RDBMS
관계형 데이터베이스 관리 시스템(Relational Database Management System)
일반적으로 지칭하는 데이터베이스
각 테이블은 테이블 간의 관계로 정의된다.
트랜잭션
데이터베이스의 상태를 변경하는 작업의 논리적 단위.
여러개의 SQL 쿼리가 하나의 트랜잭션으로 묶여 실행되며, 트랜잭션 내에서 실행된 작업은 모두 성공하거나 모두 실패해야한다.
ex) 은행 계좌 이체
A가 B에게 10만원을 송금하는 경우를 예시로 들어 설명합니다.
시작: A의 계좌에서 10만원을 출금하는 트랜잭션이 시작됩니다.
실행:
A의 계좌에서 10만원을 차감하는 SQL 쿼리가 실행됩니다.
B의 계좌에 10만원을 입금하는 SQL 쿼리가 실행됩니다.
종료: 두 쿼리가 모두 성공적으로 실행되면 트랜잭션이 커밋되고,
10만원이 A의 계좌에서 B의 계좌로 이체됩니다. 만약 쿼리 중 하나라도 실패하면
트랜잭션이 롤백되고 이체는 진행되지 않습니다.일반적으로 CRUD 중 CUD연산을 사용할 때 트랜잭션이 필요하다.
(CRUD : Create, Read, Update, Delete)
트랜잭션의 ACID
-
원자성(Atomicity)
트랜잭션의 모든 작업이 성공하거나 모두 실패해야한다. 부분완료는 Xex) 온라인 쇼핑몰 구매 트랜잭션 이 트랜잭션은 주문정보생성, 재고수량감소, 결제 처리 등의 여러 작업이 있다. 원자성에 따르면 이러한 모든 작업은 하나의 단위로 실행되어야 한다. 만약 주문정보는 생성 되었지만 재고 수량 감소 또는 결제 처리가 실패하는 경우가 생기면 안된다.
- 일관성(Consistency)
트랜잭션이 실행 된 후에도 데이터베이스는 일관된 상태를 유지해야한다. 트랜잭션 완료 후에도 데이터베이스 무결성 규칙(데이터가 정확하고 일괄된상태)을 준수해야함.
무결성 규칙 ex) primary key 에서는 not null(null이 존재해선 안된다.). 중복x
ex) 은행 계좌 송금 트랜잭션
이 트랜잭션은 입금, 출금 두 가지 작업이 있다고 해보자.
일관성 특성에 따르면 이러한 두 가지 작업이 성공적으로 완료되면
출금 계좌의 잔액은 송금 금액만큼 감소하고 입금계좌의 잔액은 송금 금액만큼 증가해야 한다.-
고립성(Isolation)
여러 트랜잭션이 동시에 실행될 때, 각 트랜잭션은 다른 트랜잭션의 영향을 받지 않고 독립적으로 실행되는 것 처럼 보여야한다.ex) 두 명의 사용자가 온라인 쇼핑몰에서 동일한 상품을 구매하는 경우 고립성 특성에 따르면 한 사용자가 상품을 구매하는 동안에는 다른 사용자가 동일한 상품을 구매하려는 경우, 두 트랜잭션은 서로 영향을 주고받지 않아야 한다. 즉, 한 사용자가 상품을 구매하면서 다른 사용자가 상품을 구매할 수 없는 상황이 발생해서는 안된다. -
지속성(Durability)
트랜잭션이 성공적으로 완료된 후에는 그 결과가 영구적으로 저장되어야한다. 시스템이 고장나더라도 결과가 유지되어야 한다.ex) 시스템 장애로 인해 데이터베이스가 손상된 경우 지속성 특성에 따르면 트랜잭션이 성공적으로 완료되기 전에 데이터 손실이 발생하더라도 트랜잭션 결과는 영구적으로 저장되어야한다. 시스템 장애를 복구한 후에도 트랜잭션 결과는 유지되어야 한다.🚩Write Ahead Log 개념 공부해보기
트랜잭션 고립 레벨
여러 트랜잭션이 동시에 실행 될 때 각 트랜잭션이 다른 트랜잭션 작업을 어느정도까지 볼 수 있는지 결정하는 것.
설명할 수 있도록 외우자.
-
READ UNCOMMITTED
가장 낮은 고립성. 하나의 트랜잭션이 커밋되지 않은 다른 트랜잭션의 변경점을 볼 수 있다. 다른 트랜잭션이 수행중인 데이터에 대한 dirty read가 발생할 수 있음.
대부분의 디폴트 값임(잘 안쓴다)
dirty read : 나는 커밋을 안찍었는데 다른 트랜잭션에서 커밋 한 값을 내가 읽어버리는 문제
-
READ COMMITTED
다른 트랜잭션이 이미 커밋한 데이터만 읽을 수 있다. 데이터 변경 xUndo Area : 데이터베이스에서 과거값(원본)을 저장해 놓는 영역. 다른 트랜잭션에서 값이 바뀌어도 커밋 전에는 이 영역의 값을 읽어서 dirty read를 막는다. 단, 다른쪽에서 바뀐값으로 커밋이 되어버리면 Undo Area 사라지고 똑같이 다른값을 읽어버림
-> Non Repetable ReadNon Repeatable Read : A 트랜잭션에서 커밋한 값을 B는 아직 커밋 전인데도 불구하고 A에서 커밋을 해버렸기 때문에 이 변경된 값으로 읽어버림. 순간적으로 값이 이상해지는 것. 이정도는 감안하고 로직을 짜야한다. 두 번 읽는 일이 없도록 짜야한다.
Phantom Read : insert를 해서 갑자기 보이는 것
-
REPEATABLE READ
다른 트랜잭션에서 커밋을 찍더라도 Undo Area에 있는 값을 읽게 해준다. (낮은 트랜잭션 일 경우) -> 아래 링크에 자세히 설명되어있음
-
SERIALIZABLE
순차적으로 실행되는것 처럼 보임. 다른 트랜잭션의 영향 xex) A가 송금하는 동안 B가 송금하면, 두 송금은 순차적으로 처리된다.
고립레벨이 올라갈수록 메모리가 많이 들어서 느려진다.
나중에 공부) Exclusive Lock, Phantom Read
참고(그림 설명 좋음) : https://tlatmsrud.tistory.com/118
데이터 이상 현상
데이터 테이블을 잘못 설계하면 데이터 이상현상이 발생 할 수 있다.
- 삽입이상(Insertion Anomaly)
새로운 데이터 삽입할 때 발생하는 문제
ex) 특정 테이블 일부 속성이 not null해야 하는데 새로운 행 삽입할 때 필수 속성을 제공하지 않으면 삽입 실패할 수 있음
- 갱신이상(Update Anomly)
데이터 업데이트할 때 발생하는 문제
ex) 특정 테이블에 중복 데이터가 있는 경우 이 중 하나를 업데이트 하면 다른 데이터와의 불일치가 생김
- 삭제이상(Deletion Anomaly)
테이서 삭제할 때 발생하는 문제
ex) 특정 테이블에서 필요한 데이터와 관련된 다른 데이터가 있는 경우, 이 데이터를 삭제하면 관련된 다른 데이터도 같이 손실되어버림
정규화
하나의 테이블을 여러 개로 분할하여 중복을 제거하고 데이터 일관성을 유지하게 해준다.
일반적으로 3단계까지 적용한다. 각 정규화 단계는 하위 단계를 만족해야함.
-
제 1정규형
테이블 내의 속성 값은 '원자 값'으로 이루어져 있어야한다.ex) 컬럼별로 하나의 값만 가져야한다. {학생, 대한민국} 처럼 2개의 속성 존재하면 안된다. 이 때 중복된 필드를 여러 개의 행으로 분리해주면 제 1정규형을 만족하는 것이다. -
제 2정규형
PK에 대해 부분 종속이 존재하면 안된다.ex) 과목-학생 테이블이 있고 해당 테이블의 PK는 {과목명, 학생}이라 해보자 과목-학생 테이블의 컬럼이 {과목명, 학생, 담당선생님, 교실} 일 때 특정 과목에 대해 선생님이 한명이라면 PK의 부분인 과목명에 담당 선생님 컬럼이 부분 종속을 갖게된다. 이 때 과목 테이블을 별도로 분리하면 제 2정규형을 만족한다.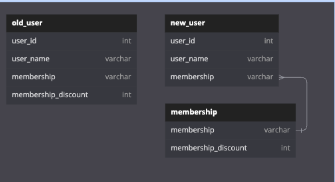
-
제 3정규형
A->B, B->C,일 때 A->C인 이항적 종속이 있으면 안된다.ex)유저에게 멤버십이 할당되어 있고, 멤버십 별로 할인율이 다를 때 할인율은 멤버십 등급에 종속된다. 이 때 멤버십 테이블로 분리하면 제 3정규형을 만족한다. -
정규화의 단점
정규화는 테이블을 쪼개는 연산이라서 조회, 삽입, 갱신 하는 경우 여러 테이블에 접근해야한다. 이러면 백엔드 로직이 복잡해질 수 있고, join 과 같은 연산으로 인해 쿼리 성능이 안좋아질 수 있다.
따라서 정규화는 반드시 해야하는 작업이라기 보다는 구현하고자 하는 서비스와 성능에 따라 타협하면 된다.
OLTP
Online Transaction Processing
-
온라인 트랜잭션 처리를 의미하며, 데이터베이스에 대한 insert, update, delete 작업을 처리하는 시스템. 위의 예시의 은행 계좌 이체 작업은 OLTP시스템에서 처리되는것.
데이터는 정규화된 스키마에 따라 저장
트랜잭션의 빠른 처리와 동시성 제어에 중점을 둔다 -
Row Oriented Processing : 행 단위로 처리. 간단하고 직관적이고 성능이 좋고 저장공간 효율적으로 활용 가능. 다차원 분석이나 집계, 대규모 데이터에는 적합하지 않다
OLAP
Online Analytical Processing
-
온라인 분석처리를 의미하며, 데이터베이스에 저장된 대량의 데이터를 분석, 보고하는 시스템. 주로 대규모 데이터셋을 분석하고 다차원적으로 데이터를 조직하여 사용자가 데이터를 이해하고 비즈니스 인텔리전스를 얻을 수 있도록 한다.
ex)
매출 분석: 특정 기간 동안의 매출 데이터를 분석하여 제품별, 지역별, 시간별 매출 추이를 파악합니다.
고객 분석: 고객 데이터를 분석하여 고객 성향, 구매 패턴, 인구 통계 정보 등을 파악합니다.
시장 분석: 시장 데이터를 분석하여 경쟁 환경, 시장 규모, 성장률 등을 파악합니다. -
데이터는 비정규화된 형태로 저장되며, 주로 읽기 작업이 많고 집계, 그룹화 및 다차원 분석을 수행하는 데 최적화 되어있다.
-
BigQuery, Redshift, Snowflake 등의 Data Warehouse 엔진이 OLAP에 속한다.
- Column Oriented Processing : 특정 column 단위로 처리. 각 column을 하나의 덩어리로 처리한다. 대용량으로 하기 좋은이유임. OLTP 보다 압축률이 훨씬 좋다. 쿼리속도 빠르다.(특정 컬럼만 보면 되기때문).
하지만 단점은 트랜잭션 연산은 느리다.(OLTP가 낫다) 애초에 빠른연산보다는 큰 데이터를 덩어리로 처리하는것에 최적화 되어 있다.
관계
-
ERD
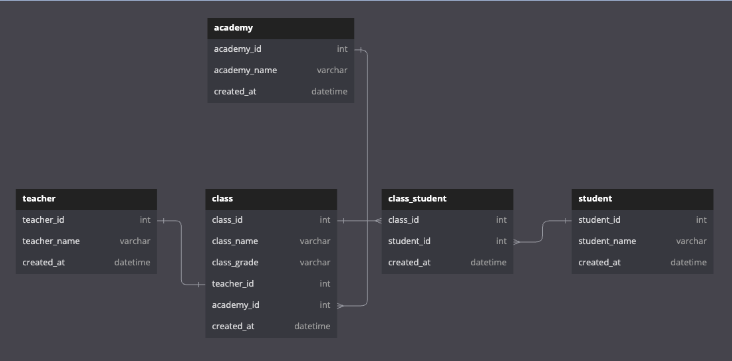
-
IE표기법

| : 1:1
---< : 1:N
>----< : N:M
A---OB : A가 B에 속할지 말지 선택. 0~N까지 가능
관계에 대한 이해는 SQL 실습을 통해 부딪혀 보면서 이해하면 된다.
NoSQL
-
문서 지향 데이터베이스(Document-Oriented Database)
관계 데이터베이스가 아닌, 데이터베이스에서 데이터를 조작하는 언어라고 이해하면된다. 일반적으로 NoSQL 성격의 데이터베이스 엔진을 말한다. 각 문서는 키-값 쌍으로 이루어져있다.
ex) MongoDB, Couchbase, CouchDB주로 대량의 분산 데이터 처리와 확장성을 위한 설계에 주로 사용된다.
장점 : 스키마유연성, 수평적 확장성, 고성능, 대용량 데이터 처리
대규모 웹 어플리케이션, 소셜네트워크, 실시간 분석 등의 다양한 분야에서 활용됨 -
키-값 저장소(Key-Value Store)
각 데이터를 고유한 키와 연관시켜 저장하는 데이터베이스. 간단한 조회 및 쓰기 작업에 적합하며, 대규모 분산 시스템에서 많이 사용됨.
ex) Redis, Amazon DynamoDB, Apache Ignite -
열 지향 데이터베이스(Column-Oriented Database)
행이 아닌 열 단위로 데이터를 저장하는 데이터베이스. 읽기 작업에 뛰어남
ex) Apache Cassandra, HBase, ScyllaDB -
그래프 데이터베이스(Graph Database)
데이터를 노드와 엣지의 그래프 형태로 저장하고 관리하는 데이터베이스
노드 = 개체, 엣지 = 노드사이의 관계
ex) Neo4j, Amazon Neptune, ArangoDB
NoSQL를 사용해야하는 이유
관계형 데이터베이스로 특정 서비스를 위한 데이터를 저장하기에는 비효율적일 수 있다.
예를들어 노션페이지, 인스타그램, 페이스북 같은 경우는 특정 유저에 대해 피드나, 친구들을 보여줘야하는데 조회를 할 때 한 사람을 기준으로 쭉 보여주게 된다. 그런데 그 친구들을 보여줄 때 마다 매번 join을 다 해서 쭉 붙여주는 작업을 해버리는 것 보다는 document형태로 그 사람 밑으로 다 붙여버리는게 낫다.
-> 서비스 특징에 따라 다르다는것이 이런 것.
