데이터 전처리는 머신러닝 모델의 성능 향상을 위한 필수 과정이다. 마치 요리 전에 재료 손질을 하는 것처럼, 정교한 전처리를 통해 모델의 정확도를 높이고 학습 시간을 단축할 수 있다.
Colab 환경에서 실습하기
파일을 구글 드라이브에 저장(혹은복사) -> .ipynb 파일 우클릭 -> open with colab 클릭
drive.mount('/content/drive')을 실행시키면 뭐가 뜨는데 다 확인 누르자
Path() 에 현재 .ipynb 파일이 있는 경로를 넣어준다
example_file = join(경로, 폴더명, 파일)
그 후 data = pd.read_csv(example_file)와 같은 방식으로 pandas 기능을 이용하여
csv 파일을 변수에 할당해서 사용하면 된다.
- TIP
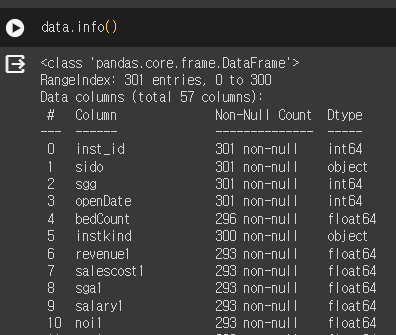
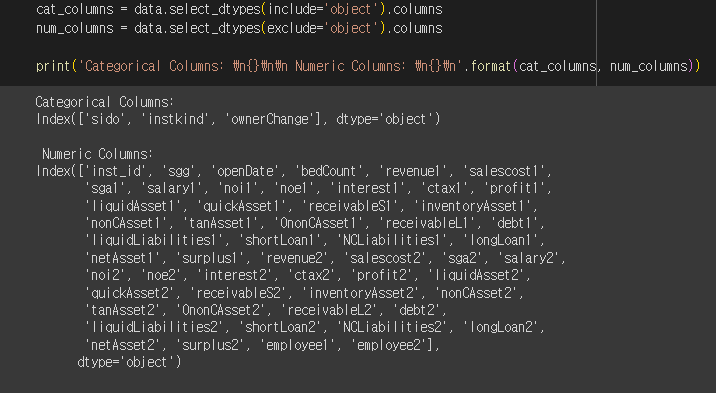
데이터 info를 봤을 때 Object type을 가진 컬럼은 모두 범주형 변수이기 때문에
범주형/ 수치형 데이터를 따로 쪼개놓는게 좋다.
Scaling
변수의 크기가 너무 작거나, 너무 큰 경우 해당 변수가 Target 에 미치는 영향력이 제대로 표현되지 않을 수 있습니다.
Sklearn의 대표적인 스케일링 함수로는 특정 변수의 최대, 최소 값으로 조절하는 Min-Max 스케일링과 z-정규화를 이용한 Standard 스케일링이 있습니다
1. Min-Max Scaling
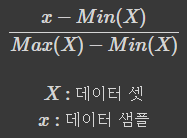
범위가 0~1사이로 변경된다. Skleran의 preprocessing 패키지에 있다.
- 모델 불러오기 및 정의하기
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()- 데이터에서 특징 찾기 (Min, Max값)
scaler.fit(numeric_data)- 데이터 변환
scaled_data = scaler.transform(numeric_data)
scaled_data = pd.DataFrame(scaled_data, columns=num_columns)scaler.data_max 결과
scaler.data_min 결과

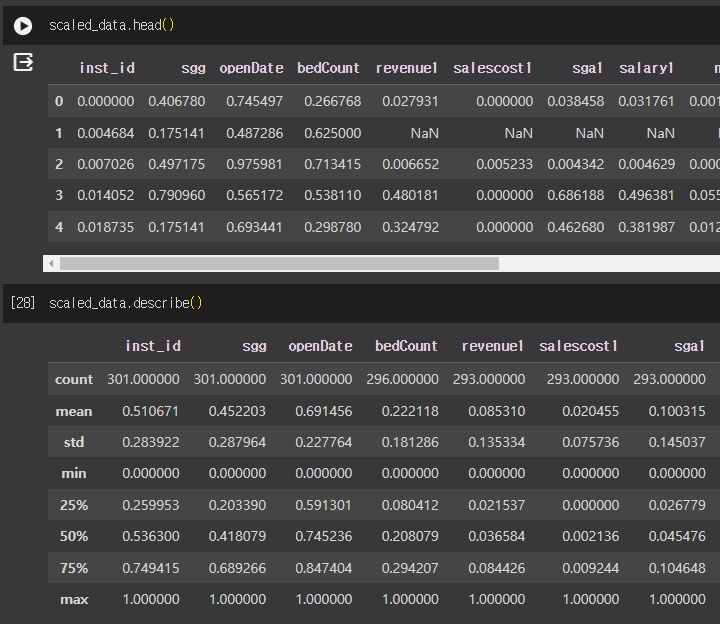
- 결과 살펴보기
ref) Scikit-learn Min-Max Scaler
2. Standard Scaling
 데이터를 통계적으로 표준정규분포화 시켜 스케일링 하는 방식. z-score정규화 라고도한다.
데이터의 평균이 0, 표준편차 1 되도록 스케일링
데이터를 통계적으로 표준정규분포화 시켜 스케일링 하는 방식. z-score정규화 라고도한다.
데이터의 평균이 0, 표준편차 1 되도록 스케일링
- 모델 불러오기 및 정의하기
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()- 데이터에서 특징 찾기 (Mean, Std값)
sacler.fit(numeric_data) - 데이터 변환
scaled_data = scaler.transform(numeric_data)
scaled_data = pd.DataFrame(scaled_data, columns=num_columns)- 결과 살펴보기
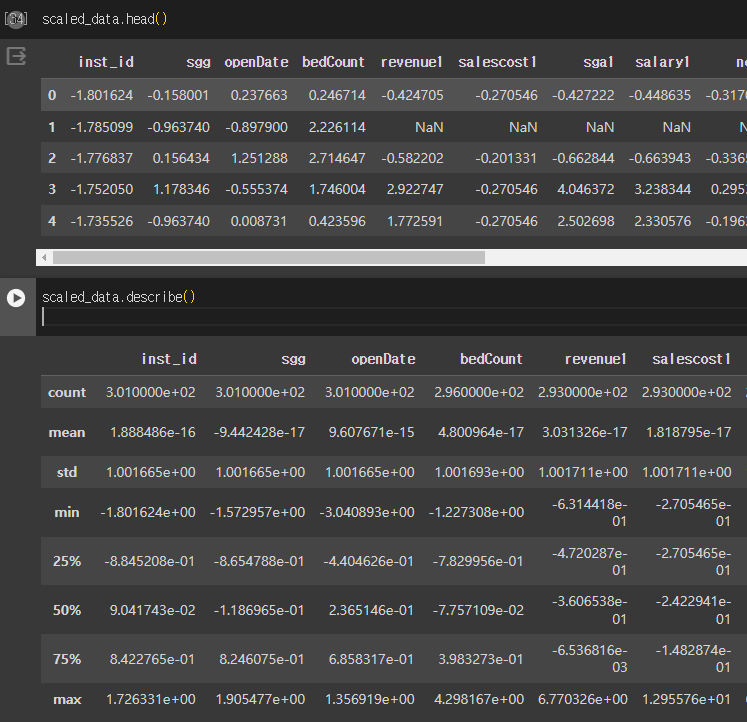
ref) Scikit-learn, Standard Scaler
💥 1.00234e-16 이 뭐지??
min 값을 보면 0이 나와야 하는데 이런 식으로 표현이 되어있다.
이유는 컴퓨터가 실수를 연산할 때 표현하는 방식 때문이다.
0과 1로 소수점을 표현하려다보니 오차가 발생하는 것이다.
실수 표현 방식은 2가지가 있다.
1. 고정 소수점 (fixed point) 방식
2. 부동 소수점 (floating point) 방식
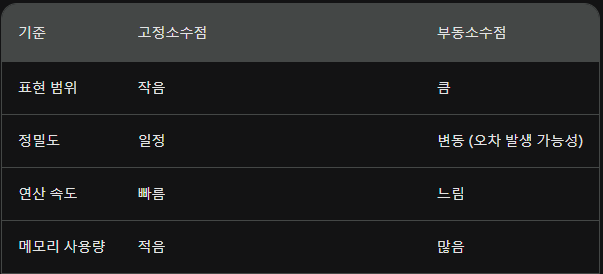
이 중에서도 python은 부동소수점 방식을 사용해서 오차때문에 이런식으로 표현된다는 정도만 알면 될 것 같다. 어쨌든 성능에 크게 영향을 주지 않는 0에 가까운 값이므로 괜찮다.
나중에 CS공부할 때 더 자세히 알아보자
3. Log Transformation
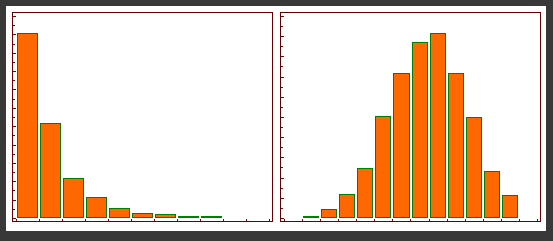
데이터가 치우친 분포(Skew)일 때 이를 보정해주는 방법.
로그 변환은 어떤 변수의 범위가 양수인 경우에만 사용할 수 있으며, 각 변수에 대해 자연로그를 취하는 연산이다.
그림처럼 치우쳐진 분포를 정규분포의 형태처럼 만들어 줄 수 있다.
- 로그변환 전
scaled_data['revenue2'].hist(bins=20)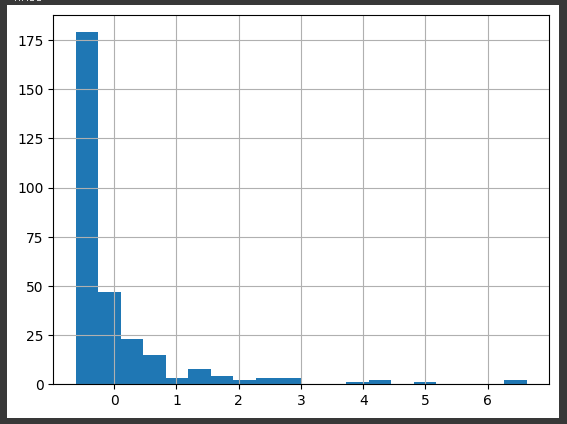
- 로그변환 후
scaled_data['log_revenue2'] = np.log1p(data['revenue2'])
scaled_data['log_revenue2'].hist(bins=50)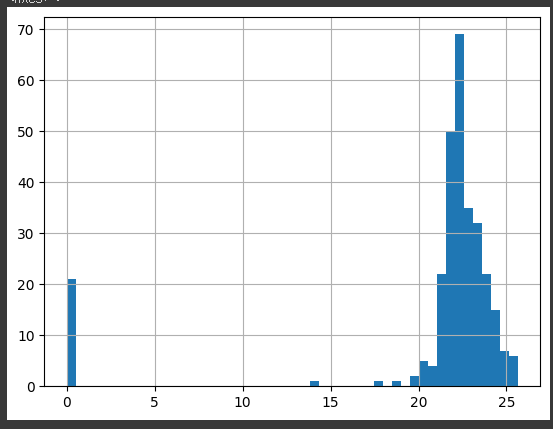
4. Box-Cox, Yeo-Johnson, Quantile Transformation
세 가지 변환 모두 치우친 분포의 데이터를 정규분포화 시켜주는 효과과 있는 변환방법
-
Box-cox : Log 변환처럼 양수에만 적용가능. Lambda값에 따라 변환이 달라지는데
Lambda = 0 일 경우 Log 변환과 동일하다. -
Yeo-Johnson : 음수에도 적용 가능
-
Quantile : 가장 자주 발생하는 값 주위로 분포를 조정하며, 이상치 영향을 감소시켜준다.
실습에 사용할 데이터 분포 확인scaled_data['revenue2'].hist(bins=40)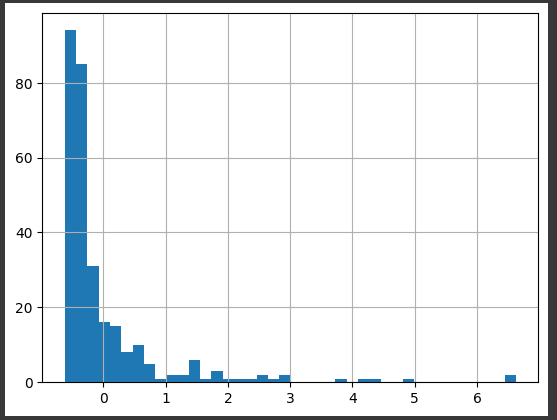
1. box-cox
from sklearn.preprocessing import PowerTransformer trans = PowerTransformer(method='box-cox') scaled_data['box_cox_revenue2'] = trans.fit_transform(scaled_data['revenue2'].values.reshape(-1, 1) + 1) scaled_data['box_cox_revenue2'].hist(bins=40) # reshape을 하는 이유 : sacled_data 의 shape이 (324,) 였다. # 뒤에 +1 한 이유 : box-cox는 양수에만 가능하므로 -1~0인 값이 존재해서 올려준것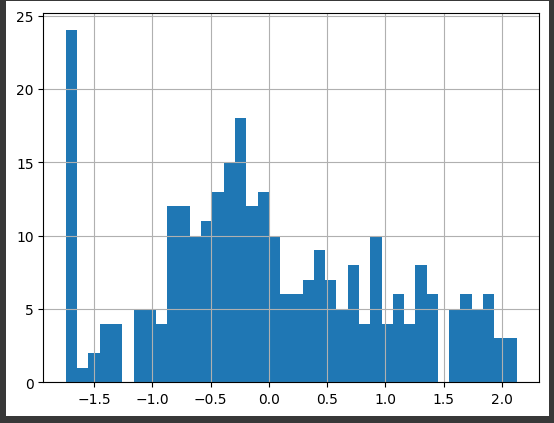
2. Yeo-johnson
from sklearn.preprocessing import PowerTransformer trans = PowerTransformer(method='yeo-johnson') scaled_data['yeo_johnson_revenue2'] = trans.fit_transform(scaled_data['revenue2'].values.reshape(-1, 1)) scaled_data['yeo_johnson_revenue2'].hist(bins=40)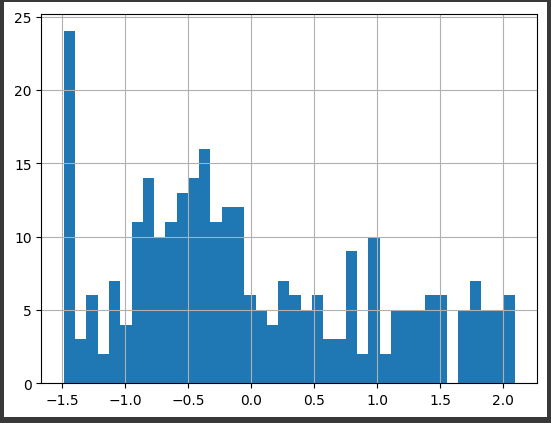
3. Quantile
from sklearn.preprocessing import QuantileTransformer trans = QuantileTransformer(output_distribution='normal') scaled_data['quantile_revenue2'] = trans.fit_transform(scaled_data['revenue2'].values.reshape(-1, 1)) scaled_data['quantile_revenue2'].hist(bins=40)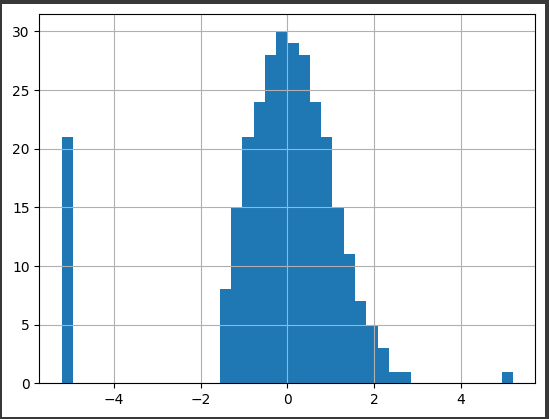
ref)
- Scikit-learn PowerTransformer, Box-Cox, Yeo-Johnson Transformation
- Scikit-learn Quantile Transformation
- Scikit-learn Map Data To Normal Dist
Imputation
대표 값을 사용한 결측치 처리
정형 데이터를 다루다보면, 값이 NaN(Not a Number or Null)으로 되어있는 경우가 있는데 이러한 값을 결측치라 하며,
가장 간단한 방법으로 평균이나 중간값 또는 최빈값 같은 변수의 대표값을 사용할 수 있다.
결측치를 확인하는 방법으로 Pandas의 isna() + sum() 메소드를 사용할 수 있다.
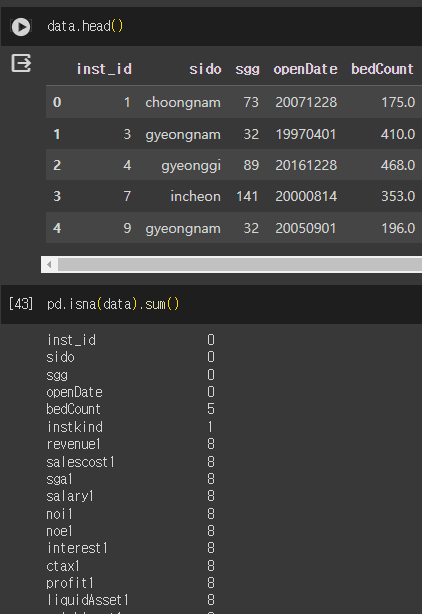
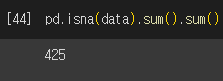
1. Mean(평균)
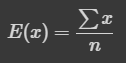
확률 이론과 통계 관점에서 (모)평균 또는 기댓값은 중심에 대한 경향성을 알 수 있는 척도입니다. 일반적으로 평균이라고 부르는 것으로 산술 평균이라고 하고, 이 평균은 표본 평균이라고도 합니다.
평균은 모든 관측치의 값을 모두 반영하므로 지나치게 작거나 큰 값(이상치)들의 영향을 많이 받게 됩니다.
평균은 모든 샘플의 값을 더하고, 샘플의 개수로 나누어 계산할 수 있습니다.
mean_df = data.copy() -> 원본데이터를 카피해서 사용하자
Scikit-learn에서 impute패키지의 SimpleImputer를 사용
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='mean')
imputer.fit(mean_df[num_columns])
mean_df[num_columns] = imputer.transform(mean_df[num_columns])결측치 제거 확인
pd.isna(mean_df[num_columns]).sum()
2. Median(중간값)
중간값은 데이터 샘플을 개수에 대해서 절반으로 나누는 위치의 값을 말합니다.
데이터 샘플의 수가 짝수개일 때에는 중간에 위치한 두 값의 평균을 사용합니다.
중간값은 모든 관측치의 값을 모두 반영하지 않으므로 지나치게 작거나 큰 값(이상치)들의 영향을 덜 받습니다.
중간값은 샘플을 값에 대해 정렬하고, 중앙에 위치한 값으로 구할 수 있습니다.
mdeina_df = data.copy()imputer = SimpleImputer(strategy='median')
imputer.fit(median_df[num_columns])
median_df[num_columns] = imputer.transform(median_df[num_columns])결측치 확인
pd.isna(median_df[num_columns]).sum()
3. Iterative Impute(R 언어의 MICE 패키지)
Round robin 방식으로 반복하여 결측값을 회귀하는 방식으로 결측치를 처리합니다.
결측값을 회귀하는 방식으로 처리하기 때문에 수치형 변수에만 적용할 수 있습니다.
-
각 결측치를 해당 변수의 평균으로 채워넣는다.
-
대체할 변수의 결측치는 제외한 상태로 해당 변수의 결측치를 회귀모델을 이용하여 예측한다.
-
다른 변수에서도 해당 방식을 반복한다.
-
모든 변수에 대해 반복 후 해당 이터레이션에서 맨 처음에 할당했던 값과의 차이를 계산한다.
-
해당 값의 차이가 0이 될 때(수렴)까지 반복한다.
impute_df = data.copy()from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
imp_mean = IterativeImputer(random_state=0)
impute_df[num_columns] = imp_mean.fit_transform(impute_df[num_columns])결측치 확인
pd.isna(impute_df[num_columns]).sum()
ref)
4. Mode(최빈값)
mode_df = data.copy()from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
imputer = SimpleImputer(strategy='most_frequent')
imputer.fit(mode_df[cat_columns])
mode_df[cat_columns] = imputer.transform(mode_df[cat_columns])pd.isna(mode_df[cat_columns]).sum()Categorical Variable to Numeric Variable
범주형 변수를 수치형 변수로 나타내는 방법
여기에서 범주형 변수란, 차의 등급을 나타내는 [소형, 중형, 대형] 처럼 표현되는 변수를 말합니다.
범주형 변수는 주로 데이터 상에서 문자열로 표현되는 경우가 많으며, 문자와 숫자가 매핑되는 형태로 표현되기도 합니다.
1. Label Encoding
라벨 인코딩은 n개의 범주형 데이터를 0~n-1 의 연속적인 수치 데이터로 표현합니다.
예를 들어, 차의 등급 변수를 라벨 인코딩으로 변환하면 다음과 같이 표현할 수 있습니다.
소형 : 0
중형 : 1
대형 : 2
라벨 인코딩은 간단한 방법이지만, '소형'과 '중형'이라는 범주형 데이터가 가지고 있는 차이가 0과 1의 수치적인 차이라는 의미가 아님을 주의하셔야 합니다.
Label Encoding과 Scikit-Learn의 preprocessing 패키지에 있습니다.
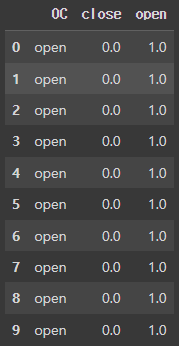
이번에는 병원 개/폐업 데이터의 target이었던, OC 변수를 수치형 변수로 변환하겠습니다.
data = pd.read_csv(example_file)
label = pd.DataFrame(data['OC'])
label.head()
- 모델 불러오기 및 정의하기
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()- 데이터에서 특징 찾기(범주의 수)
le.fit(label)
# classes_ 속성에 있는 순서(index)대로 라벨 번호가 부여됩니다.
le.classes_결과

- 데이터 변환(범주형변수 -> 수치형변수)
label_encoded = le.transform(label)- 결과 살펴보기
le_df = pd.DataFrame(label_encoded, columns = ['label_encoded'])
result = pd.concat([label, le_df], axis=1)
result.sort_values('label_encoded', inplace=True)
result.head(20)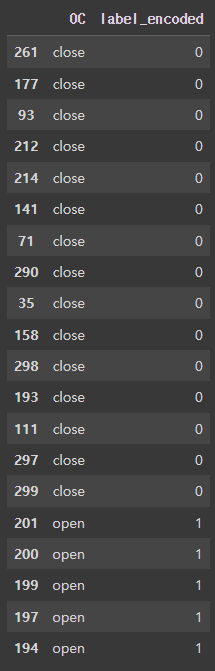
ref) Scikit-Learn Label Encoder
2. One-hot Encoding
원핫 인코딩은 n개의 범주형 데이터를 n개의 비트(0,1) 벡터로 표현합니다.
예를 들어, 위에서 언급한 소형, 중형, 대형으로 이루어진 범주형 변수를 원핫 인코딩을 통해 변환하면 다음과 같이 표현할 수 있습니다.
소형 : [1, 0, 0]
중형 : [0, 1, 0]
대형 : [0, 0, 1]
원핫 인코딩으로 범주형 데이터를 나타내게되면, 서로 다른 범주에 대해서는 벡터 내적을 취했을 때 내적 값이 0이 나오게 됩니다.
이는 서로 다른 범주 데이터는 독립적인 관계라는 것을 표현할 수 있게 됩니다.
One-hot Encoding은 Sklearn의 preprocessing 패키지에 있습니다.
Sklearn의 One-hot Encoder는 numpy 행렬로 입력을 넣어줘야 정상적으로 작동하므로, pandas DataFrame에서 numpy-array로 추출하여 사용합니다
컬럼이 아주 많은 데이터에 사용하면 차원의 저주 가 발생하여 모델 성능이 저하될 수 있다.
- 차원의 저주
데이터의 차원이 증가함에 따라 데이터 밀도가 감소하고, 이로 인해 머신러닝 모델의 성능이 저하되는 현상
- 모델 불러오기 및 정의하기
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(sparse=False) sparse=True가 디폴트이며 이는 Matrix를 반환한다.
원핫인코딩에서 필요한 것은 array이므로 sparse 옵션에 False를 넣어준다.
- 데이터에서 특징 찾기(범주의 수)
ohe.fit(label)- 데이터 변환(변주형변수 -> 수치형변수)
one_hot_encoded = ohe.transform(label)- 결과 살펴보기
ohe_df = pd.DataFrame(one_hot_encoded, columns = ohe.categories_[0]) # 뒤에 _는 transform 된 데이터들을 볼 때 사용
result = pd.concat([label, ohe_df], axis=1)
result.head(10)