Implicit Feedback 학습 개요
추천시스템 엔진 구축에 있어 대부분의 데이터는 유저와 아이템의 상호작용(click, purchase) 여부의 데이터만 존재할 수 있다. 이를 implicit feedback 이라 칭한다.
반대로 유저가 아이템에 매긴 직접적인 평가 점수(평점, 후기 등)를 explicit feedback 이라 칭하며 현실적으로 implicit feedback 대비 데이터를 구하기 어렵고 유저, 아이템 편향 및 신뢰도 확인 등 부가적인 정제 절차가 필요하다.
따라서 대부분의 추천시스템 엔진, 모델은 많은 경우 implicit feedback 데이터로 학습을 진행한다.
이 포스트는 이러한 implicit feedback 학습 시 필요한 Negative Sampling 기본적인 구현 방법을 다루며 속도를 높이는 것에 집중한다.
기본적인 네거티브 샘플링 기법
보통 추천시스템 딥러닝 학습 코드를 보면 미니배치를 돌 때마다 유저 번호를 확인하고, 그 유저의 history (interaction, session etc) 에 없는 아이템에서 뽑아온다.
# psuedo code for one user
import random
...
# in minibatch
neg_sample = []
while len(neg_sample) != n_negs:
neg_candidate = random.choice(total_items)
if neg_candidate not in user_history:
neg_sample.append(neg_candidate)
이 방법은 네거티브 샘플을 필요할 때에만 뽑음으로써 메모리를 가장 절약하여 사용할 수 있다.
하지만 매번 전체 아이템에서 하나씩 랜덤하게 뽑아 유저 히스토리에 포함되는지 일일이 확인하기 때문에 유저 히스토리 길이에 따라 시간이 들쭉날쭉하며, 파이썬 코드 상에선 전반적으로 매우 느리다.
Jagged Array 형태로 네거티브 샘플링 pool 유지 기법
네거티브 샘플링 풀은 유저별로 정해져 있으며, 이를 통해 유저별 네거티브 샘플 테이블을 구성하여 jagged array 형태로 저장해두면 이 array 에서 random.choices 혹은 random.sample 함수를 활용해 보다 빠르게 샘플링이 가능하다.
네거티브 샘플링 풀을 메모리에 띄우기 때문에 메모리 사용량은 늘어날 수 있다.
import pandas as pd
user_negatives = {}
# create user-negative jagged array with pandas.Series
user_positives = train_data.groupby('user_id')['item_id'].apply(set)
total_items = set(train_data['item_id'])
for u, pos_list in user.positives.items():
# neg sample pool per user
neg_set = total_item_set - pos_list
self.user_negatives[u] = list(neg_set)
user_negatives = pd.Serise(user_negatives)
...
neg_batch = self.user_negatives[user_ids].apply(
lambda neg_list: random.choices(neg_list, k=n_negs)
).tolist()
위와 같이 pandas 의 apply 함수를 통해서 jagged array 를 구성하고, 이후 리스트 인덱싱을 같이 활용해 다수 유저에 대한 빠른 네거티브 샘플링이 가능하다.
모델 구축 및 속도 비교
ml-latest-small 데이터셋을 SGD-MatrixFactorizaion 으로 학습하면서 두 방법의 속도 차이가 어느정도 나는지 확인해보자. pytorch를 활용하겠다.
해당 데이터셋은 600명의 유저와 9700개의 영화로 이루어져 있다. 총 인터렉션은 100,000개 이다.
valid_set 은 유저별 히스토리에서 랜덤하게 두 개씩 뽑아서 준비하였다.
import pandas as pd
ratings_df = pd.read_csv('data/ml-latest-small/ratings.csv')
ratings_df.sort_values(by=['userId', 'timestamp'], inplace=True)
valid_df = ratings_df.groupby('userId').sample(n=2, random_state=42)
train_df = ratings_df.drop(valid_df.index)
# cold-start items
len(set(valid_df['movieId']) - set(train_df['movieId']))
train_data = train_df[['user_idx', 'item_idx']]네거티브 샘플링은 미니배치의 유저별로 시행하며, pytorch dataloader의 collate_fn 인자를 활용해 미니배치 뽑을 때 옆에 붙여주는 형태를 취했다. RNSCollateFn1 클래스는 필요할 때 일일이 뽑는 샘플링이다.
class MlDataset(Dataset):
def __init__(self, train_data: pd.DataFrame):
self.duets = train_data.values
def __len__(self):
return self.duets.shape[0]
def __getitem__(self, index):
return self.duets[index]
class RNSCollateFn1:
def __init__(self, train_data: pd.DataFrame, n_negs: int):
self.train_data = train_data
self.total_items = train_data['item_idx'].unique()
self.n_negs = n_negs
def __call__(self, batch):
batch = np.array(batch)
neg_batch = []
for user_idx in batch[:, 0]:
neg_sample = []
user_positive = \
self.train_data[self.train_data['user_idx']==user_idx]\
['item_idx'].unique()
while len(neg_sample) != self.n_negs:
neg_candidate = random.choice(self.total_items)
if neg_candidate not in user_positive:
neg_sample.append(neg_candidate)
neg_batch.append(neg_sample)
neg_batch = np.array(neg_batch)
return torch.LongTensor(np.concatenate((batch, neg_batch), axis=1))
train_dataset = TrainDataset(train_data=train_data)
collate_fn = RNSCollateFn1(train_data, n_negs=5)
duet_dataloader = DataLoader(
dataset=train_dataset,
shuffle=True,
batch_size=4096,
collate_fn=collate_fn,
num_workers=4
)collate_fn 을 클래스로 구성한 이유는 미니배치 처리 시 train_data 를 통한 부가적인 데이터들을 collate 내부에서 만들고 관리하기 위함이다.
dataloader 가 iterate 할 때 마다 collate 함수를 포인터로써 호출하는데 __call__ 함수를 통해 클래스 객체가 함수처럼 동작하도록 디자인 할 수 있다.
SGD-MF 모델은 다음과 같이 간략히 구성하였고, BCE Loss 를 활용함으로써 SGD-MF 를 implicit feedback 을 통해 학습하는 형태로 디자인 하였다.
class MatrixFactorization(nn.Module):
def __init__(self, n_users, n_items, embedding_size):
super().__init__()
self.user_embedding = nn.Embedding(n_users, embedding_size)
self.item_embedding = nn.Embedding(n_items, embedding_size)
def forward(self, users, items):
user_embed = self.user_embedding(users)
item_embed = self.item_embedding(items)
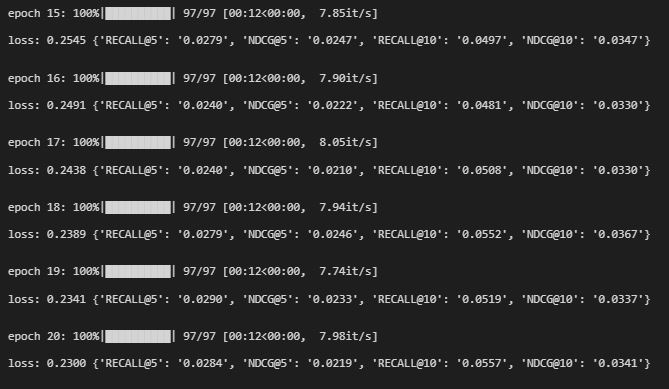
return torch.mul(user_embed, item_embed).sum(dim=1)배치사이즈 1024 기준 한 epoch당 12초 걸렸다. 네거티브 샘플링이 학습 프로세스보다 오래 걸린다.
네거티브 샘플링 풀을 구성하는 방식으로 collate_fn 을 교체해보자.
class RNSCollateFn2:
def __init__(self, train_data: pd.DataFrame, n_negs: int):
train_data = train_data[['user_idx', 'item_idx']]
user_positives = \
train_data.groupby('user_idx')['item_idx'].apply(set)
total_items_set = set(train_data['item_idx'].unique())
self.user_negatives = {}
for u, pos_list in user_positives.items():
neg_set = total_items_set - pos_list
self.user_negatives[u] = list(neg_set)
# for list-indexing
self.user_negatives = pd.Series(self.user_negatives)
self.n_negs = n_negs
def __call__(self, batch):
batch = np.array(batch)
neg_batch = np.array(self.user_negatives[batch[:, 0]].apply(
lambda neg_list: random.choices(neg_list, k=self.n_negs)
).tolist())
return torch.LongTensor(np.concatenate((batch, neg_batch), axis=1))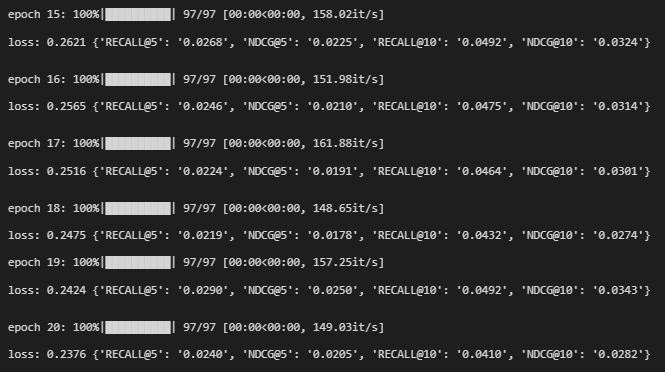
네거티브 샘플링 아이템 차이 때문에 매 에폭마다 metric 점수가 약간 낮지만 속도는 채 1초가 걸리지 않았다. epoch 을 늘리면 금방 위의 방법을 따라잡는다.
더 큰 데이터 셋으로 학습하면 시간 차이는 훨씬 더 크다. ml-1m 데이터셋은 기본 네거티브 샘플링 시간이 분 단위를 넘어가지만 개선 시 채 10초가 걸리지 않는다.
이 방법은 pytorch 딥러닝 모델 뿐만 아니라 각종 네거티브 샘플링이 필요한 모든 학습에서 응용할 수 있다.
