새로운 열을 만들고자 한다면 다음과 같이 할 수 있습니다.

DataFrame.applymap()
Pandas DataFrame에 사용할 수 있는 함수로 applymap은 Series의 map과 동일하게 각 원소에 연산을 적용할 수 있습니다. 각 원소를 입력으로 받아 단일 값을 반환합니다.
예를들어 모든 수치형 값에 log를 취한다면 다음과 같이 할 수 있습니다.
DF.applymap(lambda x: np.log1p(x) if isinstance(x, (int, float)) else x)결과
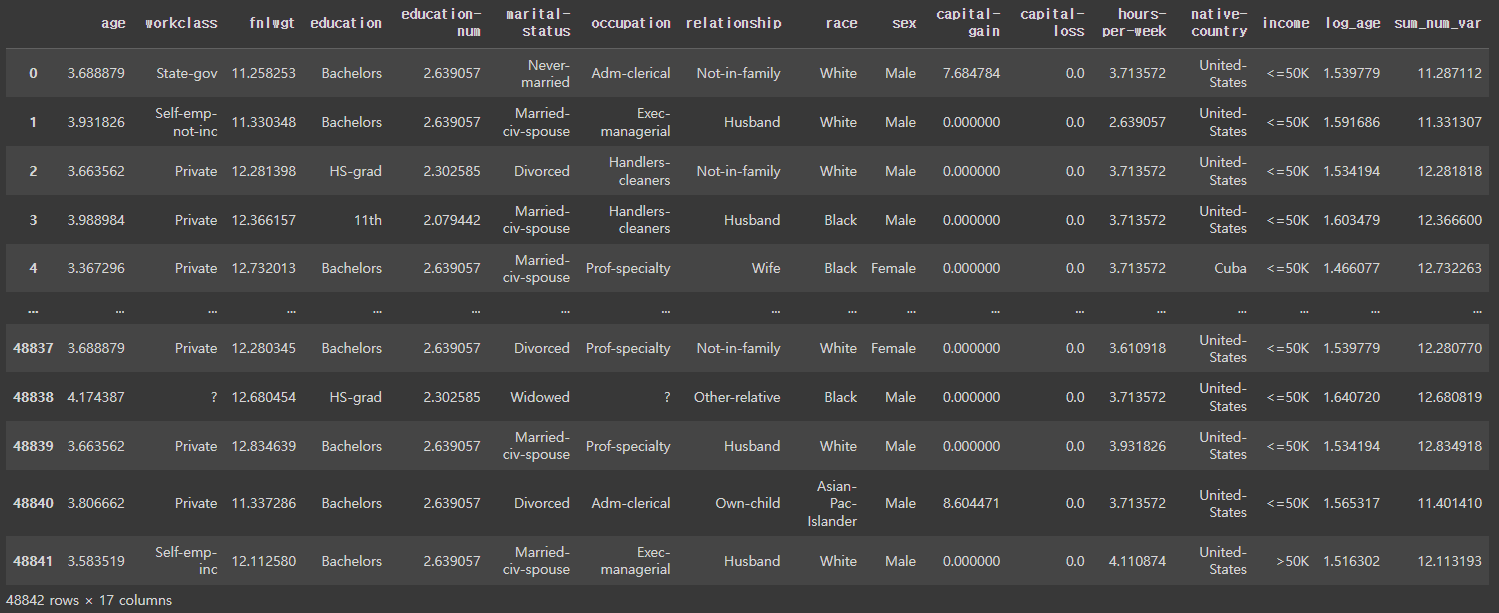
inplace 인자
몇몇 Pandas 함수들의 인자를 살펴보면 inplace 인자가 있습니다.
inplace란 말 그대로 내부에서 연산을 하고 객체를 반환하지않는 것을 의미합니다.
일반적으로 Pandas 함수들은 연산 후 연산이 적용된 새로운 객체를 생성해서 반환하는데, inplace 인자를 True로 전달하면 객체를 반환하지 않습니다.
inplace = False 로 하면 원본데이터 수정 x . 보통 default로 되어있다.
테스트해볼 때 좋음
inplace = True 로 하면 원본데이터 수정됨. 어차피 원본데이터를 함수 적용시킨걸로 바꿔야한다면 작업 2번해야하기 때문에 귀찮을 때 한번에 하려고 True 사용.
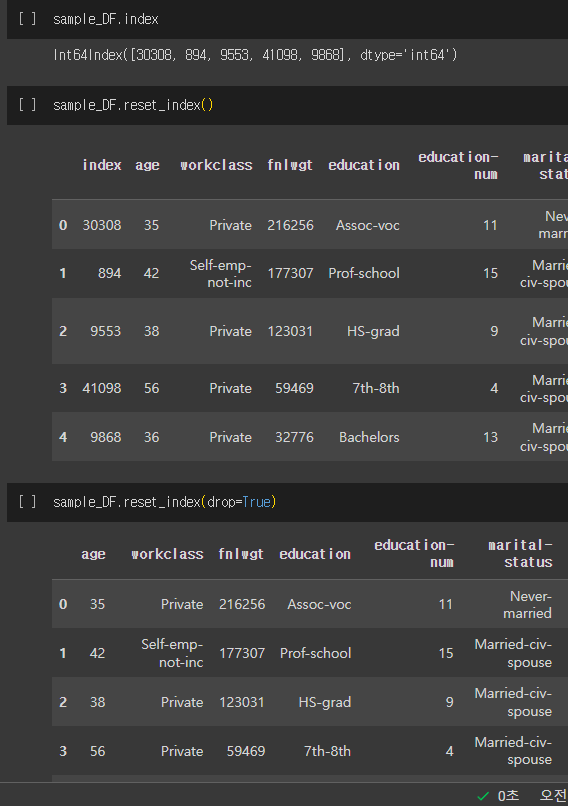 그냥 reset_index() 하면 기존 index들이 표시되는데 이게 싫을 때
drop = True 를 넣으면 기존 index 부분을 삭제시켜서 반환해준다.
그냥 reset_index() 하면 기존 index들이 표시되는데 이게 싫을 때
drop = True 를 넣으면 기존 index 부분을 삭제시켜서 반환해준다.
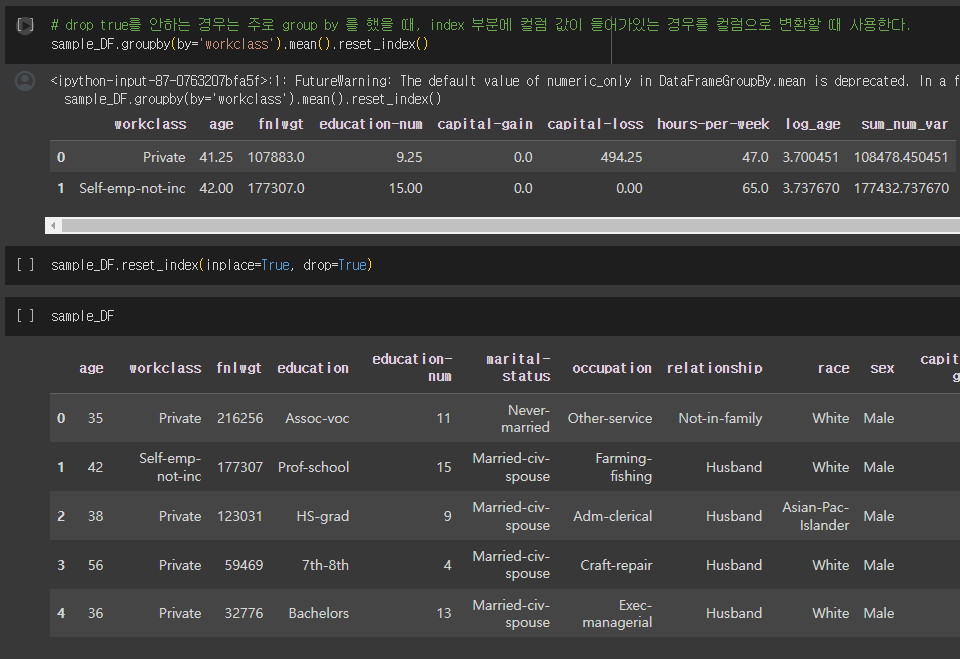
groupby하면 원래 workclass 부분이 좌측 인덱스 쪽으로 빠져버리는데 이걸 컬럼으로 올려서 사용하고 싶을 때 drop=True 없이 reset_index()를 사용하면 된다.
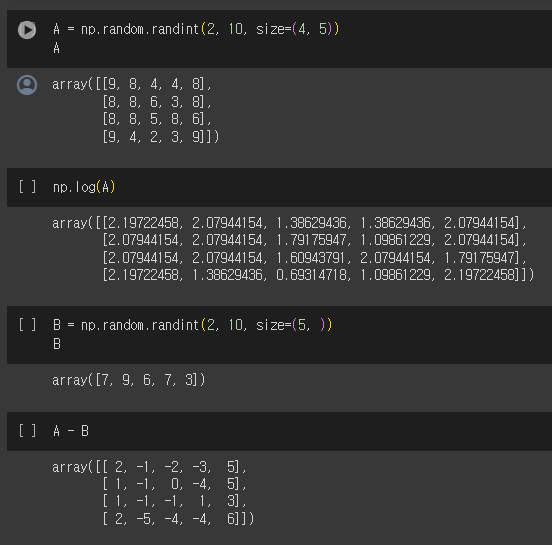
Numpy와 Pandas의 브로드캐스팅
브로드캐스팅이란? Numpy와 Pandas 자료형에 대해 대부분 단항 또는 이항 연산들은 브로드캐스팅을 지원하는데, 차원에 맞게 연산이 알아서 적용되는 것을 말합니다.
- (4, 4) 짜리 행렬 A에 단항 연산인 다음과 같이 로그를 씌우면 np.log(A), 알아서 A의 각 원소에 로그가 적용됩니다.
- (4, 4) 짜리 행렬 A에 (4, 1) 행렬 B를 다음과 같이 빼면 행렬 A의 행 방향으로 B 만큼 값이 감소하게 됩니다.
추천 이론 강의
-
Edwith 인공지능을 위한 선형 대수, 주재걸 교수님: https://www.edwith.org/ai251
-
k-mooc R을 활용한 통계학개론, 김충락 교수님:
http://wwwdev.kmooc.kr/courses/course-v1:PNUk+RS_C01+2017_KM_009/about
